Data Science Interview Questions and Answers.

Jadieljade
Posted on April 18, 2024
здравствуйте. This past week I was trying to look at questions I may encounter in data science interviews and thought to share some. Please add any others in the comments.
Q1: Mention three ways to make your model robust to outliers or How to deal with outliers.
Dealing with outliers is crucial in data analysis and modeling to ensure that our models are robust and not unduly influenced by extreme values. Here are three common strategies to handle outliers and make our models more robust:
-
Trimming or Winsorizing:
- Trimming involves removing a certain percentage of data points from both ends of the distribution, where outliers typically lie. This ensures that extreme values have less impact on the model without completely discarding them.
- Winsorizing is similar to trimming but instead of removing data points, we replace them with the nearest non-outlier values. This helps in retaining the sample size while reducing the influence of outliers.
-
Robust Regression Techniques:
- Robust regression methods are designed to be less sensitive to outliers compared to traditional linear regression. Examples include:
- RANSAC (RANdom SAmple Consensus): This algorithm iteratively fits models to subsets of the data, excluding outliers.
- Huber Regression: Combines the best of least squares and absolute deviation loss functions, providing a compromise between robustness and efficiency.
- Theil-Sen Estimator: Computes the slope by considering all pairs of points, making it robust to outliers.
- Robust regression methods are designed to be less sensitive to outliers compared to traditional linear regression. Examples include:
-
Transforming Variables:
- Transforming variables using mathematical functions such as logarithm, square root, or Box-Cox transformation can make the distribution more symmetric and reduce the impact of outliers.
- For example, taking the logarithm of a positively skewed variable can make it more normally distributed, thereby mitigating the influence of outliers.
Each of these strategies has its advantages and limitations, and the choice depends on the specific characteristics of the data and the modeling task at hand. It's often beneficial to explore multiple approaches and assess their effectiveness through cross-validation or other validation techniques.
Q2: Describe the motivation behind random forests and mention two reasons why they are better than individual decision trees.
The motivation behind random forests lies in addressing the limitations of individual decision trees while harnessing their strengths. Decision trees are powerful models known for their simplicity, interpretability, and ability to handle both numerical and categorical data. However, they are prone to overfitting, meaning they can capture noise in the training data and generalize poorly to unseen data. Random forests aim to mitigate these shortcomings through the following mechanisms:
-
Ensemble Learning:
- Random forests employ an ensemble learning technique, where multiple decision trees are trained independently and then combined to make predictions. Each tree is trained on a random subset of the training data and uses a random subset of features for splitting at each node. This randomness introduces diversity among the trees, reducing overfitting and improving generalization performance.
-
Bagging (Bootstrap Aggregating):
- Random forests use a technique called bagging, which involves training each decision tree on a bootstrap sample of the training data. A bootstrap sample is obtained by sampling the training data with replacement, resulting in multiple subsets of data that may overlap. By averaging the predictions of multiple trees trained on different subsets of data, random forests reduce the variance of the model, leading to more stable and robust predictions.
Two key reasons why random forests are often superior to individual decision trees:
-
Reduced Overfitting:
- The ensemble nature of random forests, combined with the randomness introduced during training, helps reduce overfitting compared to individual decision trees. By averaging the predictions of multiple trees, random forests are less likely to memorize noise in the training data and are more capable of generalizing well to unseen data.
-
Improved Performance:
- Random forests typically offer better performance in terms of predictive accuracy compared to individual decision trees, especially on complex datasets with high-dimensional feature spaces. The combination of multiple decision trees trained on different subsets of data and features allows random forests to capture more complex patterns in the data, leading to more accurate predictions.
Q3: What are the differences and similarities between gradient boosting and random forest? and what are the advantages and disadvantages of each when compared to each other?
Similarities:
Gradient boosting and random forests are both ensemble learning techniques used for supervised learning tasks, particularly for regression and classification problems. While they share similarities in their ensemble nature and ability to improve predictive performance, they have distinct differences in their algorithms, training processes, and performance characteristics. Let's explore the differences, similarities, advantages, and disadvantages of each when compared to each other:
Differences:
-
Base Learners:
- Random Forests: Each tree in a random forest is trained independently on a random subset of the training data and a random subset of features.
- Gradient Boosting: Base learners (typically decision trees) are trained sequentially, with each new tree fitting to the residuals (errors) of the previous trees. The subsequent trees focus on reducing the errors made by the previous trees.
-
Training Process:
- Random Forests: Trees are grown in parallel, meaning each tree is built independently of the others.
- Gradient Boosting: Trees are grown sequentially, with each new tree attempting to correct the errors made by the combined ensemble of all previous trees.
-
Loss Function Optimization:
- Random Forests: Each tree in the forest aims to minimize impurity measures such as Gini impurity or entropy during training.
- Gradient Boosting: Trees are optimized to minimize a predefined loss function, such as mean squared error (for regression) or cross-entropy (for classification), by iteratively fitting to the negative gradient of the loss function.
Similarities:
-
Ensemble Learning:
- Both random forests and gradient boosting are ensemble learning methods that combine multiple base learners to make predictions. This helps reduce overfitting and improve generalization performance compared to individual learners.
-
Tree-Based Models:
- Both methods use decision trees as base learners. Decision trees are versatile models capable of handling both numerical and categorical data, making them suitable for a wide range of problems.
