Scrape website based on Upwork job offer.

Ferry
Posted on September 7, 2020

Hello. How are you today? I hope you have a good day :D.
Today I want to share my experience after scrape an e-commerce web site, the name is Zomato. I scrape this website to practice real-world case, I got the idea after looking at job offer on UpWork.
Job description:
The client asked to scrape business information from some categories in "Melbourne" Australia in Zomato website. The categories are cafes, chinese, dumplings, french, and so on. All data must be inserted into a spreadsheet.
This is the data that client wants to scrape.

In this post, I try to tell the minimum requirement for finishing this job, for more you can try to develop it or you can see my GitHub.
What is needed?
Mostly scraping data almost always making HTTP requests and then parsing the responses. The libraries needed are request and beautifulsoup4.
How to install it?
Using pip command to install the libraries:
pip install requestspip install beautifulsoup4
Apart from those libraries, of course I need the URL that I want to scrape. This is the URL: https://www.zomato.com/melbourne/restaurants/cafes.
- The main domain → https://www.zomato.com/
- Followed by subdomain → melbourne/restaurants/cafes. This subdomain is what client ask for, that last one 'cafes' is the category.
Let's get started:
Step 1. I create a python file and give it name main.py, and on top of the file, I import the libraries.
import requests
from bs4 import BeautifulSoup
Step 2. After that my next move is to test what response the website gives. There are many response codes, you can check in this link if you want to know it all 😆. Maybe what you are familiar with is code 404, the web page not found. The way to check it.
res = requests.get('https://www.zomato.com/melbourne/restaurants/cafes')
print(res.status_code)
# 403
Using requests, this is my analogy:
I : "hey dude can I get the goods?"
Website: "Let me see your status_code first... It's 403. I know you want it, but you can't have it"
Wait... What??? During my journey, this is the first time I got 403 as a status code. What I want is 200, which means success.
I try to search for a solution over the internet and luckily I found it. My code needs a User-Agent, it is a "characteristic string that lets servers and network peers identify the application", see this link for more.
From my understanding when I try to request the website, it can't "recognize" the request I made, but won't let me in, so I need to put a "disguise" in my code. And that what User-Agent does. Make my code act like a browser from Zomato website point of view.
So my code now looks like this:
import requests
from bs4 import BeautifulSoup
res = requests.get('https://www.zomato.com/melbourne/restaurants/cafes', headers={'User-Agent': 'Mozilla/5.0'})
print(res.status_code)
# 200
Now it's giving me 200 as status code, means OK. Nice!
Step 3. The door is open now, and the time to scrape data using BeautifulSoup has come. So yeah, I write this code:
soup = BeautifulSoup(res.text, 'html.parser')
print(soup)
# <!DOCTYPE html>
# <html lang="en" prefix="og: http://ogp.me/ns#">
# ...
# </html>
I'll explain it to you.
res.text→ from the above requests(in step 2), I want to get the HTML as text.html.parser→ is a parser library that python has. About the parser, you can see this table.Lastly, when I print the soup, it gives the HTML code from the urls.
Step 4. Extract the value that the client wants. Let's find the cuisine first. I open the website and then right-click on my mouse so I can choose the inspect element feature.
What is that for? That step used to search for HTML tags that contain the cuisine text.
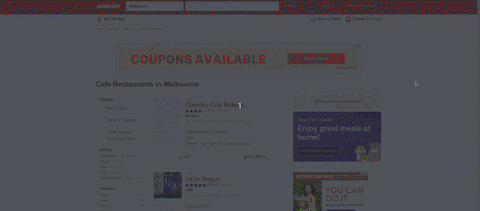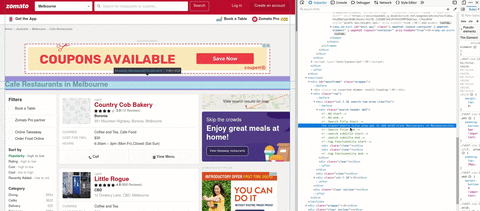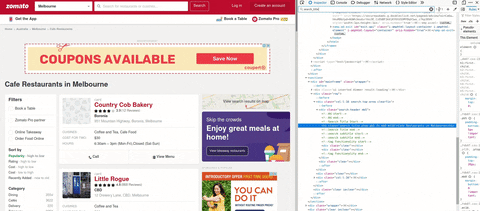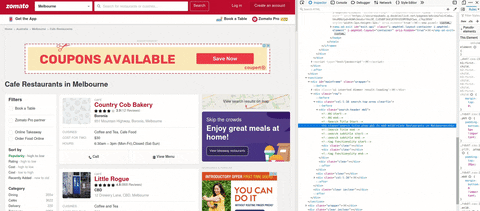
In the gif, you can see I search tag that contains the cuisine. Tag h1 and it has several class names. On top of that inspect element I use the search HTML, and copy the class, for checking how many class that has the same name.
