Comparación entre aprendizaje no supervisado y supervisado.

juanMoyano100
Posted on October 22, 2020

Se ha realizado una comparación entre el aprendizaje no supervisado y el supervisado aplicado al mismo problema, en este caso, clasificar vinos en distintas categorías mediante los atributos obtenidos en un análisis químico. Gracias a que es un problema de reconocimiento de patrones se utilizan redes neuronales. Para aprendizaje supervisado se utiliza el modelo de perceptrón multicapa o Multi-layer Perceptron (MLP) y para el aprendizaje no supervisado se utiliza un mapa autoorganizado o Self-Organizing MapsM (SOM), al final se realiza una comparación de los resultados.
Introducción
El razonamiento cognitivo en una computadora convencional puede resolver problemas mapeando, algunos ejemplos de estos podrían ser: el reconocimiento de patrones, la clasificación, el pronóstico, entre otros. Las redes neuronales artificiales proporcionan este tipo de modelos. Entre estos, gran parte del esfuerzo de investigación en redes neuronales se ha centrado en la clasificación de patrones. Las redes neuronales artificiales realizan tareas de clasificación de forma obvia y eficiente debido a su diseño estructural y sus métodos de aprendizaje.
No existe un algoritmo único para diseñar y entrenar modelos de redes neuronales porque, el algoritmo de aprendizaje difiere entre sí en su capacidad de aprendizaje y grado de inferencia. Por lo tanto, en esta ocasión, se trata de evaluar las reglas de aprendizaje supervisadas y no supervisadas y su eficiencia de clasificación utilizando ejemplos específicos.
Para el aprendizaje supervisado se utilizará el MultiLayer Perceptron (MLP), y para el no supervisado de utilizaran Self-Organization Maps (SOM).
Desarrollo
Este ejemplo ilustra cómo una red neuronal supervisada y no supervisada de reconocimiento de patrones puede clasificar los vinos por bodega en función de sus características químicas.
Información del Dataset
El dataset a usar fue obtenido de UCI Machine Learning Repository. Según el repositorio, estos datos son el resultado de un análisis químico de vinos cultivados en la misma región en Italia, pero derivados de tres variedades diferentes. El análisis determinó las cantidades de 13 componentes encontrados en cada uno de los tres tipos de vinos. El primer atributo es el identificador de clase (1–3). El problema planteado consiste en clasificar los vinos.
Se intenta construir una red neuronal que pueda clasificar los vinos por trece atributos:
- Alcohol
- Ácido málico
- Ceniza
- Alcalinidad de cenizas
- Magnesio
- Fenoles totales
- Flavonoides
- Fenoles no flavonoides
- Proantocianidinas
- Intensidad de color
- Matiz
- OD280 / OD315 de vinos diluidos
- Prolina
Este es un ejemplo de un problema de reconocimiento de patrones, donde las entradas están asociadas con diferentes clases, y se quiere crear una red neuronal que no solo clasifique los vinos conocidos correctamente, sino que pueda generalizar para clasificar con precisión los vinos que no se utilizaron para diseñar la solución.
Hay tres "categorías" de vino diferentes y el objetivo será clasificar un vino sin etiquetar de acuerdo con sus características, como el contenido de alcohol, el sabor, el matiz, etc.
Modelo
Las redes neuronales son muy buenas en problemas de reconocimiento de patrones. Una red neuronal con suficientes elementos (llamados neuronas) puede clasificar cualquier información con precisión arbitraria. Son particularmente adecuados para problemas complejos de límites de decisión sobre muchas variables. Por lo tanto, las redes neuronales son un buen candidato para resolver el problema de clasificación del vino.
Los trece atributos de vecindad actuarán como entradas a una red neuronal, y el objetivo respectivo para cada uno será un vector de clase de 3 elementos con un número en la posición de la bodega asociada, # 1, # 2 o # 3.
La red se diseñará utilizando los atributos de los vecindarios para entrenar a la red para producir las clases objetivo correctas.