Advantages and Disadvantages:
Random Forests:
-
Advantages:
- Robust to overfitting: Random forests tend to generalize well to unseen data due to their ensemble nature and the randomness introduced during training.
- Less sensitive to hyperparameters: Random forests are less sensitive to hyperparameter tuning compared to gradient boosting, making them easier to use out of the box.
- Efficient for parallel processing: The training of individual trees in a random forest can be parallelized, leading to faster training times on multicore processors.
-
Disadvantages:
- Lack of interpretability: Random forests are less interpretable compared to gradient boosting, as the combined predictions of multiple trees make it challenging to understand the underlying decision process.
- Can be biased towards dominant classes: In classification problems with imbalanced classes, random forests may be biased towards the majority class, leading to suboptimal performance for minority classes.
Gradient Boosting:
-
Advantages:
- High predictive accuracy: Gradient boosting often yields higher predictive accuracy compared to random forests, especially on complex datasets with high-dimensional feature spaces.
- Better interpretability: The sequential nature of gradient boosting allows for easier interpretation of feature importance and model predictions compared to random forests.
- Handles class imbalance well: Gradient boosting can handle class imbalance better than random forests by adjusting the weights of misclassified instances during training.
-
Disadvantages:
- Prone to overfitting: Gradient boosting is more prone to overfitting compared to random forests, especially when the number of trees (iterations) is high or the learning rate is too aggressive.
- More sensitive to hyperparameters: Gradient boosting requires careful tuning of hyperparameters such as the learning rate, tree depth, and regularization parameters, which can be time-consuming and computationally intensive.
- Slower training time: The sequential nature of gradient boosting makes it slower to train compared to random forests, especially when the dataset is large or the number of trees is high.
Q4: What are L1 and L2 regularization? What are the differences between the two?
Answer:
L1 and L2 regularization are techniques used to prevent overfitting by adding penalty terms to the loss function.
-
L1 Regularization (Lasso):
- Adds the absolute values of coefficients to the loss function.
- Encourages sparsity and feature selection by setting some coefficients to zero.
- Can be sensitive to outliers.
-
L2 Regularization (Ridge):
- Adds the squared magnitudes of coefficients to the loss function.
- Encourages smaller coefficients but does not enforce sparsity as strongly as L1.
- More robust to outliers.
Differences:
- L1 encourages sparsity, while L2 does not.
- L1 can set coefficients to zero, L2 does not.
- L1 is more computationally expensive.
- L2 is more robust to outliers.
Q5: Mention three ways to handle missing or corrupted data in a dataset.
Answer:
In general, real-world data often has a lot of missing values. The cause of missing values can be data corruption or failure to record data. Handling missing or corrupted data is crucial for building accurate and reliable machine learning models. Here are three common techniques for dealing with missing or corrupted data:
-
Imputation:
- Imputation involves filling in missing values with estimated or predicted values based on the available data.
- Simple imputation methods include replacing missing values with the mean, median, or mode of the feature.
- More advanced imputation techniques include using regression models or k-nearest neighbors (KNN) to predict missing values based on other features.
-
Deletion:
- Deletion involves removing observations or features with missing or corrupted data from the dataset.
- Listwise deletion (removing entire rows with missing values) and pairwise deletion (using available data for analysis and ignoring missing values) are common deletion techniques.
- Deletion is straightforward but may lead to loss of valuable information, especially if missing data is not completely random.
-
Advanced Techniques:
- Advanced techniques involve more sophisticated methods for handling missing or corrupted data.
- Multiple imputation methods, such as the MICE (Multiple Imputation by Chained Equations) algorithm, generate multiple imputed datasets by replacing missing values with plausible values sampled from their predictive distribution.
- Using machine learning algorithms that can handle missing data internally, such as tree-based models or deep learning algorithms, can also be effective.
Each of these techniques has its advantages and limitations, and the choice depends on factors such as the amount of missing data, the nature of the problem, and the characteristics of the dataset. It's often beneficial to explore multiple techniques and evaluate their performance using cross-validation or other validation methods to determine the most suitable approach for the specific dataset and modeling task.
Q6: Explain briefly the logistic regression model and state an example of when you have used it recently.
Answer:
Logistic regression is used to calculate the probability of occurrence of an event in the form of a dependent output variable based on independent input variables. Logistic regression is commonly used to estimate the probability that an instance on whether it belongs to a particular class or not. If the probability is bigger than 0.5 then it will belong to that class (positive) and if it is below 0.5 it will belong to the other class.
It is important to remember that the Logistic regression isn't a classification model, it's an ordinary type of regression algorithm but it can be used in classification when we put a threshold to determine specific categories"
There is a lot of classification applications to it such as : Classify email as spam or not, To identify whether the patient is healthy or not, and so on.
Q7: Explain briefly batch gradient descent, stochastic gradient descent, and mini-batch gradient descent. and what are the pros and cons for each of them?
Gradient descent is a generic optimization algorithm cable for finding optimal solutions to a wide range of problems. The general idea of gradient descent is to tweak parameters iteratively in order to minimize the cost function.
Batch Gradient Descent:
In Batch Gradient descent the whole training data is used to minimize the cost function by taking a step toward the nearest minimum via calculating the gradient i.e. the direction of descent.
Pros:
Since the whole data set is used to calculate the gradient it will be stable and reach the minimum of the cost function without bouncing (if the learning rate is chosen cooreclty)
Cons:
Since batch gradient descent uses all the training set to compute the gradient at every step, it will be very slow especially if the size of the training data is large.