Using search_title only has one match, and using mb0 I got 8. So in this step, I'm using search_title to find the cuisine.
cuisine = soup.find('h1', class_='search_title').text
print(cuisine)
# Cafe Restaurants in Melbourne
I only need one result, so I'm using find (for more click link). In the parentheses is the tag's name which h1 and the attribute class followed by its name search_title.
Don't forget to add an underscore after class, if you don't put it, it will return an error because python has that keyword too.
About the text in the last part, it is intended to get the text between the desired tags. If you don't write it, the response will look like this. The result will include the tag.
# <h1 class="search_title ptop pb5 fn mb0 mt10">
# Cafe Restaurants in Melbourne
# </h1>
Did you get it? Ask me at the comment below, if you don't. I'll try my best to help you and we can learn together 😆.
Ah... When I create this article the page shown as the picture below:

Let's continue to extract the rest values. Basically, the steps are the same as extracting cuisine. I just need to find the text location, pass the tag, and the class name.
For the organisation:
organisation = soup.find('a', class_='result-title').text
print(organisation)
# Country Cob Bakery
And for associate cuisine:
asso_cuisine = soup.find('span', class_='col-s-11 col-m-12 nowrap pl0').text
print(asso_cuisine)
# Coffee and Tea, Cafe Food
Is not that hard for me, until I realize something...
When you see the sample given by the client, location and address are in the same position. First I try to get the text.
test = soup.find('div', class_='search-result-address').text
print(test)
# 951 Mountain Highway, Boronia, Melbourne
Can you see it? It gives all inside the tag, but I don't know how to get '951 Mountain Highway' only or just 'Boronia'. I got confused and struck for hours to try to search for a possible solution. After a while I notice some pattern, look at this image:
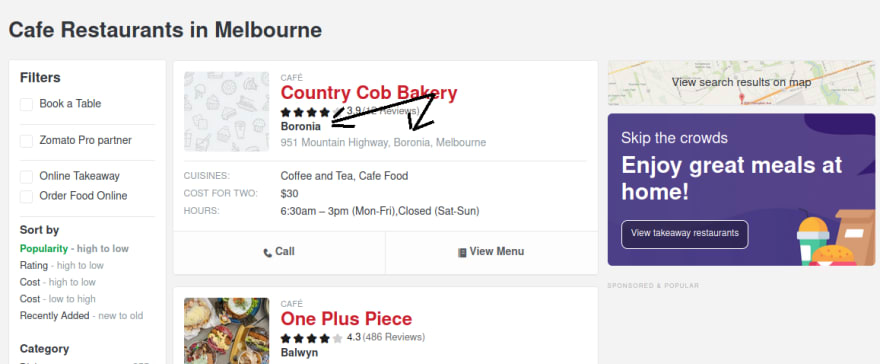
This is image Y
Below the rating star, there is a value like the client want for the location. So I don't need to grab the location from the same line as the address. At this time I think "the most important thing is I can deliver what the client wants".
The way to grab the location has been found. Quickly, I search for the tags that contain the location and then get the text.
Location:
location = soup.find('a', class_='search_result_subzone').text
print(location)
# Boronia
After I was able to pass the obstacle, I was automatically happy. But it not last long, immediately I remember about the other obstacle. How to get the address...?
I remember I've read about regular expression, and it looks like what I need, I still don't quite really understand. I try to search about it on the internet and I found about split(). At first, I thought split() is a part of regular expression, but it isn't.
split() is used for divide string into some part, and give the returns as a list:
str.split([separator [, maxsplit]])
If the separator not defines, by default split will treat any whitespace (space, newline, etc) as a separator, see this link.
Ok, I got it, but another confusion appear, what should I use as a separator?