Aprendizaje supervisado
El aprendizaje supervisado se basa en entrenar una muestra de datos de la fuente de datos con la clasificación correcta ya asignada. Para este ejemplo se utilizará MultiLayer Perceptron (MLP). Por lo tanto, se debe conocer que tres distintivos característicos:
- Una o más capas de neuronas ocultas que no forman parte de las capas de entrada o salida de la red que permiten a la red aprender y resolver problemas complejos.
- La no linealidad reflejada en la actividad neuronal es diferenciable y,
- El modelo de interconexión de la red presenta un alto grado de conectividad.
El algoritmo de aprendizaje de corrección de errores entrena la red en base a las muestras de entrada-salida y encuentra la señal de error.
El paradigma de aprendizaje supervisado es eficiente y encuentra soluciones a varios problemas lineales y no lineales, tales como clasificación, control de plantas, pronóstico, predicción, robótica, etc.
Aprendizaje no supervisado
Las redes neuronales autoorganizadas aprenden utilizando un algoritmo de aprendizaje no supervisado para identificar patrones ocultos en datos de entrada no etiquetados. Esto sin supervisión se refiere a la capacidad de aprender y organizar información sin proporcionar una señal de error para evaluar la solución potencial.
Las características principales de los Mapas autoorganizados (SOM) son:
- Transforma un patrón de señal entrante de dimensiones arbitrarias en un mapa bidimensional y realizar esta transformación de forma adaptativa.
- La red representa la estructura de avance con una sola capa computacional que consiste en neuronas dispuestas en filas y columnas.
- En cada etapa de representación, cada señal de entrada se mantiene en su contexto adecuado y,
- Las neuronas que tratan con piezas de información estrechamente relacionadas están juntas y se comunican a través de conexiones sinápticas.
El algoritmo no supervisado en SOM funciona en tres fases: Fase de competencia, fase cooperativa y fase adaptativa.
El modelo autoorganizado representa naturalmente el comportamiento neurobiológico y, por lo tanto, se utiliza en muchas aplicaciones del mundo real, como la agrupación, el reconocimiento de voz, la segmentación de texturas, la codificación de vectores, etc.
Comparación entre aprendizaje supervisado y no supervisado.
 Tabla 1. Comparación entre aprendizaje supervisado y no supervisado.
Tabla 1. Comparación entre aprendizaje supervisado y no supervisado.
Como se puede ver en la tabla 1, existen semejanzas y diferencias entre estos dos aprendizajes, por ejemplo, en el aprendizaje supervisado, el "supervisor" actúa como una guía para enseñarle al algoritmo qué conclusiones o predicciones debería llegar.
En el aprendizaje no supervisado, no hay una respuesta correcta, no hay un maestro, los algoritmos se dejan solos.
El modelo de aprendizaje supervisado utilizará los datos de capacitación para aprender un vínculo entre la entrada y las salidas. El aprendizaje no supervisado no utiliza datos de salida. En el aprendizaje no supervisado, no habrá ningún conocimiento previo etiquetado, mientras que en el aprendizaje supervisado tendrá acceso a las etiquetas y tendrá conocimiento previo sobre los conjuntos de datos. La idea del aprendizaje supervisado es que la capacitación se pueda generalizar y que el modelo se pueda utilizar en nuevos datos con cierta precisión.
EXPERIMENTACIÓN
Se utiliza la plataforma de Orange para realizar el las redes neuronales de aprendizaje supervisado y no supervisado.
Se puede observar que todos los atributos del dataset son numéricos, (o así lo interpreta Orange), para este caso se puede cambiar el atributo "Class" a Categorical, para así poder clasificar los vinos por su categoría. Cabe recalcar que aun, en numéricos también funcionan los modelos planteados.
 Figura 1. Atributos del dataset.Aprendizaje supervisado (MLP).
Figura 1. Atributos del dataset.Aprendizaje supervisado (MLP).