Stochastic Gradient Descent:
Stochastic Gradient Descent picks up a random instance in the training data set at every step and computes the gradient based only on that single instance.
Pros:
- It makes the training much faster as it only works on one instance at a time.
- It become easier to train large datasets
Cons:
Due to the stochastic (random) nature of this algorithm, this algorithm is much less regular than the batch gradient descent. Instead of gently decreasing until it reaches the minimum, the cost function will bounce up and down, decreasing only on average. Over time it will end up very close to the minimum, but once it gets there it will continue to bounce around, not settling down there. So once the algorithm stops the final parameters are good but not optimal. For this reason, it is important to use a training schedule to overcome this randomness.
Mini-batch Gradient:
At each step instead of computing the gradients on the whole data set as in the Batch Gradient Descent or using one random instance as in the Stochastic Gradient Descent, this algorithm computes the gradients on small random sets of instances called mini-batches.
Pros:
- The algorithm's progress space is less erratic than with Stochastic Gradient Descent, especially with large mini-batches.
- You can get a performance boost from hardware optimization of matrix operations, especially when using GPUs.
Cons:
- It might be difficult to escape from local minima.
Q8: Explain what is information gain and entropy in the context of decision trees.
Entropy and Information Gain are two key metrics used in determining the relevance of decision-making when constructing a decision tree and thereby determining the nodes and the best way to split.
The idea of a decision tree is to divide the data set into smaller and smaller data sets based on the descriptive features until we reach a small enough set that contains data points that fall under one label.
Entropy is the measure of impurity or disorder or uncertainty in a bunch of examples. Entropy controls how a Decision Tree decides to split the data. Information gain on the other hand calculates the reduction in entropy. It is commonly used in the construction of decision trees from a training dataset, by evaluating the information gain for each variable and selecting the variable that maximizes the information gain which in turn minimizes the entropy and best splits the dataset into groups for effective classification.
Q9: What are the differences between a model that minimizes squared error and the one that minimizes the absolute error? and in which cases each error metric would be more appropriate?*
Both mean square error (MSE) and mean absolute error (MAE) measures the distances between vectors and express average model prediction in units of the target variable. Both can range from 0 to infinity, the lower they are the better the model.
The main difference between them is that in MSE the errors are squared before being averaged while in MAE they are not. This means that a large weight will be given to large errors. MSE is useful when large errors in the model are trying to be avoided. This means that outliers affect MSE more than MAE, that is why MAE is more robust to outliers.
Computation-wise MSE is easier to use as the gradient calculation will be more straightforward than MAE, which requires linear programming to calculate it.
Q10: Define and compare parametric and non-parametric models and give two examples for each of them?
Answer:
Parametric models assume that the dataset comes from a certain function with some set of parameters that should be tuned to reach the optimal performance. For such models, the number of parameters is determined prior to training thus the degree of freedom is limited and reduces the chances of overfitting.
Ex. Linear Regression, Logistic Regression, LDA
Nonparametric models don't assume anything about the function from which the dataset was sampled. For these models, the number of parameters is not determined prior to training, thus they are free to generalize the model based on the data. Sometimes these models overfit themselves while generalizing. To generalize they need more data in comparison with Parametric Models. In addition to that they are relatively more difficult to interpret compared to Parametric Models.
Ex. Decision Tree, Random Forest.
Q11: You are working on a clustering problem, what are different evaluation metrics that can be used, and how to choose between them?
Answer:
Clusters are evaluated based on some similarity or dissimilarity measure such as the distance between cluster points. If the clustering algorithm separates dissimilar observations and clutters similar observations together, then it has performed well. The two most popular metrics evaluation metrics for clustering algorithms are the 𝐒𝐢𝐥𝐡𝐨𝐮𝐞𝐭𝐭𝐞 𝐜𝐨𝐞𝐟𝐟𝐢𝐜𝐢𝐞𝐧𝐭 and 𝐃𝐮𝐧𝐧’𝐬 𝐈𝐧𝐝𝐞𝐱.
𝐒𝐢𝐥𝐡𝐨𝐮𝐞𝐭𝐭𝐞 𝐜𝐨𝐞𝐟𝐟𝐢𝐜𝐢𝐞𝐧𝐭
The Silhouette Coefficient is defined for each sample and is composed of two scores:
a: The mean distance between a sample and all other points in the same cluster.
b: The mean distance between a sample and all other points in the next nearest cluster.
S = (b-a) / max(a,b)
The 𝐒𝐢𝐥𝐡𝐨𝐮𝐞𝐭𝐭𝐞 𝐜𝐨𝐞𝐟𝐟𝐢𝐜𝐢𝐞𝐧𝐭 for a set of samples is given as the mean of the Silhouette Coefficient for each sample. The score is bounded between -1 for incorrect clustering and +1 for highly dense clustering. Scores around zero indicate overlapping clusters. The score is higher when clusters are dense and well separated which relates to a standard concept of a cluster.
Dunn’s Index
Dunn’s Index (DI) is another metric for evaluating a clustering algorithm. Dunn’s Index is equal to the minimum inter-cluster distance divided by the maximum cluster size. Note that large inter-cluster distances ( better separation ) and smaller cluster sizes ( more compact clusters ) lead to a higher DI value. A higher DI implies better clustering. It assumes that better clustering means that clusters are compact and well-separated from other clusters.
Q12: What is the ROC curve and when should you use it?
