
JayReddy
Posted on February 3, 2022
Learn how to convert a nested JSON file into a DataFrame/table
Handling Semi-Structured data like JSON can be challenging sometimes, especially when dealing with web responses where we get HTTP responses in JSON format or when a client decides to transfer the data in JSON format to achieve optimal performance by marshaling data over the wire.
The business requirement might demand the incoming JSON data to be stored in tabular format for efficient querying.
This blog post is intended to demonstrate how to flatten JSON to tabular data and save it in desired file format.
This use-case can also be solved by using the JOLT tool that has some advanced features to handle JSON.
Let's start digging by importing the required packages.
Required imports:
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.functions.col
import org.apache.spark.sql.types.{ArrayType, StructType}
import scala.io.Source
Sample nested JSON file,
val nestedJSON ="""{
"Total_value": 3,
"Topic": "Example",
"values": [
{
"value1": "#example1",
"points": [
[
"123",
"156"
]
],
"properties": {
"date": "12-04-19",
"model": "Model example 1"
}
},
{"value2": "#example2",
"points": [
[
"124",
"157"
]
],
"properties": {
"date": "12-05-19",
"model": "Model example 2"
}
}
]
}"""
step 1: Read inline JSON file as Dataframe to perform transformations on the input data.
we are using the sparks createDataset method to read the data with tight dependency on the schema.
Dataset is a strongly typed collection of objects that are domain-specific, datasets offer the flexibility to transform the domain-specific objects in parallel using functional operations.
val flattenDF = spark.read.json(spark.createDataset(nestedJSON :: Nil))
step 2: read the DataFrame fields through schema and extract field names by mapping over the fields,
val fields = df.schema.fields
val fieldNames = fields.map(x => x.name)
step 3: iterate over field indices to get all values and types, and explode the JSON file. Run pattern matching to output our data.
we explode columns based on data types like ArrayType or StructType.
for (i <- fields.indices) {
val field = fields(i)
val fieldName = field.name
val fieldtype = field.dataType
fieldtype match {
case aType: ArrayType =>
val firstFieldName = fieldName
val fieldNamesExcludingArrayType = fieldNames.filter(_ != firstFieldName)
val explodeFieldNames = fieldNamesExcludingArrayType ++ Array(s"explode_outer($firstFieldName) as $firstFieldName")
val explodedDf = df.selectExpr(explodeFieldNames: _*)
return flattenDataframe(explodedDf)
case sType: StructType =>
val childFieldnames = sType.fieldNames.map(childname => fieldName + "." + childname)
val newfieldNames = fieldNames.filter(_ != fieldName) ++ childFieldnames
val renamedcols = newfieldNames.map(x => (col(x.toString()).as(x.toString().replace(".", "_").replace("$", "_").replace("__", "_").replace(" ", "").replace("-", ""))))
val explodedf = df.select(renamedcols: _*)
return flattenDataframe(explodedf)
case _ =>
}
}
Complete Code:
object json_to_scala_faltten {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("json-to-parquet").master("local[4]").getOrCreate()
import spark.implicits._
val flattenDF = spark.read.json(spark.createDataset(nestedJSON :: Nil))
def flattenDF(df: DataFrame): DataFrame = {
val fields = df.schema.fields
val fieldNames = fields.map(x => x.name)
for (i <- fields.indices) {
val field = fields(i)
val fieldtype = field.dataType
val fieldName = field.name
fieldtype match {
case aType: ArrayType =>
val firstFieldName = fieldName
val fieldNamesExcludingArrayType = fieldNames.filter(_ != firstFieldName)
val explodeFieldNames = fieldNamesExcludingArrayType ++ Array(s"explode_outer($firstFieldName) as $firstFieldName")
val explodedDf = df.selectExpr(explodeFieldNames: _*)
return flattenDF(explodedDf)
case sType: StructType =>
val childFieldnames = sType.fieldNames.map(childname => fieldName + "." + childname)
val newfieldNames = fieldNames.filter(_ != fieldName) ++ childFieldnames
val renamedcols = newfieldNames.map(x => (col(x.toString()).as(x.toString().replace(".", "_").replace("$", "_").replace("__", "_").replace(" ", "").replace("-", ""))))
val explodedf = df.select(renamedcols: _*)
return flattenDF(explodedf)
case _ =>
}
}
df
}
val FDF = flattenDataframe(flattenDF)
FDF.show()
FDF.write.format("formatType").save("/path/filename")
}
}
Output:
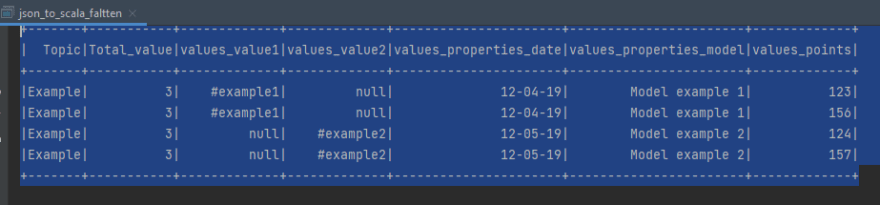
Conclusion:
Semi-Structured Data is challenging to work with when you are getting the data in nested form. Hopefully, this post gives you an overview of how to perform a simple ETL on JSON data. You can make modifications to the logic and find out more about how to get the desired results.
References:
https://github.com/bazaarvoice/jolt/releases
https://spark.apache.org/docs/latest/sql-data-sources-json.html
Posted on February 3, 2022
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.