Como se puede observar en la figura 1, todos los atributos están colocados como feature, los cuales serán los pesos o entradas, para los modelos. Para el caso del aprendizaje no supervisado, es necesario una variable objetivo, posteriormente se elegirá a el atributo "Class label" como variable objetivo.
 Figura 2. Modelo utilizado para aprendizaje supervisado.
Figura 2. Modelo utilizado para aprendizaje supervisado.
Para realizar las predicciones se utilizó el perceptrón multicapa representado como "Neutral Network" en la figura 2. Posteriormente, se realizaron las respectivas representaciones y evaluaciones de las predicciones.
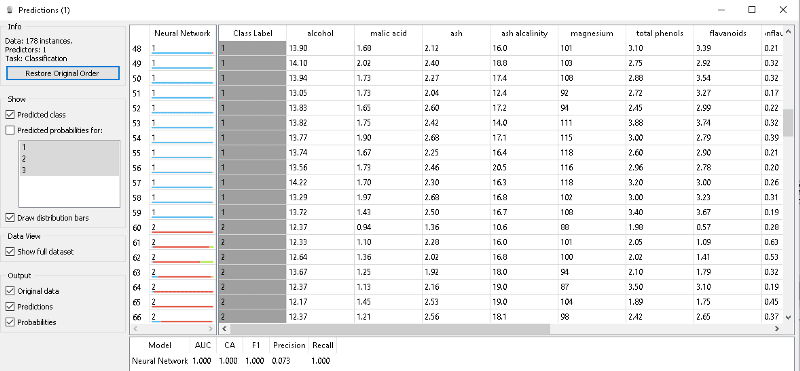 Figura 3. Predicciones modelo MLP
Figura 3. Predicciones modelo MLP
En la figura 3, se pueden observar los valores predichos por la red neuronal, y se puede verificar que los valores en la mayoría de los casos son similares a los valores de la variable objetivo. Esto se debe a que el modelo tiene los siguientes parámetros obtenidos en la evaluación.
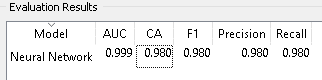 Figura 4. Resultados de evaluación modelo MLP.
Figura 4. Resultados de evaluación modelo MLP.
En la figura 4, se muestran los valores obtenidos en la evaluación, cada uno representa lo siguiente:
- El área bajo ROC(AUC) es el área bajo la curva de operación del receptor.
- La precisión de clasificación es la proporción de ejemplos correctamente clasificados.
- F-1 es una media armónica ponderada de precisión y recuperación.
- La precisión es la proporción de verdaderos positivos entre las instancias clasificadas como positivas, p.
- La recuperación es la proporción de verdaderos positivos entre todas las instancias positivas en los datos, p.
Y por último en la figura 5, se representa la matriz de confusión obtenida de los valores que el modelo predijo con respecto a los ingresados como datos de entrada y la variable objetivo.
 Figura 5. Matriz de confusión.
Figura 5. Matriz de confusión.
Se puede observar que todos los valores fueron clasificados correctamente, esto quiere decir que el modelo planteado funciona correctamente y los valores, esto quiere decir que se ha generado un modelo para predecir el tipo de vino dependiendo de sus atributos químicos, es decir, si se ingresara un nuevo conjunto de datos diferente a los ya ingresados se puede hacer una predicción del tipo de vino.
Aprendizaje no supervisado (SOM)
Gracias a Orange el proceso para realizar este modelo es bastante sencillo, solo basta con unir los datos con el mapa auto organizado y Orange se encarga del resto como se muestra en la figura 6.
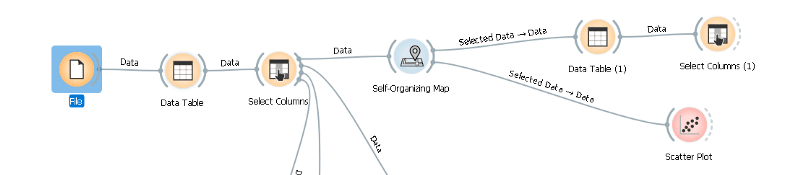 Figura 6. Modelo utilizado aprendizaje no supervisado.