Answer:
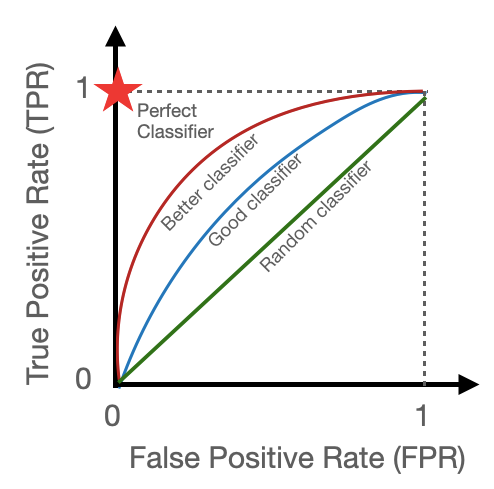
ROC curve or Receiver Operating Characteristic curve, is a graphical representation of the model's performance where we plot the True Positive Rate (TPR) against the False Positive Rate (FPR) for different threshold values, for hard classification (i.e. binary classification), between 0 to 1 based on model output.
ROC curve is mainly used to compare two or more models as shown in the above figure. Now, it is easy to see that a reasonable model will always give FPR less (since it's an error) than TPR so, the curve hugs the upper left corner of the square box 0 to 1 on the TPR axis and 0 to 1 on the FPR axis. The more the AUC (area under the curve) for a model's ROC curve, the better the model in terms of prediction accuracy in terms of TPR and FPR.
Here are some benefits of using the ROC Curve :
Can help prioritize either true positives or true negatives depending on your case study (Helps you visually choose the best hyperparameters for your case)
Can be very insightful when we have unbalanced datasets
Can be used to compare different ML models by calculating the area under the ROC curve (AUC)
Q13: What is the difference between hard and soft voting classifiers in the context of ensemble learners?
Answer:
Hard Voting: In a hard voting classifier, each individual classifier in the ensemble gets a vote, and the majority class is chosen as the final prediction. This is similar to a "popular vote" system, where the most commonly predicted class wins.
Soft Voting: In a soft voting classifier, the individual classifiers provide a probability estimate for each class, and the average probabilities across all classifiers are computed for each class. The class with the highest average probability is then chosen as the final prediction. This approach takes into account the confidence level of each classifier.

Q14: What is boosting in the context of ensemble learners discuss two famous boosting methods
Answer:
Boosting refers to any Ensemble method that can combine several weak learners into a strong learner. The general idea of most boosting methods is to train predictors sequentially, each trying to correct its predecessor.
There are many boosting methods available, but by far the most popular are:
- Adaptive Boosting: One way for a new predictor to correct its predecessor is to pay a bit more attention to the training instances that the predecessor under-fitted. This results in new predictors focusing more and more on the hard cases.
- Gradient Boosting: Another very popular Boosting algorithm is Gradient Boosting. Just like AdaBoost, Gradient Boosting works by sequentially adding predictors to an ensemble, each one correcting its predecessor. However, instead of tweaking the instance weights at every iteration as AdaBoost does, this method tries to fit the new predictor to the residual errors made by the previous predictor.
Q15: How can you evaluate the performance of a dimensionality reduction algorithm on your dataset?
Answer:
Intuitively, a dimensionality reduction algorithm performs well if it eliminates a lot of dimensions from the dataset without losing too much information. One way to measure this is to apply the reverse transformation and measure the reconstruction error. However, not all dimensionality reduction algorithms provide a reverse transformation.
Alternatively, if you are using dimensionality reduction as a preprocessing step before another Machine Learning algorithm (e.g., a Random Forest classifier), then you can simply measure the performance of that second algorithm; if dimensionality reduction did not lose too much information, then the algorithm should perform just as well as when using the original dataset.
Q16: Define the curse of dimensionality and how to solve it.
Answer:
Curse of dimensionality represents the situation when the amount of data is too few to be represented in a high-dimensional space, as it will be highly scattered in that high-dimensional space and becomes more probable that we overfit this data. If we increase the number of features, we are implicitly increasing model complexity and if we increase model complexity we need more data.
Possible solutions are: Remove irrelevant features or features not resulting in much improvement, for which we can use:
- Feature selection(select the most important ones).
- Feature extraction(transform current feature dimensionality into a lower dimension preserving the most possible amount of information like PCA ).
Q17: In what cases would you use vanilla PCA, Incremental PCA, Randomized PCA, or Kernel PCA?
Answer:
Regular or Vanilla PCA is the default, but it works only if the dataset fits in memory. Incremental PCA is useful for large datasets that don't fit in memory, but it is slower than regular PCA, so if the dataset fits in memory you should prefer regular PCA. Incremental PCA is also useful for online tasks when you need to apply PCA on the fly, every time a new instance arrives. Randomized PCA is useful when you want to considerably reduce dimensionality and the dataset fits in memory; in this case, it is much faster than regular PCA. Finally, Kernel PCA is useful for nonlinear datasets.
Q18: Discuss two clustering algorithms that can scale to large datasets
Answer:
Minibatch Kmeans: Instead of using the full dataset at each iteration, the algorithm is capable of using mini-batches, moving the centroids just slightly at each iteration. This speeds up the algorithm typically by a factor of 3 or 4 and makes it possible to cluster huge datasets that do not fit in memory.
