Refactoring code reused across multiple teams

Jennie
Posted on March 20, 2024
The tech debt
I found an interesting ticket concerns about a legacy domain component being reused across 4 teams by importing source code path and coping necessary logic because
- The copied logic lied in other domain is not under my team’s maintenance.
- Applying updates requires more efforts.
- Importing source code path works in the current mono-repo setup temporary. But it may break easily if the package published without source code or changed internal path.
- The code was not designed for reuse at all.
It was not hard to guess the major cause of the ticket is the limit of resource - a norm of a fast developing tech company. It becomes a tech debt and the complexity grew rapidly. Devs started to alter the copied logic for their needs, and more teams follow the efficient copy over way that worked.
Eventually, we need much more context to ensure the quality than the time it created to pay back the debt.
My team never feel the pain as before adding any new stuffs there, no extra works for the team. Teams reused these code didn‘t feel the pain as they avoid the long waiting from my team and get things delivered quickly. Util one “lucky” developer feel the pain and decided to cut it off.
Well, I was lucky enough to become that person and here is some notes and thoughts for such case.
The refactor
Preparations
There were a lot of challenges for a refactor like this, including:
- Limit of resources - Completing the refactor will take long as we have to deal with other higher priority stuff.
- Wide impact range - Every change has risks to cause incident all over the place.
- Lack of code context - No one in the team knows the part of code well.
- Questionable testing coverage - There was decent unit test coverage but almost no e2e coverage. As refactor changes implementation, unit tests often become invalid. Hence no guarantees of things work as expected after refactoring.
Base on these challenges I identified some necessary preparations, like:
- Break the task down into the granularity that could fit both the development and review works into our tight schedule.
- Instead of changing any exisiting business logic code, create new and migrate one by one.
- Learn the code well before jumping in.
- Fill the test coverage gap before any changes.
- Pair with the teams for the migration.
The plan
Based on all the information and conditions, I tried to create small frequent iterations that could get delivered in a few days and resilient of interruptions from higher priority works.
I formed a rough plan in my head:
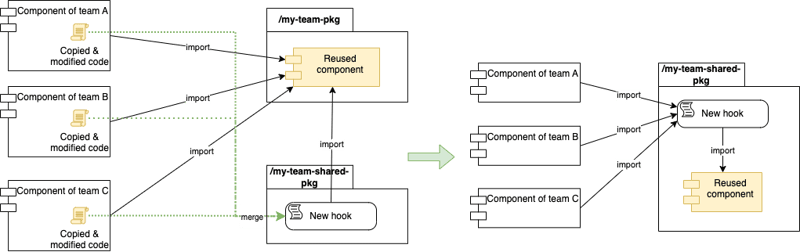
1. Move the reused files into a shared package
Ideally moving the reused files shall be done at the last step to ensure a smooth and gradually transition like the diagram above. However, the effort of creating the new reusable hook was too large to fit in the schedule, and completing the migration could span across several months. Therefore, I decided to bring this piece of work up front that takes relatively short time and increase the awareness of the reused attribute of this component.
2. Make small clean ups
Reducing unnecessary properties, states and callbacks are very helpful in the start of the refactoring work. These small clean ups are not only helping to reduce the complexity of refactoring and the following up migration, but also helping me to understand the implementation and usage.
3. Create a new encapsulation
There were a few duplicated and modified code sitting within the host components. To reduce the redundancy, and to avoid modifying exisiting logic and causing incidents everywhere, creating a new encapsulation was a better choice. The new encapsulation may reuse any existing code and extend the logic while not affecting anyone before fully tested and migrated.
It ends up to be a new hook allowing the hosts to control the component, and exposing some necessary states.
4. Migrate usage to the new encapsulation one by one
With the new hook ready and tested. I can finally help the hosts to import the new hook, and clean up the copied and modified logic.
5. Final clean up
For a smooth migration, I may create some intermediate stuff. After the complete migration, these code would only cause confusion. This last step was to clean up and reduce the possible confusion.
The actual work carried out
Before starting touching the code, I only created 4 tickets and added more during the actual work.
With the rough understanding of the code and plans, I reached out to a Front-end developers from one of the 4 teams. Unsurprisingly, importing our source code from the private space and maintaining the duplicated messy logic was not his concern, but initializing the extra Redux state in their domain was. This was completely out of scope and I promised to take a look later.
As planned, I moved the related code to a shared package first. To reduce the impact scope, I relocated the source code but keep the original path and export everything from the new place. The change took only few days but the code review took weeks thanks to the long list of the files.
The next piece of work started at 4 months later. Without writing down the plan, I almost forgot what I wanted to do. Luckily, my brain picked up quickly after scanning through the related code.
