Web Scraping with NodeJS

Tech Dog
Posted on March 7, 2021

>> Introduction
Recently I have came across a need of monitoring stock status of a product on a website(Trying to help my wife to buy Jellycat toys). They don't have an in-stock notification on their official website so I was trying to build a simple product stock notification app using nodejs.
As a lot of websites don't have a public API to work with, after my research, I found that web scraping is my best option.
There are quite some web scraping libraries out there for nodejs such as Jsdom , Cheerio and Pupperteer etc. (web scraing tools in NodeJs). In short, there are 2 types of web scraping tools:
1. DOM Parser
2. Headless Browser
If you want to know more about different web scraping tools, please refer to the link above. But essentially, Headless Browser enables more possibilities interacting with dynamic web content which is a better fit for my purpose and Pupperteer is a Node library which provides a high-level API to control headless Chrome over the DevTools Protocol.
>> Prerequisties
The following knowledge will better help you to better understand the following content.
1. Background in Javascript and HTML
2. Understanding of DOM
3. Understanding of NodeJS
>> Project Scope
The idea of this application is simple: make a concurrent request to the destination URL and parse the response information for the data that contains stock status and stock level of a particular product. If the product is in stock, it will send me an email to notify me.
>> Project Setup
Please ensure you have Node and npm installed on your machine. I would recommand to use any LTS Node version greater than 10.
We will be using the following packages:
- Pupperteer - Chrome headless browser
- Nodemailer - send email notification
There will be a certain level of project setup for better code reuse and readability. I referenced my project struture from this post (How to Scrape a Website Using Nodejs and Puppeteer) but it was optional.
>> Environment Setup
Create a node project and install all required dependencies using the following commands:
mkdir web_scraping
cd web_scraping
npm init -y
npm install pupperteer nodemailer
>> Application Entry
I would like to start by discussing the overall design of the application before going into the details.
index.js is the main entry of the application. await needs to be wrapped inside async function so normally I would like to have a mainEntry async function that contains all the logics and run that async function.
mainEntry function creates a headless browser and launches a page to the desired URL. When the page is loaded, scrapper will be applied to scrape for useful information and return back to the main application. Once mainEntry receives the response data, the node mailer will be used to send an email regarding the stock info. The mainEntry function is then put into setInterval function to be executed every 5 mins in this case.
//index.js
const dateLog = require('./logger');
const browser = require('./browser');
const mailer = require('./mailer');
const scraperController = require('./pageController');
dateLog('JellyCat in-stock tracker');
const REQUEST_INTERVAL = 60000*5;
let browserInstance = browser.launchBrowser();
let mailerInstance = mailer.createMailer();
//store response data
let data = null;
async function mainEntry() {
// Pass the browser instance to the scraper controller
data = await scraperController(browserInstance);
console.log(data.barl2br);
let date = new Date().toISOString();
//construct email text content
let resultText =
`${date} Product Code :BARL2BR Stock Status: ${JSON.stringify(data.barl2br.lead_text_summary)} Stock Level: ${JSON.stringify(data.barl2br.stock_level)} \n`;
let title = (JSON.stringify(data.barl2br.lead_text_summary) == 'In stock')?
'Product In Stock!!!':'JellyCat Stock';
let mailOptions = {
from: 'source email address',
to: 'destination email address',
subject: `${title}`,
text: `${resultText}`
};
dateLog('Sending Email');
mailerInstance.sendMail(mailOptions, function(error, info){
if (error) {
console.log(error);
} else {
console.log('Email sent: ' + info.response);
}
});
}
mainEntry();
//execute every 5 mins
setInterval(mainEntry, REQUEST_INTERVAL);
>> Logger
Logger is the simplest module in the application, essentially we want all logs to have a timestamp on it so that we can verify that mainEntry is been executed at the set frequency. It is just a thin wrapper around console.log to include timestamp at the beginning.
//logger.js
//logging with timestamp
module.exports = function (content){
let date = new Date().toISOString();
console.log(`${date} : ${content}`);
}
>> Mailer
Mailer module is just another thin wrapper around nodemailer. By passing in the service type and authentication info, a mailer instance will be created and it is ready to be used to send out emails.
For gmail account, if you want to log in like this, you may need to enable log in from less secure app in the gmail setting.
