ServiceNow and OpenAI

John Vitor Constant Lourenco
Posted on February 26, 2024

Overview
Creating a chat completion is an easy task, but if you need to ride with context it can become a complex task.
In this guide I will show you an easy way to create a chat completion on Servicenow consuming the OpenAI endpoint without losing de context of comments of the task.
What you'll learn:
- How to consume the OpenAI endpoint using the Servicenow
- How to not loose task comments context in chat completion
What you'll need to know:
- Javascript
- Script includes
- Bussiness rules
- Outbound REST Messages
- Table and form creation
Creating REST Message
-
Let's start creating the REST Messages
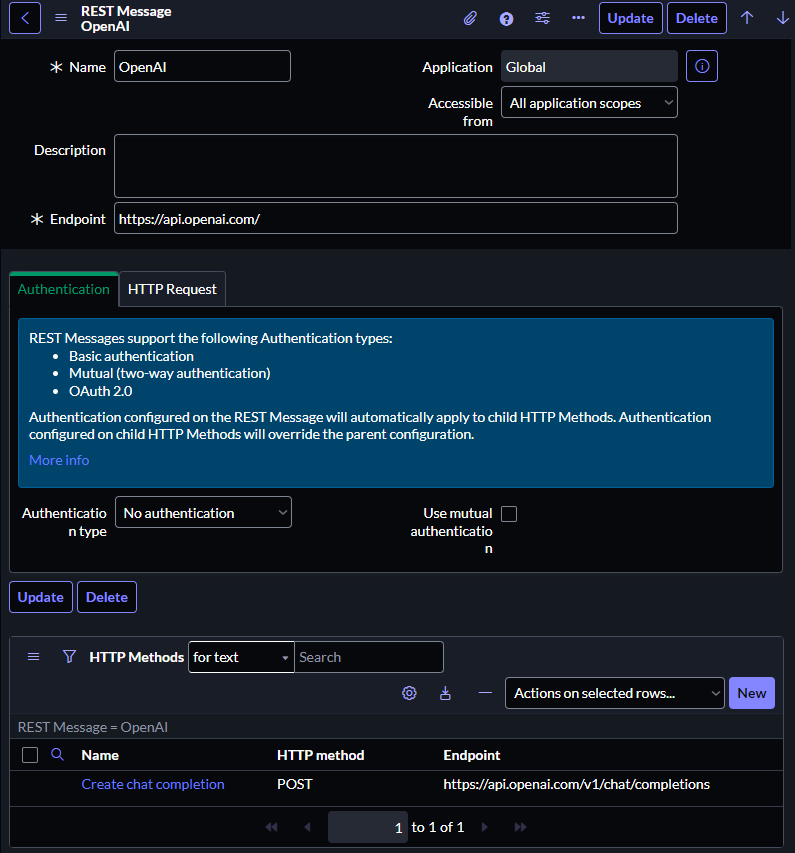
- Open the table REST Messages[sys_rest_message]
- New Record
- Name: OpenAI
- Endpoint: https://api.openai.com/
- Save
-
Then create a new HTTP Method in the related List:
- Name: Create chat completion
- HTTP method: POST
- Authentication type: No authentication (because we will pass auth parameters on request headers)
- HTTP Headers (Name/Value):
- Authorization: Bearer ${token}
-
Content-Type: application/json
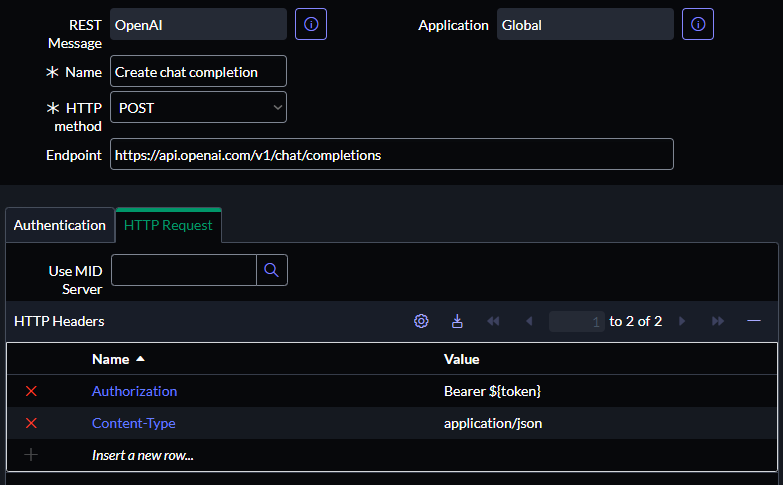
- Content:
{ "model": "gpt-3.5-turbo", "temperature": 1, "stream": false, "messages": [ { "role": "system", "content": "You are a helpful assistant" }, { "role": "user", "content": "What is Caesar cipher" } ] }
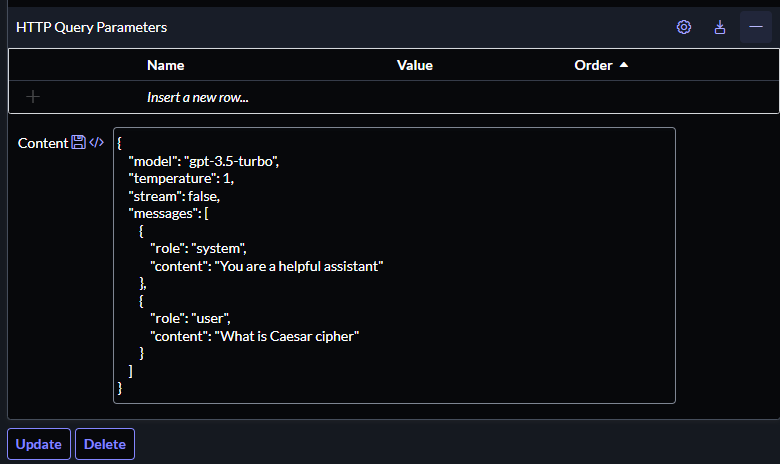
- Variable Substitutions (Related list)
- Name: token
- Escape type: No escaping
- Test value: your OpenAI token
Then click on Test and verify if it works.
Saving OpenAI credentials
We ill use api_key_credentials table to save our OpenAI token
- Create a new Record on api_key_credentials
- Name: OpenAI
- API Key: your OpenAI token
Creating OpenAI table
Now we will create a table to save all Requests sent to OpenAI endpoint.
OpenAI completion endpoint give us a json like this:
{
"id": "chatcmpl-8feVV3Y9dngfD793tUwLzJCsnuFWi",
"object": "chat.completion",
"created": 1704937849,
"model": "gpt-3.5-turbo-0613",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Caesar cipher is a simple form of substitution cipher where each letter in the plaintext is shifted a certain number of positions down or up the alphabet. For example, a shift of 3 would mean that A becomes D, B becomes E, and so on. The cipher is named after Julius Caesar, who allegedly used it to communicate secret messages."
},
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 20,
"completion_tokens": 69,
"total_tokens": 89
},