Figura 6. Modelo utilizado aprendizaje no supervisado.
Todo lo utilizado en el modelo anteriormente mencionado, es necesario para representar gráficamente los datos y revisar que valores son los que a obtenido con el aprendizaje.
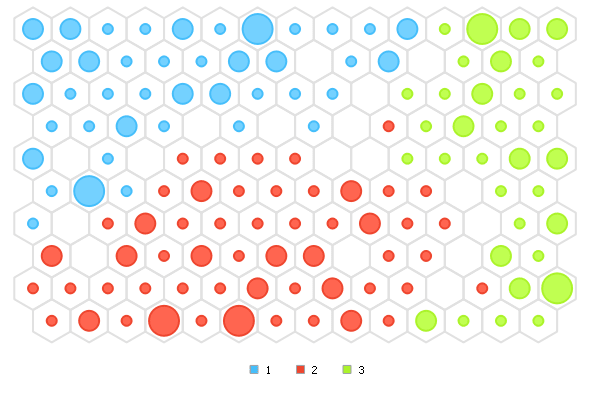 Figura 7. Mapa auto organizado completo.
Figura 7. Mapa auto organizado completo.
En la figura anterior, se ven representadas las categorías por un color, al momento de ingresar los datos, solo se enviaron los datos de entrada, mas no la función objetivo, al final de todas las variables enviadas, se puede seleccionar una para representarla en el mapa, y en este caso se seleccionó la clase para poder comparar con el modelo utilizado anteriormente.
 Figura 8. Selección de categorías por grupo.
Figura 8. Selección de categorías por grupo.
Para poder verificar que los valores generados con los mapas autoorganizados son correctos, seleccionamos manualmente por grupos para posteriormente compararlos con los que se muestran en los de entrada en el atributo "Class".
Figura 9. Predicciones modelo SOM.
Se puede confirmar que en su gran mayoría los datos clasificados por el mapa autoorganizado son los mismos o bastante parecidos.
A continuación, se comprarán gráficamente los resultados de los datos ingresados, los obtenidos por el aprendizaje supervisado y por el no supervisado.
Figura 10. Grafica atributo de clasificación (a) Datos "Class label" (b)MLP (c)SOM
En la figura 10a están representados por colores los valores de clasificación, estos son los mismos que se utilizarán como variable objetivo en el aprendizaje supervisado MLP, para realizar las predicciones.
Al realizar las predicciones se clasificaron de manera similar como se puede observar en la figura 10b, en la cual están graficados los valores predichos por el modelo multicapa, se puede apreciar que la tendencia grafica es prácticamente la misma, con unas pequeñas variaciones, y por último en la figura 10c, en la cual se representan los grupos generados por el mapa autoorganizado, donde también se puede apreciar la misma tendencia de los grupos con respecto a la variable de clasificación.
CONCLUSIONES
La elección de utilizar un algoritmo de aprendizaje automático supervisado o no supervisado generalmente depende de factores relacionados con la estructura y el volumen de sus datos y el caso de uso. En realidad, la mayoría de las veces, los científicos de datos utilizan juntos los enfoques de Aprendizaje supervisado y Aprendizaje no supervisado para resolver el caso de uso.
Para el correcto funcionamiento de los dos modelos es necesario un buen planteamiento, debido a que, gracias a esto, se podría realizar el aprendizaje de cualquier tipo de problema que se desee. En ambos casos el resultado fue similar, lo que quiere decir que, simplemente depende de como se plantee el problema, cabe recalcar que no todos los problemas van a ser adaptables al igual que este ejemplo, en algunos casos será mas eficaz aplicar un supervisado y en otros el aprendizaje no supervisado.
Posted on October 22, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related