DadosJusBr: Go ou Python a serviço da cidadania.

Joeberth Souza
Posted on September 10, 2020

PT-BR
DadosJusBr: Go e Python a serviço da cidadania.
Você já tentou acessar dados em sites de órgãos públicos?
No Brasil, a Lei Federal 12.527/2011, ou mais comumente conhecida como Lei de Acesso à Informação (LAI), diz que é “obrigatória a divulgação em sítios oficiais da rede mundial de computadores (internet)” dos dados de gastos públicos.
Porém, a LAI pouco diz sobre a forma como esses dados devem ser disponibilizados. Por isso, nos sites dos órgãos são encontrados arquivos em diversos formatos (pdf, html, planilhas eletrônicas, json e etc), além disso nomenclaturas e formatação são muitas vezes diferentes para cada órgão.
Devido a essas características realizar um controle social e financeiro sobre essa enorme quantidade de dados de gastos públicos é uma tarefa difícil para uma pessoa.
Nesse ponto, o DadosJusBr surge com o objetivo de denunciar e libertar esses dados, apresentar de forma detalhada, organizada e unificada os dados de gastos com remuneração dos órgãos que constituem o sistema de justiça brasileiro, assim facilitando o acesso e promovendo o controle social sobre esses gastos do poder judiciário, ministério público, defensoria pública e procuradorias.
O DadosJusBr utiliza a inteligência de dados para a ação cidadã, promovendo um acesso mais democrático e fácil aos dados de remuneração do sistema de justiça brasileiro. No DadosJusBr podemos entender como cada juiz, promotor e desembargador são remunerados. Quais auxílios recebem? Quais os valores destes auxílios? Quanto além do salário um funcionário recebeu em determinado mês? Quanto um órgão gastou em determinado mês? Todas essas perguntas podem ser respondidas através do DadosJusBr.
Sim, até aqui tudo bem, Mas como é o processo?
Considerando o contexto do DadosJusBr, onde o executor é capaz de definir, configurar e executar um pipeline, que por sua vez é uma sequência de estágios onde a saída de um estágio é a entrada do próximo. Este pipeline é capaz de atingir a tarefa de libertação de dados do sistema judiciário brasileiro tem os seguintes estágios:
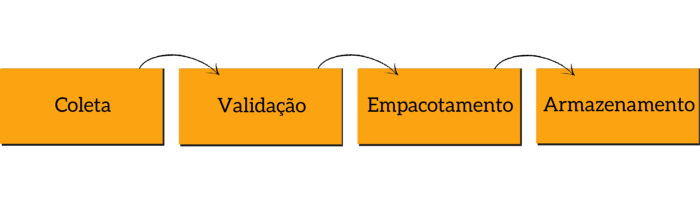
Pipeline DadosJusBR
- Coleta: Etapa responsável por encontrar, fazer o download dos arquivos e consolidar/traduzir as informações para um formato único do DadosJusBr;
- Validação: Responsável por fazer validações nos dados de acordo a cada contexto;
- Empacotamento: Responsável por padronizar os dados no formato de datapackages;
- Armazenamento: Responsável por armazenar os dados extraídos, além de versionar também os artefatos baixados e gerados durante a coleta;
Cada programa capaz de cumprir um estágio é dockerizado, ou seja, escrito de forma capaz de ser executado pela ferramenta docker, com os comandos “docker build”(que constrói uma imagem a partir das especificações definidas) e “docker run”(que executa essa imagem em um container). A dockerização nos permite codificar os coletores em diferentes linguagens, no caso do DadosJusBr, coletores em Golang e Python são aceitos.

Construção e execução do Pipeline DadosJusBR
No Pipeline, cada estágio, exceto o primeiro, recebe a saída padrão do estágio anterior, essa é uma forma de compartilharem informações. Também podemos definir um estágio chamado ErrorHandler, que será construído e executado quando ocorrer um erro no fluxo padrão. Consideramos como fluxo padrão a sequência de estágios descrita na definição do pipeline.

Compartilhamento de informações dentro do Pipeline DadosJusBR
Com esse conhecimento, é possível executar todos os estágios do pipeline do executor do DadosJusBr, adicionando as variáveis de ambiente o mês, ano e coletores que queremos realizar o processo.
Parte do texto foi extraído da postagem de Lorena, disponível no link. Todo o trabalho envolvido no processo foi desenvolvido pelos integrantes da organização DadosJusBr.
Para mais detalhes, dúvidas ou sugestões você também pode consultar o código completo do tutorial em: https://github.com/dadosjusbr/executor/tree/master/tutorial e/ou entrar em contato via e-mail: dadosjusbr@gmail.com.
Posted on September 10, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related