I look over again the Y image, address is at the front comma(,) followed by whitespace and location → 951 Mountain Highway, Boronia, Melbourne. Finally, I try to use them as separators.
address:
address = soup.find('div', class_='search-result-address').text
separator = f', {location}'
address = address.split(separator)
print(address)
# [' 951 Mountain Highway', ', Melbourne']
print(address[0])
# 951 Mountain Highway
The separators not included in the list. Because I just want to grab the address, I use index-0. Because list starts with 0(zero).
For the phone:
phone = soup.find('a', class_='res-snippet-ph-info')['data-phone-no-str']
print(phone)
# 03 9720 2500
The full code looks like this:
import requests
from bs4 import BeautifulSoup
res = requests.get('https://www.zomato.com/melbourne/restaurants/cafes', headers={'User-Agent': 'Mozilla/5.0'})
soup = BeautifulSoup(res.text, 'html.parser')
cuisine = soup.find('h1', class_='search_title').text
organisation = soup.find('a', class_='result-title').text
asso_cuisine = soup.find('span', class_='col-s-11 col-m-12 nowrap pl0').text
location = soup.find('a', class_='search_result_subzone').text
address = soup.find('div', class_='search-result-address').text
test = soup.find('div', class_='search-result-address').text
phone = soup.find('a', class_='res-snippet-ph-info')['data-phone-no-str']
separator = f', {location}'
address = address.split(separator)
address = address[0]
Step 5. Because I want csv file as the output, on top of the main.py file I include the csv module. After that, I write the code for creating the file and code for input the value to that file.
import csv
# Create csv file
writer = csv.writer(open('./result.csv', 'w', newline='')) # method w -> write
headers = ['Cuisine', 'Assosiation Cuisine', 'Organisation', 'Address', 'Location', 'Phone']
writer.writerow(headers)
Let me be honest with you, when I write the code, I know that open() function will open the result.csv, but the rest I thought it was part of the csv.writer(). But I don't know why my mind can't focus that open() is a function. And not part of csv.writer().
Understanding the open() function. First I write the csv file's name, and w is the method stand for write. And the newline according to the documentation is for controls how universal newlines mode works (it only applies to text mode). It can be None, '', '\n', '\r', and '\r\n', see this link
csv.writer to convert user's data into a delimited string and writer.writerow() to writes a single row at a time. → link
# Add the value to csv file
writer = csv.writer(open('./result.csv', 'a', newline='', encoding='utf-8')) # method a -> append
data = [cuisine, asso_cuisine, organisation, address, location, phone]
writer.writerow(data)
Almost the same as the above explanation, the difference is the method a in it, a stands for append. see this → link
The final code looks like this:
import csv
import requests
from bs4 import BeautifulSoup
res = requests.get('https://www.zomato.com/melbourne/restaurants/cafes', headers={'User-Agent': 'Mozilla/5.0'})
soup = BeautifulSoup(res.text, 'html.parser')
cuisine = soup.find('h1', class_='search_title').text
organisation = soup.find('a', class_='result-title').text
asso_cuisine = soup.find('span', class_='col-s-11 col-m-12 nowrap pl0').text
location = soup.find('a', class_='search_result_subzone').text
address = soup.find('div', class_='search-result-address').text
test = soup.find('div', class_='search-result-address').text
phone = soup.find('a', class_='res-snippet-ph-info')['data-phone-no-str']
separator = f', {location}'
address = address.split(separator)
address = address[0]
writer = csv.writer(open('./result.csv', 'w', newline='')) # method w -> write
headers = ['Cuisine', 'Assosiation Cuisine', 'Organisation', 'Address', 'Location', 'Phone']
writer.writerow(headers)
writer = csv.writer(open('./result.csv', 'a', newline='', encoding='utf-8')) # method a -> append
data = [cuisine, asso_cuisine, organisation, address, location, phone]
writer.writerow(data)
That's it. It's the bare minimum to scrape the website, of course there are many more that need to be added. Like using iteration to grab all the data, adding pagination to get value on the next page.
But in this post, I want to share my journey from the beginning and not make this post too long to read. Maybe in the next post, I will continue to share my journey. Thanks for reading.
P.S. Don't be shy to ask a question and if you find something wrong (code or my explanation) please let me know in the comment below. Thanks in advance.
Posted on September 7, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related