I started with removing a prop that could retrieve from the another prop instead, and making another prop more generic.
Then I happily discovered a piece of my work done in this 4 months gap removed a blocker of retiring the necessary Redux state. And I did it. The clean up was huge but straightforward enough to demand relatively small efforts from each team to review and merge.
Next, I created a new encapsulation but went a longer way as the long iteration span made me forgot my initial plan again 🙈 . Furthermore, I found a block of complex logic in the reused code that only required in the inspections list. As a result, I created an intermediate implementation to help the transition.
I thought I am ready to start the migration with the intermediate hook. Soon I realize it was not good enough when I tried migrating. Therefore, another better hook was born based on the learnings from the failure trail. The new hook required minimal code and provides intuitive and only essential callbacks for the host component to implement.
When I finally get back on the track of migration, the new hook that I was confident about crashed a page. Interestingly, it was neither a bug in the new hook nor in the host component of that page. It was an implementation in the hook could not work well with the host component. To resolve this, I adjusted the implementation of the hook one more time.
Eventually, I created 3 more small PRs and migrated everywhere except the most complicated one, and I got pulled into another high priority feature development expecting months of effort.
My mistakes
There were various mistakes I made:
Planed in head. Since the time span for the project took very long, I kept forgetting my initial plan and spent extra time to recompose one. This could be avoided if I wrote them down.
Created large PRs that was possible to break down. The PR I created for relocating files, retiring Redux state was large. These PRs were possible to break down for a safer transition, but I didn’t figure it out.
Breaking down PRs with little conflicts requires lots of planning ahead as it has to ensure everything works as expected with the small subset of changes. While the large PRs, could contain incomplete changes and polish later util reach the point of perfection.
Although more planning effort required, I really love the quick feedback loop of the small PRs. The reviewer were happy to review and verify the change in a few hours. Furthermore, my confidence of the deployment was higher as the quality of a small scope were easier to guarantee. Additionally, the maintenance effort before merging is much lower as it gets merge quicker, and the conflict range of each PR is small.
Simple migrations didn’t inform all the stakeholders in advance. Engineers love to surprise reviewers with the PRs without having a proper conversation in advance. I am one of them. After the first and only conversation with one team that I found little value, I skip the other conversations. Thankfully everything works well so far. But this has to be corrected as this is how this tech debt started and I tried to avoid.
Other take aways
Pace it slow is not a bad thing. As mentioned above, I had a 4 months gap between the first and second piece of work. During this gap, a blocker of the Redux store pain point was removed in a non-related task. What an existing surprise! Sometimes the problem goes away after a while.
Break the tech debts task down to minimal is the key of delivering when resource is precious. Other than the fast feedback loop, the higher quality confidence, and the less maintenance overhead mentioned above. It was easy to find a chance between the high priority job since each subtask took up to 3 days of initial work. More over, the small scope of the subtask makes it less overwhelming to drop and pick up after a while.
Complexity of patching tests across domain is very high and may not worth the effort. To ensure the quality, it is better to have complete test coverage before refactoring in theory (I did so before and it worked really well). While in reality, the complexity of crossing the domains doubles or even triples the effort that may not worth the value created. Thus, in this refactoring, I chose to rely on the existing tests and doing more manual tests to help speeding up the process. Meanwhile, in the test of the host components, I mocked my component and hook to reduce the testing overhead.
After thoughts
Although large refactor was satisfying, I would rather it never happen. However, this is inevitable if an app keeps growing after some time. Then how can we make things better and easier when before reaching that point or avoid it happen?
First of all, follow the good practices whenever possible. For example, creating components or functions, classes that take care of (little but not too little) logic about the same feature, same category. This practice maximizes the reusability of the code, make them flexible enough for composing in different cases.
Secondly, refactor often and small. Overtime, good practices change, meanwhile our knowledge grows and the “flawless” design reveals flaws. If we continuously tweaking the code to reduce the flaws, it might never grow into a big refactor.
Next, remember if we want to reuse other team's code, discuss with the code owner first to gain some context and make short to long term actionable plans together. It seems take more time initially but speeds everything up after.
Lastly, if we want to prevent tech debts like this and help others to reuse our code, we may consider:
- Open a public channel for others reaching out. Sometimes people gave up discussion because they didn’t find a easy way.
- Define standards for the sharing code so that everyone could follow and make it easy to find. The simplest thing we could do is clarify where to put the shared files especially in a mono-repo structure.
- Assist proactively. Helping the developer to understand the context, review the design and code takes time in a short-term but ensure things go well and causing less headache in a long run.
Posted on March 20, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.