
joseph
Posted on September 17, 2020

Let's look at building a twitter bot that scrapes information from one part of the web and then spits it out on twitter. There are a few good examples if you want to generate ideas for a twitter bot such as @bbcbweaking, @poemexe and my own @rnghaiku. In this example we will write something that simply finds the first dev.to post and tweets the title.
Requirements:
- Python
- Text editor
- Browser
- Patience
Before we write even a line of code we need to download two incredibly powerful modules namely: beautifulsoup and tweepy. Beautifulsoup will handle the webscraping and tweepy will handle the twitter API requests.
Webscraping
Webscraping is one of the most powerful tools that a coder has and it's the first thing I look to do in each language that I touch. we will be using beautifulsoup for this and you can install it from your terminal with the following:
pip install beautifulsoup4
Create a new .py document and add the following lines to the top in order to import all the functions that beautifulsoup (which I will refer to now as bs4) has for us:
import requests
from bs4 import BeautifulSoup
You now need to define the page you want bs4 to open which you can do like this:
page = reqeusts.get("http://dev.to")
soup = BeautifulSoup(page.content, "html.parser")
In order to test that bs4 is doing it's job you can simply print the content of this page to see what we have
print(soup)
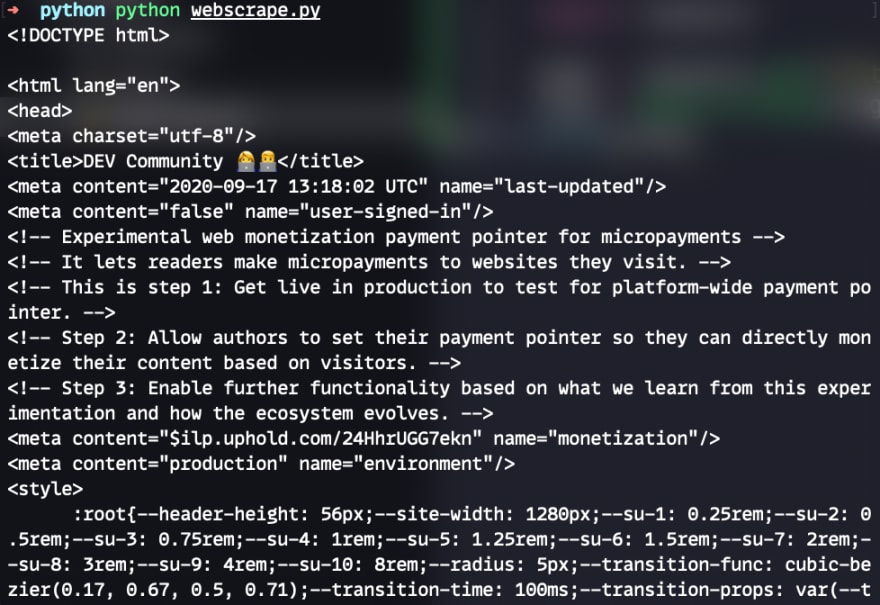
Now we are loading ALL the html from the dev.to which is neither readable nor tweetable. We now need to refine our search using the built in "find" function from bs4. In order to find the titles of each post we need to dive into the HTML of dev.to. We can do this by either reading all the HTML (boring, long, painful) or simply use your favourite web browser to do the same.