"system_fingerprint": null
}
Then we will create a table with these fields to handle the response and do additional things (like save which Task record and user called this REST endpoint:
- Table Fields:
- u_http_status_code: String
- u_model: String
- u_temperature: Integer
- u_last_input: String
- u_raw_input: String
- u_id: String
- u_object: String
- u_created: Integer
- u_raw_output: String
- u_output_content: String
- u_prompt_tokens: Integer
- u_completion_tokens: Integer
- u_total_tokens: Integer
- u_finish_reason: String
- u_estimated_prompt_token: Integer
- u_cost: Decimal
- u_gliderecord: Reference
- u_user: Reference
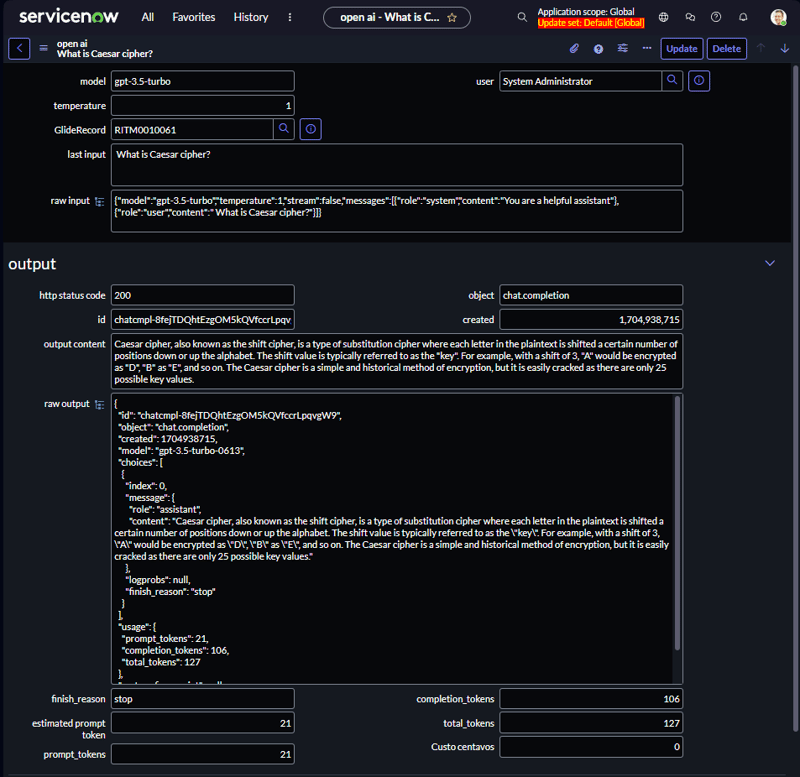
Creating script include
Now we need to create script include
- Name: global.OpenAI
var OpenAI = Class.create();
OpenAI.prototype = {
initialize: function() {
var gr = new GlideRecord("api_key_credentials");
gr.addQuery("name", "OpenAI");
gr.setLimit(1);
gr.query();
gr.next();
this.key = gr.api_key.getDecryptedValue();
},
createChatCompletion: function(input, record, alternativePrompt, customModel, customTemperature) {
var req = record || '';
var prompt = alternativePrompt || "You are a helpful assistant";
var model = customModel || "gpt-3.5-turbo";
var temperature = customTemperature || 1;
var messages = [{
"role": "system",
"content": prompt
}, ];
if (typeof(input) == 'object') {
for (var i = 0; i < input.length; i++) {
messages.push({
"role": input[i].role,
"content": input[i].content,
});
}
} else {
messages.push({
"role": "user",
"content": input,
});
}
var response;
var httpStatus;
var responseBody;
try {
var r = new sn_ws.RESTMessageV2('OpenAI', 'Create chat completion');
r.setStringParameterNoEscape('token', this.key);
var body = {
"model": model,
"temperature": temperature,
"stream": false,
"messages": messages
};
r.setRequestBody(JSON.stringify(body));
response = r.execute();
httpStatus = response.getStatusCode();
responseBody = response.getBody();
var responseBodyObj = JSON.parse(responseBody);
var gr = new GlideRecord('u_open_ai');
var lastInput = messages[messages.length - 1].content;
gr.initialize();
gr.setValue('u_raw_input', JSON.stringify(body));
gr.setValue('u_estimated_prompt_token', this.getTokenEstimate(body));
gr.setValue('u_raw_output', responseBody.toString());
gr.setValue('u_gliderecord', req);
gr.setValue('u_last_input', lastInput);
gr.setValue('u_user', gs.getUser().getID());
gr.setValue('u_http_status_code', httpStatus);
gr.insert();
return {
'responseBody': responseBody,
'httpStatus': httpStatus,