Balanced Iterative Reducing and Clustering using Hierarchies (BIRCH): is a clustering algorithm that can cluster large datasets by first generating a small and compact summary of the large dataset that retains as much information as possible. This smaller summary is then clustered instead of clustering the larger dataset.
Q19: What are Loss Functions and Cost Functions? Explain the key Difference Between them.
Answer:
The loss function is the measure of the performance of the model on a single training example, whereas the cost function is the average loss function over all training examples or across the batch in the case of mini-batch gradient descent. Some examples of loss functions are Mean Squared Error, Binary Cross Entropy, etc. Whereas, the cost function is the average of the above loss functions over training examples.
Q20: What is the importance of batch in machine learning and explain some batch-dependent gradient descent algorithms?
Answer:
In the memory, the dataset can load either completely at once or in the form of a set. If we have a huge size of the dataset, then loading the whole data into memory will reduce the training speed, hence batch term is introduced.
Example: image data contains 1,00,000 images, we can load this into 3125 batches where 1 batch = 32 images. So instead of loading the whole 1,00,000 images in memory, we can load 32 images 3125 times which requires less memory.
In summary, a batch is important in two ways: (1) Efficient memory consumption. (2) Improve training speed.
There are 3 types of gradient descent algorithms based on batch size: (1) Stochastic gradient descent (2) Batch gradient descent (3) Mini Batch gradient descent
Q21: Why boosting is a more stable algorithm as compared to other ensemble algorithms?
Answer:
Boosting algorithms focus on errors found in previous iterations until they become obsolete. Whereas in other ensemble algorithms such as bagging there is no corrective loop. That’s why boosting is a more stable algorithm compared to other ensemble algorithms.
Q22: What are autoencoders? Explain the different layers of autoencoders and mention three practical usages of them?
Answer:
Autoencoders are one of the deep learning types used for unsupervised learning. There are three key layers in autoencoders, which are the input layer which is the encoder, bottleneck hidden layer and the output layer which is the decoder.
The three layers of the autoencoder are:-
1) Encoder - Compresses the input data to an encoded representation which is typically much smaller than the input data.
2) Latent Space Representation or Bottleneck or Hidden Layer - Compact summary of the input containing the most important features
3) Decoder - Decompresses the knowledge representation and reconstructs the data back from its encoded form. Then a loss function is used at the top to compare the input and output images.
NOTE- It's a requirement that the dimensionality of the input and output be the same. Everything in the middle can be played with.
Autoencoders have a wide variety of usage in the real world. The following are some of the popular ones:
- Text Summarizer or Text Generator
- Image compression
- Nonlinear version of PCA
Q23: What is an activation function and discuss the use of an activation function? Explain three different types of activation functions?
Answer:
In mathematical terms, the activation function serves as a gate between the current neuron input and its output, going to the next layer. Basically, it decides whether neurons should be activated or not and is used to introduce non-linearity into a model.
As mentioned activation functions are added to introduce non-linearity to the network, it doesn't matter how many layers or how many neurons your net has, the output will be linear combinations of the input in the absence of activation functions. In other words, activation functions are what make a linear regression model different from a neural network. We need non-linearity, to capture more complex features that simple linear models can not capture.
There are a lot of activation functions:
- Sigmoid function: f(x) = 1/(1+exp(-x))
The output value of it is between 0 and 1, we can use it for classification. It has some problems like the gradient vanishing on the extremes, also it is computationally expensive since it uses exp.
- Relu: f(x) = max(0,x)
it returns 0 if the input is negative and the value of the input if the input is positive. It solves the problem of vanishing gradient for the positive side, however, the problem is still on the negative side. It is fast because we use a linear function in it.
- Leaky ReLU:
F(x)= ax, x<0
F(x)= x, x>=0
It solves the problem of vanishing gradient on both sides by returning a value “a” on the negative side and it does the same thing as ReLU for the positive side.
- Softmax: it is usually used at the last layer for a classification problem because it returns a set of probabilities, where the sum of them is 1. Moreover, it is compatible with cross-entropy loss, which is usually the loss function for classification problems.
Q24: You are using a deep neural network for a prediction task. After training your model, you notice that it is strongly overfitting the training set and that the performance on the test isn’t good. What can you do to reduce overfitting?
To reduce overfitting in a deep neural network changes can be made in three places/stages: The input data to the network, the network architecture, and the training process:
- The input data to the network:
- Check if all the features are available and reliable
- Check if the training sample distribution is the same as the validation and test set distribution. Because if there is a difference in validation set distribution then it is hard for the model to predict as these complex patterns are unknown to the model.
- Check for train / valid data contamination (or leakage)
- The dataset size is enough, if not try data augmentation to increase the data size
- The dataset is balanced
- Network architecture:
- Overfitting could be due to model complexity. Question each component:
- can fully connect layers be replaced with convolutional + pooling layers?
- what is the justification for the number of layers and number of neurons chosen? Given how hard it is to tune these, can a pre-trained model be used?
- Add regularization - lasso (l1), ridge (l2), elastic net (both)
- Add dropouts
Add batch normalization
The training process:
Improvements in validation losses should decide when to stop training. Use callbacks for early stopping when there are no significant changes in the validation loss and restore_best_weights.
Q25: Why should we use Batch Normalization?
Batch normalization is a technique for training deep neural networks that standardizes the inputs to a layer for each mini-batch.
