5 steps to deal with bugs on your React applications

João Forja 💭
Posted on July 2, 2020
When we find a bug in our applications, fixing it is only the beginning. We also need to make sure the same bug won't happen again, and we should also take the opportunity to prevent similar bugs from happening. To help us achieve those goals, we can use the following process:
- Analyze the defect and find the broken code.
- Reproduce the bug in a targeted automated test and fix it.
- Improve the code design to reduce the likelihood of bugs.
- Perform root-cause analysis to find the origin of the bug.
- Conduct exploratory testing to find similar bugs.
In this article, we'll go over a bug on a React application and use this 5 step approach to fix it and prevent future ones. By the end of this article, you'll have a better understanding of how this process works and how to apply it to bugs you might find on your applications.
Applying the process
To show how this process would work in practice, we'll use a simplistic React application that allows a user to select a book from a list and then fetches the name author of the chosen book from an API and displays it.
Below is the code that's relevant for this example:
const NO_BOOK_SELECTED = "no-book-selected"
const LOADING = "loading"
const SHOW_AUTHOR = "show-author"
const ERROR = "error"
function Books({ fetchBookAuthor }) {
const [{ author, status }, setState] = useState({
status: NO_BOOK_SELECTED,
author: null,
})
function fetchSelectedBookAuthor(event) {
setState({ status: LOADING })
fetchBookAuthor({ bookId: event.target.value })
.then(
bookAuthor => ({ status: SHOW_AUTHOR, author: bookAuthor }),
() => ({ status: ERROR })
)
.then(newState => setState(newState))
}
return (
<>
<form>
<label htmlFor="book">Book</label>
<select id="book" defaultValue="" onChange={fetchSelectedBookAuthor}>
<option value="" disabled hidden>
Select a book
</option>
<option value="1">TDD by example</option>
<option value="2">Clean Architecture</option>
<option value="3">The Software Craftsman</option>
<option value="4">Refactoring</option>
</select>
</form>
<div>
{status === NO_BOOK_SELECTED && <p>No book is selected.</p>}
{status === SHOW_AUTHOR && <p>{author}</p>}
{status === LOADING && <p>Loading...</p>}
{status === ERROR && <p>There was an error.</p>}
</div>
</>
)
}
1. Analyze the defect and find the responsible code
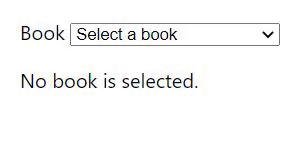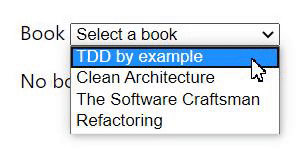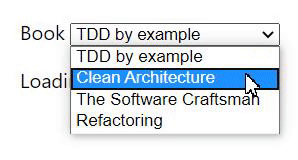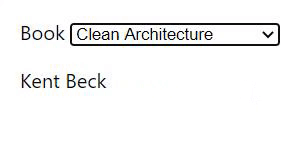
As we can see in the GIF above, the user selected the book "TDD by example" and before giving the API time to answer with the author, changed the book to "Clean Architecture". The result is that the application shows "Kent Beck" as the author of "Clean Architecture" when it should have shown "Robert C. Martin".
Since we are at the first step of the process, our focus is on making a hypothesis about why this bug might be happening and locate the area, or areas, of the code that we'll need to change to fix the bug.
From experience, I know that this kind of bug tends to happen due to race conditions. In particular, it occurs when responses from requests come out of order. So I hypothesize that the response for "TDD by example" came last even though it was made first, and that resulted in the UI updating the author to "Kent Beck" even though "TDD by example" was no longer the book the user selected.
Since we're dealing with a small example, we know that we'll have to change <Books/> to fix the bug.
2. Reproduce the bug with an automated test and fix it
Since we now have a hypothesis of what might be causing the bug, we will write an automated test to prove our hypothesis correct. By having an automated test, we also prevent the same bug from happening again. But before writing the test, we have to decide our testing boundary.
When defining a testing boundary that tries to reproduce a bug, I tend to establish it as close as possible to the faulty code without coupling the tests too much to the details. The goal is that if someone introduces this bug again in the system, they know that something broke and where it exactly broke. Therefore, I'll prefer using unit-level tests instead of E2E like tests since when an E2E test breaks, it can be tough to know where the problem is. For our specific example, let's place the testing boundary at the <Books/> component.
The test below reproduces the steps we think are responsible for the bug.
// This test uses Jest + React testing library
test(
"Avoids race conditions when responses for requests to get books' author " +
"come out of order",
function test() {
let resolveAuthorForTDDByExample
let resolveAuthorForCleanArchitecture
const fetchBookAuthor = jest
.fn()
.mockReturnValueOnce(
new Promise(res => {
resolveAuthorForTDDByExample = () => res("Kent Beck")
})
)
.mockReturnValueOnce(
new Promise(res => {
resolveAuthorForCleanArchitecture = () => res("Robert C. Martin")
})
)
render(<Books fetchBookAuthor={fetchBookAuthor} />)
const bookInput = screen.getByLabelText("Book")
userEvent.selectOptions(bookInput, screen.getByText("TDD by example"))
userEvent.selectOptions(bookInput, screen.getByText("Clean Architecture"))
resolveAuthorForCleanArchitecture()
resolveAuthorForTDDByExample()
return waitFor(() => {
expect(screen.getByText("Robert C. Martin")).toBeVisible()
})
}
)
The test above fails, proving our hypothesis correct. Next, we need to fix the code to make the test pass.