'content': responseBodyObj.choices[0].message.content
};
} catch (ex) {
return {
'responseBody': responseBody,
'httpStatus': httpStatus,
};
}
},
getTokenEstimate: function(obj) {
function countTokens(str) {
return str.split(' ').length +
str.split(/[^a-zA-Z0-9]/).length;
}
return obj.messages
.map(function(message) {
return countTokens(message.content);
})
.reduce(function(a, b) {
return a + b;
}, 0);
},
createChatCompletionToString: function(input, record, alternativePrompt, customModel, customTemperature) {
return JSON.stringify(this.createChatCompletion(input, record, alternativePrompt, customModel, customTemperature));
},
type: 'OpenAI'
};
Now let's look at what each code block do:
initialize: function() {
var gr = new GlideRecord("api_key_credentials");
gr.addQuery("name", "OpenAI");
gr.setLimit(1);
gr.query();
gr.next();
this.key = gr.api_key.getDecryptedValue();
},
In function initialize we retrieve the OpenAI key and decrypt it in execution time. WARNING! Depending on your instance configuration, roles, and Application, you will need to change how you retrieve this key. Another option is to save the key into a System Property variable and retrieve it using gs.getProperty(); (But I don't like this approach because you'll save your key in a raw text)
createChatCompletion: function(input, record, alternativePrompt, customModel, customTemperature) {
var req = record || '';
var prompt = alternativePrompt || "You are a helpful assistant";
var model = customModel || "gpt-3.5-turbo";
var temperature = customTemperature || 1;
var messages = [{
"role": "system",
"content": prompt
},];
if (typeof(input) == 'object') {
for (var i = 0; i < input.length; i++) {
messages.push({
"role": input[i].role,
"content": input[i].content,
});
}
} else {
messages.push({
"role": "user",
"content": input,
});
}
},
In this function we create a chat completion using these parameters:
- input: Is the input string or message object array. Input string can be used to get a simple answer from GPT, and message obejct array can be used to create a complex multi-turn request for GPT
- record (optional): Is GlideRecord which called this function, this parameter is created only to associate the request with the document.
- alternativePrompt (optional): We can change the default prompt using this parameter;
- customModel (optional): As name says, if you want to change the default model, use this parameter;