Usually, a dataset is fed into the network in the form of batches where the distribution of the data differs for every batch size. By doing this, there might be chances of vanishing gradient or exploding gradient when it tries to backpropagate. In order to combat these issues, we can use BN (with irreducible error) layer mostly on the inputs to the layer before the activation function in the previous layer and after fully connected layers.
Batch Normalisation has the following effects on the Neural Network:
- Robust Training of the deeper layers of the network.
- Better covariate-shift proof NN Architecture.
- Has a slight regularisation effect.
- Centred and Controlled values of Activation.
- Tries to Prevent exploding/vanishing gradient.
- Faster Training/Convergence to the minimum loss function
Q26: How to know whether your model is suffering from the problem of Exploding Gradients?
By taking incremental steps towards the minimal value, the gradient descent algorithm aims to minimize the error. The weights and biases in a neural network are updated using these processes. However at times the steps grow excessively large, resulting in increased updates to weights and bias terms to the point where the weights overflow (or become NaN, that is, Not a Number). An exploding gradient is the result of this and it is an unstable method.
There are some subtle signs that you may be suffering from exploding gradients during the training of your network, such as:
- The model is unable to get traction on your training data (e g. poor loss).
- The model is unstable, resulting in large changes in loss from update to update.
- The model loss goes to NaN during training.
If you have these types of problems, you can dig deeper to see if you have a problem with exploding gradients. There are some less subtle signs that you can use to confirm that you have exploding gradients:
- The model weights quickly become very large during training.
- The model weights go to NaN values during training.
- The error gradient values are consistently above 1.0 for each node and layer during training.
Q27: Can you name and explain a few hyperparameters used for training a neural network?
Answer:
Hyperparameters are any parameter in the model that affects the performance but is not learned from the data unlike parameters ( weights and biases), the only way to change it is manually by the user.
Number of nodes: number of inputs in each layer.
Batch normalization: normalization/standardization of inputs in a layer.
Learning rate: the rate at which weights are updated.
Dropout rate: percent of nodes to drop temporarily during the forward pass.
Kernel: matrix to perform dot product of image array with
Activation function: defines how the weighted sum of inputs is transformed into outputs (e.g. tanh, sigmoid, softmax, Relu, etc)
Number of epochs: number of passes an algorithm has to perform for training
Batch size: number of samples to pass through the algorithm individually. E.g. if the dataset has 1000 records and we set a batch size of 100 then the dataset will be divided into 10 batches which will be propagated to the algorithm one after another.
Momentum: Momentum can be seen as a learning rate adaptation technique that adds a fraction of the past update vector to the current update vector. This helps damps oscillations and speed up progress towards the minimum.
Optimizers: They focus on getting the learning rate right.
Adagrad optimizer: Adagrad uses a large learning rate for infrequent features and a smaller learning rate for frequent features.
Other optimizers, like Adadelta, RMSProp, and Adam, make further improvements to fine-tuning the learning rate and momentum to get to the optimal weights and bias. Thus getting the learning rate right is key to well-trained models.
- Learning Rate: Controls how much to update weights & bias (w+b) terms after training on each batch. Several helpers are used to getting the learning rate right.
Q28: Describe the architecture of a typical Convolutional Neural Network (CNN)?
Answer:
In a typical CNN architecture, a few convolutional layers are connected in a cascade style. Each convolutional layer is followed by a Rectified Linear Unit (ReLU) layer or other activation function, then a pooling layer*, then one or more convolutional layers (+ReLU), then another pooling layer.
The output from each convolution layer is a set of objects called feature maps, generated by a single kernel filter. The feature maps are used to define a new input to the next layer. A common trend is to keep on increasing the number of filters as the size of the image keeps dropping as it passes through the Convolutional and Pooling layers. The size of each kernel filter is usually 3×3 kernel because it can extract the same features which extract from large kernels and faster than them.
After that, the final small image with a large number of filters(which is a 3D output from the above layers) is flattened and passed through fully connected layers. At last, we use a softmax layer with the required number of nodes for classification or use the output of the fully connected layers for some other purpose depending on the task.
The number of these layers can increase depending on the complexity of the data and when they increase you need more data. Stride, Padding, Filter size, Type of Pooling, etc all are Hyperparameters and need to be chosen (maybe based on some previously built successful models)
- Pooling: it is a way to reduce the number of features by choosing a number to represent its neighbor. And it has many types max-pooling, average pooling, and global average.
- Max pooling: it takes the max number of window 2×2 as an example and represents this window by using the max number in it then slides on the image to make the same operation.
- Average pooling: it is the same as max-pooling but takes the average of the window.
Q29: What is the Vanishing Gradient Problem in Artificial Neural Networks and How to fix it?
Answer:
The vanishing gradient problem is encountered in artificial neural networks with gradient-based learning methods and backpropagation. In these learning methods each of the weights of the neural network receives an update proportional to the partial derivative of the error function with respect to the current weight in each iteration of training. Sometimes when gradients become vanishingly small, this prevents the weight to change value.
When the neural network has many hidden layers, the gradients in the earlier layers will become very low as we multiply the derivatives of each layer. As a result, learning in the earlier layers becomes very slow. 𝐓𝐡𝐢𝐬 𝐜𝐚𝐧 𝐜𝐚𝐮𝐬𝐞 𝐭𝐡𝐞 𝐧𝐞𝐮𝐫𝐚𝐥 𝐧𝐞𝐭𝐰𝐨𝐫𝐤 𝐭𝐨 𝐬𝐭𝐨𝐩 𝐥𝐞𝐚𝐫𝐧𝐢𝐧𝐠. This problem of vanishing gradient descent happens when training neural networks with many layers because the gradient diminishes dramatically as it propagates backward through the network.