//mailer.js
var nodemailer = require('nodemailer');
createMailer = () => {
let transporter = nodemailer.createTransport({
service: 'gmail',
auth: {
user: 'your email address',
pass: 'email password'
}
});
return transporter;
}
module.exports = {
createMailer
};
>> Browser
By calling puppeteer.launch(), a browser will be created. If we set headless: false in the config, an actual browser instance UI will show up and we will be able to see all the interactions took place.
//browser.js
const dateLog = require('./logger.js');
const puppeteer = require('puppeteer');
launchBrowser = async() => {
dateLog('Launching headless browser');
let browser = null;
try{
browser = await puppeteer.launch({
headless: true,
args: ["--disable-setuid-sandbox"],
'ignoreHTTPSErrors': true
});
}
catch(err){
dateLog(`Browser Launch Failed : ${err}`);
}
dateLog('Browser launched');
return browser;
}
module.exports = {
launchBrowser
};
>> Page Controller
After a browser instance has been created from the previous step, the browser instance will be passed into the page controller to handle page transition and scraping. In this case, all it does is to create the actual page scraper to handle the scraping logic and await the response data.
//pageController.js
const pageScraper = require('./pageScraper');
const dateLog = require('./logger');
async function scrapeAll(browserInstance){
let browser;
try{
browser = await browserInstance;
//navigate to page
const data = await pageScraper.scraper(browser);
return data;
}
catch(err){
dateLog("Could not resolve the browser instance => ", err);
}
}
module.exports = (browserInstance) => scrapeAll(browserInstance)
>> Page Scraper
Page Scraper module is the core module of the application to handle all the scraping logic of the page.
To understand what the scraper is trying to do, we first need to understand the structure of the website page that we are trying to scrape on. Different websites would most likely to have different page structures.
Normally, I would use 2 methods to determine how I would scrape a website:
- use postman to get the raw website in javascript + HTML form.
- inspect website page with chrome developer tools and looks for specific HTML tag pattern.
In this case, the div with class name 'pt0-5' contains all the product info within the tag so this is a good starting point. However this is a dynamic page and span tag that contains the actual stock status of the product and the span content may change based on the product variant selected. So if we are to scrape that particular span tag, we also need to simulate mouse click for potentially all the variants.
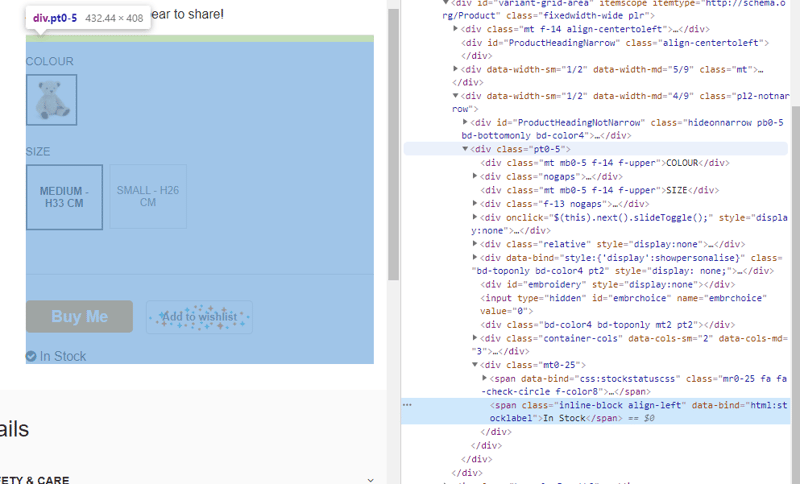
On a second thought, since the page is dynamic, the different variants infomation is either obtained by making an AJAX request when clicked or already obtained when the page is first loaded and get updated on the mouse click event handler.
To verify that, let us take a look at the raw HTML page before render. If we create a GET request to the URL, we will get the raw HTML page. If we search around some of the keywords we are looking for, it is easy to find there is a variable called variants that contains all the variants information including stock level and stock status.