- customTemperature (optional): As name says, if you want to change the default Temperature, use this parameter; This initial part of code initialize the default parameters to sendto OpenAI endpoint, and check if input is string or message array object, if input is a string, the code convert to message array object to send to OpenAI completion endpoint.
var response;
var httpStatus;
var responseBody;
try {
var r = new sn_ws.RESTMessageV2('OpenAI', 'Create chat completion');
r.setStringParameterNoEscape('token', this.key);
var body = {
"model": model,
"temperature": temperature,
"stream": false,
"messages": messages
};
r.setRequestBody(JSON.stringify(body));
response = r.execute();
httpStatus = response.getStatusCode();
responseBody = response.getBody();
var responseBodyObj = JSON.parse(responseBody);
var gr = new GlideRecord('u_open_ai');
var lastInput = messages[messages.length - 1].content;
gr.initialize();
gr.setValue('u_raw_input', JSON.stringify(body));
gr.setValue('u_estimated_prompt_token', this.getTokenEstimate(body));
gr.setValue('u_raw_output', responseBody.toString());
gr.setValue('u_gliderecord', req);
gr.setValue('u_last_input', lastInput);
gr.setValue('u_user', gs.getUser().getID());
gr.setValue('u_http_status_code', httpStatus);
gr.insert();
return {
'responseBody': responseBody,
'httpStatus': httpStatus,
'content': responseBodyObj.choices[0].message.content
};
} catch (ex) {
return {
'responseBody': responseBody,
'httpStatus': httpStatus,
};
}
},
This part of code initializes de variables to create a POST request to OpenAI completion endpoint, then do a POST. After that we save the request response to u_open_ai table (How it is saved changes depending on the http status code)
Optional:
getTokenEstimate: function(obj) {
function countTokens(str) {
return str.split(' ').length +
str.split(/[^a-zA-Z0-9]/).length;
}
return obj.messages
.map(function(message) {
return countTokens(message.content);
})
.reduce(function(a, b) {
return a + b;
}, 0);
},
This function try to estimate how many token message array object will consume. This will be useful when we start to deal with very large context window (context larger than gpt can handle 16k+ for gpt-3.5-turbo-0125 or 128k+ for gpt-4-0125-preview).
Next steps:
- How to call this function from GlideRecord forms such as Incident, Requested Item or Change Request
- How to handle with very large context window (I will use the "recursive summary" approach).
- How to consume internal databases like Knowledge Bases or E-mails using embeddings clusterization and search.
- EXTRA: How to use the GeminiAI from Google.
Posted on February 26, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related