Some ways to fix it are:
- Use skip/residual connections.
- Using ReLU or Leaky ReLU over sigmoid and tanh activation functions.
- Use models that help propagate gradients to earlier time steps like in GRUs and LSTMs.
Note : Skip or residual connections are a technique used in neural networks to address the vanishing gradient problem. In a skip connection, the output of one layer is added to the output of one or more layers that are located deeper in the network. This allows the gradient to flow directly through the skip connection during backpropagation, bypassing some of the intermediate layers where the gradient might vanish.
By including skip connections, the network can learn to adjust the weights in a way that makes it easier for the gradient to flow through the network, which can help alleviate the vanishing gradient problem and improve the training of deep neural networks.
Q30: When it comes to training an artificial neural network, what could be the reason why the loss doesn't decrease in a few epochs?
Answer:
Some of the reasons why the loss doesn't decrease after a few Epochs are:
a) The model is under-fitting the training data.
b) The learning rate of the model is large.
c) The initialization is not proper (like all the weights initialized with 0 doesn't make the network learn any function)
d) The Regularisation hyper-parameter is quite large.
e). The classic case of vanishing gradients
Q31: Why Sigmoid or Tanh is not preferred to be used as the activation function in the hidden layer of a neural network?
Answer:
A common problem with Tanh or Sigmoid functions is that they saturate. Once saturated, the learning algorithms cannot adapt to the weights and enhance the performance of the model.
Thus, Sigmoid or Tanh activation functions prevent the neural network from learning effectively leading to a vanishing gradient problem. The vanishing gradient problem can be addressed with the use of Rectified Linear Activation Function (ReLu) instead of sigmoid or Tanh.
Q32: Discuss in what context it is recommended to use transfer learning and when it is not.
Answer:
Transfer learning is a machine learning method where a model developed for a task is reused as the starting point for a model of some other task. It is a popular approach in deep learning where pre-trained models are used as the starting point for computer vision and natural language processing tasks given the vast computing and time resources required to develop neural network models on these problems and from the huge jumps in a skill that they provide on related problems.
In addition to that transfer learning is used for tasks where the data is too little to train a full-scale model from the beginning. In transfer learning, well-trained, well-constructed networks are used which have learned over large sets and can be used to boost the performance of a dataset.
𝐓𝐫𝐚𝐧𝐬𝐟𝐞𝐫 𝐋𝐞𝐚𝐫𝐧𝐢𝐧𝐠 𝐜𝐚𝐧 𝐛𝐞 𝐮𝐬𝐞𝐝 𝐢𝐧 𝐭𝐡𝐞 𝐟𝐨𝐥𝐥𝐨𝐰𝐢𝐧𝐠 𝐜𝐚𝐬𝐞𝐬:
The downstream task has a very small amount of data available, then we can try using pre-trained model weights by switching the last layer with new layers which we will train.
In some cases, like in vision-related tasks, the initial layers have a common behavior of detecting edges, then a little more complex but still abstract features and so on which is common in all vision tasks, and hence a pre-trained model's initial layers can be used directly. The same thing holds for Language Models too, for example, a model trained in a large Hindi corpus can be transferred and used for other Indo-Aryan Languages with low resources available.
𝐂𝐚𝐬𝐞𝐬 𝐰𝐡𝐞𝐧 𝐭𝐫𝐚𝐧𝐬𝐟𝐞𝐫 𝐋𝐞𝐚𝐫𝐧𝐢𝐧𝐠 𝐬𝐡𝐨𝐮𝐥𝐝 𝐧𝐨𝐭 𝐛𝐞 𝐮𝐬𝐞𝐝:
The first and most important is the "COST". So is it cost-effective or we can have a similar performance without using it.
The pre-trained model has no relation to the downstream task.
If the latency is a big constraint (Mostly in NLP ) then transfer learning is not the best option. However Now with the TensorFlow lite kind of platform and Model Distillation, Latency is not a problem anymore.
Q33: Discuss the vanishing gradient in RNN and How they can be solved.*
Answer:
In Sequence to Sequence models such as RNNs, the input sentences might have long-term dependencies for example we might say "The boy who was wearing a red t-shirt, blue jeans, black shoes, and a white cap and who lives at ... and is 10 years old ...... etc, is genius" here the verb (is) in the sentence depends on the (boy) i.e if we say (The boys, ......, are genius". When training an RNN we do backward propagation both through layers and backward through time. Without focusing too much on mathematics, during backward propagation we tend to multiply gradients that are either > 1 or < 1, if the gradients are < 1 and we have about 100 steps backward in time then multiplying 100 numbers that are < 1 will result in a very very tiny gradient causing no change in the weights as we go backward in time (0.1 * 0.1 * 0.1 * .... a 100 times = 10^(-100)) such that in our previous example the word "is" doesn't affect its main dependency the word "boy" during learning the meanings of the word due to the long description in between.
Models like the Gated Recurrent Units (GRUs) and the Long short-term memory (LSTMs) were proposed, the main idea of these models is to use gates to help the network determine which information to keep and which information to discard during learning. Then Transformers were proposed depending on the self-attention mechanism to catch the dependencies between words in the sequence.
Q34: What are the main gates in LSTM and what are their tasks?