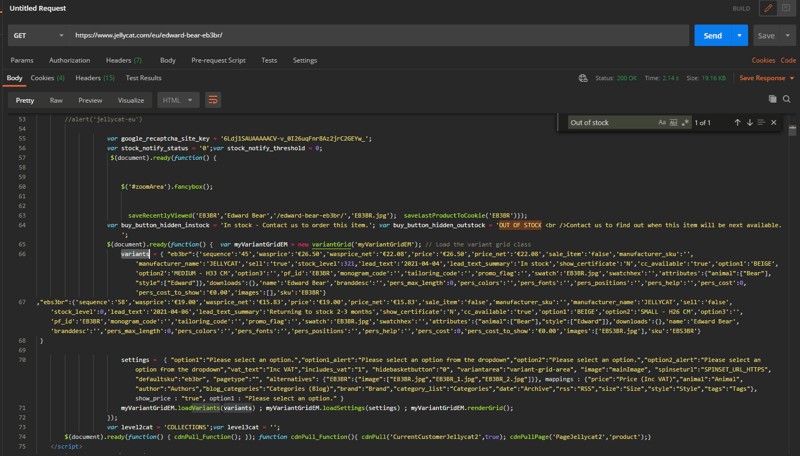
If we want to verify that, we can go back to the browser developer tool and in the console type in 'variants', we should be able to see the same content being displayed.
Bingo! So that could be our strategy to scrape this website. Note that scraping strategy is very dependent on the website you want to scrape, so doing some research is necessary.

Hopefully if we look at the code below, it should more or less make more sense to us.
//pageScraper.js
const dateLog = require('./logger.js');
//jelly cat bear scraper
const scraperObject = {
url: 'https://www.jellycat.com/eu/bumbly-bear-bum2br/',
async scraper(browser){
let page = await browser.newPage();
let data = null;
dateLog(`Navigating to ${this.url}...`);
await page.goto(this.url);
// Wait for the required DOM to be rendered
await page.waitForSelector('.pt0-5');
return new Promise((resolve, reject) => {
//register a log event to DOM
page.on('console', consoleObj => {
dateLog('headless console response');
data = JSON.parse(consoleObj.text());
resolve(data);
})
dateLog(`Start Scraping`);
page.evaluate( () => {
let text = JSON.stringify(variants);
console.log(text);
});
})
}
}
module.exports = scraperObject;
First, we await the desired page to be loaded. Since we found out the div with class p0-5 contains the information we need, we await until this tag gets loaded. This step may not be necessary since we are directly working with JS variables but I just keep it just to be safe.
Then we return a new promise, inside the promise, we register a console event handler. That means whenever the console of that page prints out something in the headless browser, the event will be fired and call the function that get passed in. The reason we do this is because we want to capture the content of the variants variable by printing it out in the console to fire the console event.
Inside the page.evaluate function, note that the function passed in is not interpreted by your application but interpreted by the headless browser. So that means inside the headless browser, we would like to stringify the variants varibles to strings and console.log the strings. This would cause the console event that we just created to fire.
The reason we would want to wrap those 2 into a promise is to aviod passing in callback funtion from one level up which would potentailly produce callback hell if the application has more levels. So in the level above in pageController, all it needs to do is to await the response data to be returned.
//part of page Controller
//navigate to page
const data = await pageScraper.scraper(browser);
return data;
>> Sending Email
The response data gets returned all the way back to index.js and an email regarding the stock info will be sent out the destination email address.
//part of index.js
data = await scraperController(browserInstance);
console.log(data.eb3br);
let date = new Date().toISOString();
//construct email text content
let resultText =
`${date} Product Code :EB3BR Stock Status: ${JSON.stringify(data.eb3br.lead_text_summary)} Stock Level: ${JSON.stringify(data.eb3br.stock_level)} \n`;
let title = (JSON.stringify(data.eb3br.lead_text_summary) == 'In stock')?
'Product In Stock!!!':'JellyCat Stock Report';
let mailOptions = {
from: 'source email address',
to: 'destination email address',
subject: `${title}`,
text: `${resultText}`
};
dateLog('Sending Email');
mailerInstance.sendMail(mailOptions, function(error, info){
if (error) {
console.log(error);
} else {
console.log('Email sent: ' + info.response);
}
});
>>Conclusion
There are a lot of improvements can be made to this project. For example, the final sending example bit can be warpped into a function and the setInterval logic can be done different, because we don't need to close down the browser each time, all we need is to reload the page or recreate the page. Feel free to change it.
I believe web scrpaing is a valuable skillset to have and it has very versatile usage as far as I am concerned.
Posted on March 7, 2021
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related