To make the test pass, we'll introduce a mechanism to detect if the response from a request is still relevant to the user or not. If it isn't, we'll ignore the response. For now, we'll worry about making it work. Later we'll take care of the design.
function Books({ fetchBookAuthor }) {
const [{ author, status }, setState] = useState({
status: NO_BOOK_SELECTED,
author: null,
});
// Added ref to DOM element so we can check the current selected book
const bookSelectInputRef = useRef();
function fetchSelectedBookAuthor(event) {
const bookId = event.target.value;
setState({ status: LOADING });
fetchBookAuthor({ bookId })
.then(
(bookAuthor) => ({ status: SHOW_AUTHOR, author: bookAuthor }),
() => ({ status: ERROR })
)
.then((newState) => {
const currentSelectedBook = bookSelectInputRef.current.value;
currentSelectedBook === bookId && setState(newState);
});
}
return (
<>
<form>
<label htmlFor="book">Book</label>
<select
id="book"
defaultValue=""
ref={bookSelectInputRef}
onChange={fetchSelectedBookAuthor}
>
...
</>
);
}
Now our test passes so we can go to the next step.
3. Improve the code design to prevent bugs
The goal of this step is to try to understand how the current code design might have caused the bug to happen, and improve the design to prevent bugs in the same area of the code.
The specific ways in which we can improve an existing design are many, and a topic that I won't go over in this article. But as a general guideline I try to guide the code towards better readability by reducing complexity and making hidden concepts explicit.
For our specific example, I find it confusing how we use the state in the <select/> DOM element to determine if a response is still useful to the user. I think it doesn't express intent well. I'd like to refactor the code to make it evident that when the user changes the book, we no longer care about any responses from ongoing requests. I think that the concept of cancellation might be a good fit here. So let's refactor the code in that direction.
function Books({ fetchBookAuthor }) {
const [{ author, status }, setState] = useState({
status: NO_BOOK_SELECTED,
author: null,
});
const [selectedBookId, setSelectedBookId] = useState("");
useEffect(() => {
if (!selectedBookId) return;
let cancelled = false;
setState({ status: LOADING });
fetchBookAuthor({ bookId: selectedBookId })
.then(
(bookAuthor) => ({ status: SHOW_AUTHOR, author: bookAuthor }),
() => ({ status: ERROR })
)
.then((newState) => !cancelled && setState(newState));
return () => (cancelled = true);
}, [fetchBookAuthor, selectedBookId]);
return (
<>
<form>
<label htmlFor="book">Book</label>
<select
id="book"
value={selectedBookId}
onChange={(e) => setSelectedBookId(e.target.value)}
>
...
</>
);
}
The above was just an example of a possible refactor. We could have opted for other refactors that might give better results, like using a finite state machine to make the available states and transitions of the component easier to understand.
Keep in mind might be that not all bugs are caused by bad code design, so there might be nothing to do in this step.
4. Perform root-cause analysis to find the origin of the bug
The goal of this step is to determine the origin of a bug, so we can then improve what might be at fault. In my opinion, this is the most valuable step of the process as it can find some surprising issues that can tremendously help individuals and organizations move forward when solved.
There are multiple ways we can do a root-cause analysis, but a simple and effective is to use the "5 Whys" technique. This technique aims to look at a problem and continually ask why it happened until we reach what seems to be its root.
For our specific example, using the 5 whys technique could go something along the following lines:
- Why did we have a race condition bug? - The developer that implemented the feature wasn't aware of the possibility of race conditions when making API requests.
- Why didn't the developer know about race conditions? - It was his first time dealing with API requests, and he did it alone.
- Why didn't he ask for help from a colleague? - He felt afraid of being judged by his colleagues.
- Why was he afraid of being judged? - Because at the office, people believe that asking for help is a sign of incompetence.
From the example above, we can see that by following the bug, we revealed a cultural problem at the company that we can now decide how to address. Of course, there might be more causes than just that one, and choosing which cause to address will depend on the context. Nonetheless, the issues that this type of analysis can uncover are invaluable.
An important thing to keep in mind when doing this is to try not to blame individuals. Blaming individuals tends not to lead us to productive results. Keep the focus on the faults of the process.
5. Conduct exploratory testing to find similar bugs
The core idea behind this step is that bugs tend to cluster. So if someone found a bug in our application, we likely have others that follow the same pattern, and we should try to find them.
For our specific example, we would do some exploratory testing on our application focused on finding bugs related to making API requests and race conditions.
If you're not familiar with the term Exploratory Testing, I recommend you check this book. This is arguably a topic that's more important for QA than for developers. However, I believe that having this kind of knowledge as a developer can make a massive difference in the robustness of the applications we build.
Conclusion
When we find a bug in our applications, we can use the 5 step process explained in this article to fix the found bug and prevent future ones. So next time you spot a bug in your application, give this process a try.
I couldn't end this article without saying that I didn't come up with this process. I've learned it from James Shore, and I highly recommend you check out his blog.
If you enjoyed this article you can follow me on twitter where I share my thoughts about software development and life in general.
Posted on July 2, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related