Answer:
There are 3 main types of gates in a LSTM Model, as follows:
- Forget Gate
- Input/Update Gate
- Output Gate
1) Forget Gate:- It helps in deciding which data to keep or thrown out
2) Input Gate:- it helps in determining whether new data should be added in long term memory cell given by previous hidden state and new input data
3) Output Gate:- this gate gives out the new hidden state
Common things for all these gates are they all take inputs as the current temporal state/input/word/observation and the previous hidden state output and sigmoid activation is mostly used in all of these.
Q35: Is it a good idea to use CNN to classify 1D signal?
Answer:
For time-series data, where we assume temporal dependence between the values, then convolutional neural networks (CNN) are one of the possible approaches. However the most popular approach to such data is to use recurrent neural networks (RNN), but you can alternatively use CNNs, or a hybrid approach (quasi-recurrent neural networks, QRNN).
With CNN, you would use sliding windows of some width, that would look at certain (learned) patterns in the data, and stack such windows on top of each other, so that higher-level windows would look for patterns within the lower-level windows. Using such sliding windows may be helpful for finding things such as repeating patterns within the data. One drawback is that it doesn't take into account the temporal or sequential aspect of the 1D signals, which can be very important for prediction.
With RNN, you would use a cell that takes as input the previous hidden state and current input value to return output and another hidden so that the information flows via the hidden states and takes into account the temporal dependencies.
QRNN layers mix both approaches.
Q36: How does L1/L2 regularization affect a neural network?
Answer:
Overfitting occurs in more complex neural network models (many layers, many neurons) and the complexity of the neural network can be reduced by using L1 and L2 regularization as well as dropout , Data augmenration and Dropaout. L1 regularization forces the weight parameters to become zero. L2 regularization forces the weight parameters towards zero (but never exactly zero|| weight deccay ). Smaller weight parameters make some neurons neglectable therfore neural network becomes less complex and less overfitting.
Regularisation has the following benefits:
- Reducing the variance of the model over unseen data.
- Makes it feasible to fit much more complicated models without overfitting.
- Reduces the magnitude of weights and biases.
- L1 learns sparse models that is many weights turn out to be 0.
Q37: 𝐇𝐨𝐰 𝐰𝐨𝐮𝐥𝐝 𝐲𝐨𝐮 𝐜𝐡𝐚𝐧𝐠𝐞 𝐚 𝐩𝐫𝐞-𝐭𝐫𝐚𝐢𝐧𝐞𝐝 𝐧𝐞𝐮𝐫𝐚𝐥 𝐧𝐞𝐭𝐰𝐨𝐫𝐤 𝐟𝐫𝐨𝐦 𝐜𝐥𝐚𝐬𝐬𝐢𝐟𝐢𝐜𝐚𝐭𝐢𝐨𝐧 𝐭𝐨 𝐫𝐞𝐠𝐫𝐞𝐬𝐬𝐢𝐨𝐧?
Answer:
Using transfer learning where we can use our knowledge about one task to do another. First set of layers of a neural network are usually feature extraction layers and will be useful for all tasks with the same input distribution. So, we should replace the last fully connected layer and Softmax responsible for classification with one neuron for regression-or fully connected-layer for correction then followed by one neuron for regression.
We can optionally freeze the first set of layers if we have few data or if we want to converge fast. Then we can train the network with the data we have and using the suitable loss for the regression problem, making use of the robust feature extraction i.e. the first set of layers of a pre-trained model on huge data.
Q38: What are the hyperparameters that can be optimized for the batch normalization layer?
Answer: The $\gamma$ and $\beta$ hyperparameters for the batch normalization layer are learned end to end by the network. In batch-normalization the outputs of the intermediate layers are normalized to have a mean of 0 and standard deviation of 1. Rescaling by $\gamma$ and shifting by $\beta$ helps us change the mean and standard deviation to other values.
Q39: What is the effect of dropout on the training and prediction speed of your deep learning model?
Answer: Dropout is a regularization technique, which zeroes down some weights and scales up the rest of the weights by a factor of 1/(1-p). Let's say if Dropout layer is initialized with p=0.5, that means half of the weights will zeroed down, and rest will be scaled by a factor of 2. This layer is only enabled during training and is disabled during validation and testing, making the validation and testing faster. The reason why it works only during training is, we want to reduce the complexity of the model so that model doesn't overfit. Once the model is trained, it doesn't make sense to keep that layer enabled.
Q40: What is the advantage of deep learning over traditional machine learning?
Answer:
Deep learning offers several advantages over traditional machine learning approaches, including:
Ability to process large amounts of data: Deep learning models can analyze and process massive amounts of data quickly and accurately, making it ideal for tasks such as image recognition or natural language processing.
Automated feature extraction: In traditional machine learning, feature engineering is a crucial step in the model building process. Deep learning models, on the other hand, can automatically learn and extract features from the raw data, reducing the need for human intervention.
Better accuracy: Deep learning models have shown to achieve higher accuracy levels in complex tasks such as speech recognition and image classification when compared to traditional machine learning models.
Adaptability to new data: Deep learning models can adapt and learn from new data, making them suitable for use in dynamic and ever-changing environments.
While deep learning does have its advantages, it also has some limitations, such as requiring large amounts of data and computational resources, making it unsuitable for some applications.
If you made it here I hope you enjoyed the questions. Thank you for the read. Till next time. 😁😁 до свидания
Posted on April 18, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related

November 29, 2024