We can see in the DOM above that each title is buried under several HTML classes and ids. In order to get to these we're going to have to dig through the elements in order to return an array of titles. We can do it like this and I will explain later:
from bs4 import BeautifulSoup
import requests
page = requests.get("http://dev.to")
soup = BeautifulSoup(page.content, "html.parser")
home = soup.find(class_="articles-list crayons-layout__content")
posts = home.find_all(class_="crayons-story__indentation")
for post in posts:
title = post.find("h2", class_="crayons-story__title")
print(title.text.strip())
Now lets go through each line of code in order.
page = requests.get("http://dev.to")
soup = BeautifulSoup(page.content, "html.parser")
These open the HTML page and returns the result as a bs4.BeautifulSoup object. We can then find objects within this soup of HTML with the following:
home = soup.find(class_="articles-list crayons-layout__content")
posts = home.find_all(class_="crayons-story__indentation")
If you look at the DOM above the red coloured section refers to everything inside the "home" variable and the posts is everything inside the green. The posts is now an array (or a bs4.element.ResultSet) that we can iterate through as follows
for post in posts:
title = post.find("h2", class_="crayons-story__title")
print(title.text.strip())
For every post in the list of posts we search for the h2 with the class of crayons-story__title and print the stripped title for it. This is the purple section of the highlighted DOM. If everything goes correctly you should see a list of posts like this:
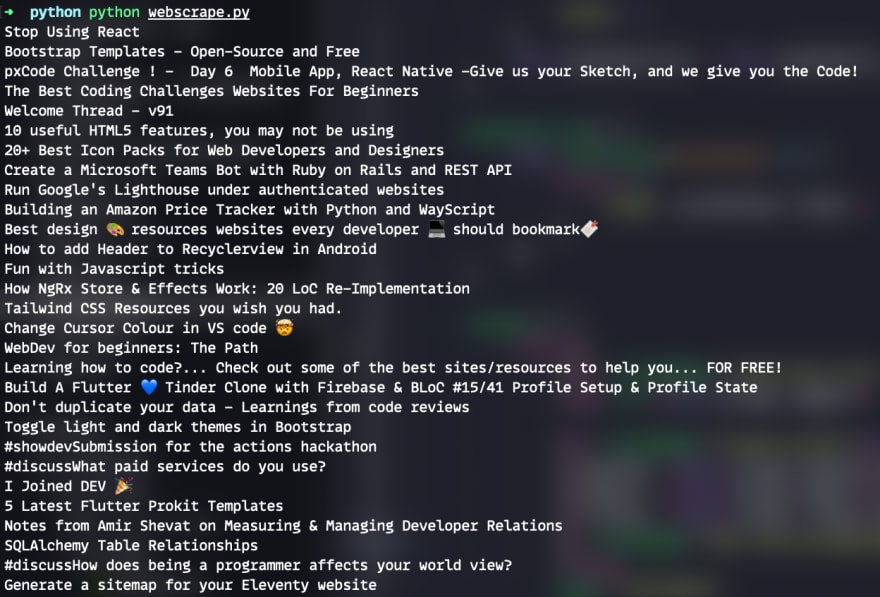
But obviously we only want the first one of these so we can just do the following:
top_post = posts[0].find("h2", class_="crayons-story__title").text.strip()
Which in my case returns the Stop Using React post. For selecting other elements such as <a href="foo"> tags please check out this tutorial from compjour.
Anyway now we have something that we want to tweet (which can be any string or even images) we can now look at tweeting.
Tweeting
For this we will use tweepy whose documentation is equally as strong and useful as bs4's and I recommend that you check out. Install in the usual way:
pip install tweepy
and on the top of your python document don't forget to include tweepy
import tweepy
and now we need to set up a twitter app for your bot to operate in. You can do this by going here and creating an app and filling in the simple form, confirm your email then you will have to wait for your developer application to be confirmed. In the meantime, before we get our API keys, we can do some more work on the tweet we want to send.
from bs4 import BeautifulSoup
import tweepy
import requests
def scrape():
page = requests.get("http://dev.to")
soup = BeautifulSoup(page.content, "html.parser")
home = soup.find(class_="articles-list crayons-layout__content")
posts = home.find_all(class_="crayons-story__indention")
top_post = posts[0].find("h2", class_="crayons-story__title").text.strip()
tweet(top_post)
def tweet(top_post):
consumer_key = "#"
consumer_secret = "#"
access_token = "#"
access_token_secret = "#"
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)
api.update_status(top_post)
scrape()
There's a lot going on here so let's slowly go through it. The tweet function that we wrote will take one argument of 'top post' which is what we figured out in the scrape section. The consumer_key, consumer_secret, access_token and access_token_secret are all API keys provided to us by twitter and should be some long, unreadable string. To learn what these tokens actually do I would recommend that you check out the tweepy documentation.
Once you receive the email confirming your API keys be sure to copy them into your function so they function as expected.
Once all of this has been completed we can host our bot on AWS or my personal recommendation heroku. For a good guide on hosting a bot on heroku please check out this great article from data_bae. Now just run your app and let's see what you get!





I, of course, advocate using React as I have the hopes of getting a job in Berlin where React is dominating the job market so I will have some explaining to do in my twitter later.
If you have any questions about this article or my bad syntax please message me at @jsphwllng
Posted on September 17, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related


