Pandas 101 - pt. iii: Data Science Challenges

Hugo Estrada S.
Posted on July 28, 2020


Like always, the repository with all the notebooks and data of this three-part series about Pandas is here:
In this final lecture about Pandas, I'm going to show you some practical scenarios that you might face as a Data Scientist in the real world, and some more advance techniques for data analysis.
Let's start by importing Pandas and Matplotlib (a library for creating static, animated, and interactive visualizations in Python):
1) Know your Dataset, (I really mean it)
Data Science in a nutshell can be defined as the process by which we extra information from data. When doing Data Science, what we’re really trying to do is explain what all of the data actually means in the real-world, beyond the numbers.
In order to properly explain the information we've been working with, we need to understand what data we've just figured out, and the only way of doing this, is by really getting into the sources, the data-sources: the data set.
Depending on the needs and circumstances of the project you can always start by answering these 5 questions:
- What is the question we are trying to answer or problem we are trying to solve? This involves understanding the problem and tasks involved. Do we have the skill and the resources needed?
- What was the process by which the data arrived to us? This means understanding how it was created and transformed.
- What does the data look like? This is exploratory analysis. What dimensions exist, what measures exist, what is the relationship between each measure and other measures and dimensions.
- Are there issues with the data? If yes, how did they appear and can we solve them. This is related with outliers, NAs, NULLs, etc.
- Can we answer the question or solve the problem with these data? If not, why and can I solve it?
2) Dealing with Dates and Times
A lot of the analysis you will do, might relate to dates and times, for instance: finding the average number of sales over a given period, selecting a list of products to data mine if they were purchased in a given period, or trying to find the period with the most activity in online discussion activity.
I'll explain some of the basics of working with time series analysis.
First, you should be aware that date and times can be stored in many different ways. One of the most common legacy methods for storing the date and time in online transactions systems is based on the offset from the epoch, which is January 1, 1970.
There's a lot of historical cruft around this, but it's not uncommon to see systems storing the data of a transaction in seconds or milliseconds since this date. So if you see large numbers where you expect to see date and time, you'll need to convert them to make much sense out of the data.
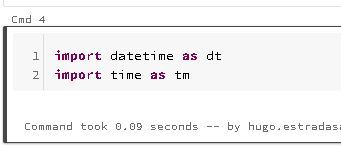
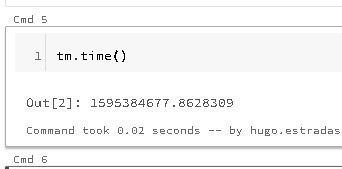
In Python, you can get the current time since the epoch using the time module. You can then create a time stamp using the time module:
From here, you can create a timestamp, from the timestamp function on the data-time object:
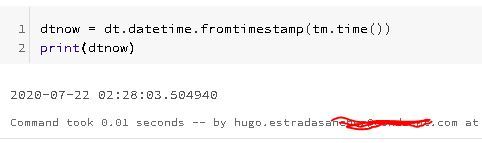
When we print this value out, we see that the year, month, day, and so forth are also printed out:

The date-time object has handy attributes to get the representative hour, day, seconds, etc.
3) Querying a DataFrame
Before we talk about how to query data frames, we need to talk about Boolean masking. Boolean masking is the heart of fast and efficient querying in NumPy. It's analogous a bit to masking used in other computational areas.
A Boolean mask is an array which can be of one dimension like a series, or two dimensions like a data frame, where each of the values in the array are either true or false. This array is essentially overlaid on top of the data structure that we're querying. And any cell aligned with the true value will be admitted into our final result, and any sign aligned with a false value will not.
Boolean masks are created by applying operators directly to the pandas series or DataFrame objects. For instance, in our Olympics data set, you might be interested in seeing only those countries who have achieved a gold medal at the summer Olympics.
To build a Boolean mask for this query, we project the gold column using the indexing operator and apply the greater than operator with a comparison value of zero. This is essentially broadcasting a comparison operator, greater than, with the results being returned as a Boolean series. The resultant series is indexed where the value of each cell is either true or false depending on whether a country has won at least one gold medal, and the index is the country name:
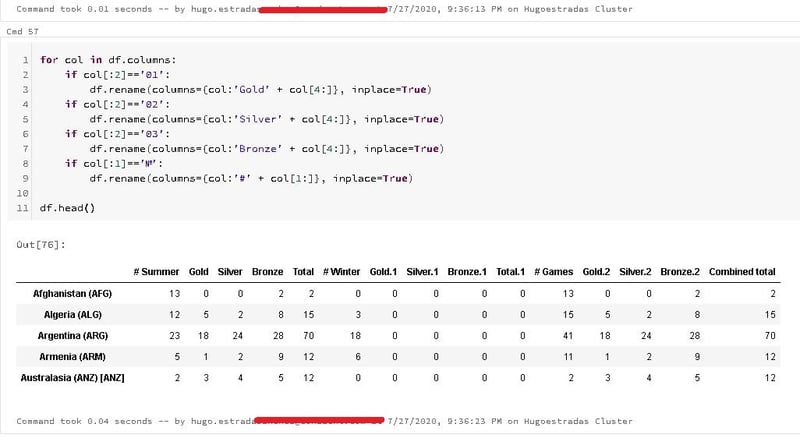
This is essentially broadcasting a comparison operator, greater than, with the results being returned as a Boolean series. The resultant series is indexed where the value of each cell is either true or false depending on whether a country has won at least one gold medal, and the index is the country name:
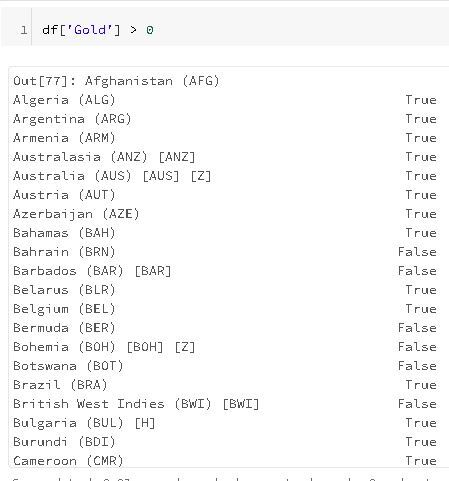
So this builds us the Boolean mask, which is half the battle. What we want to do next is overlay that mask on the data frame. We can do this using the where function. The where function takes a Boolean mask as a condition, applies it to the data frame or series, and returns a new data frame or series of the same shape. Let's apply this Boolean mask to our Olympics data and create a data frame of only those countries who have won a gold at a summer games:
4) Handling Missing Values (Brief intro to Data Cleansing)
Underneath Pandas does some type conversion, if I create a list of string and we have one element, a "none" type, Pandas inserts it as a none and uses the type object for the underlying array.
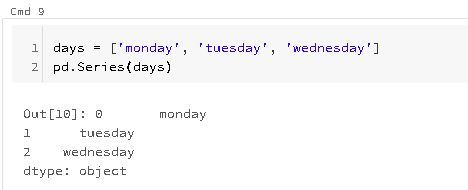
For further examples, I'm going to load the "log.csv" file:
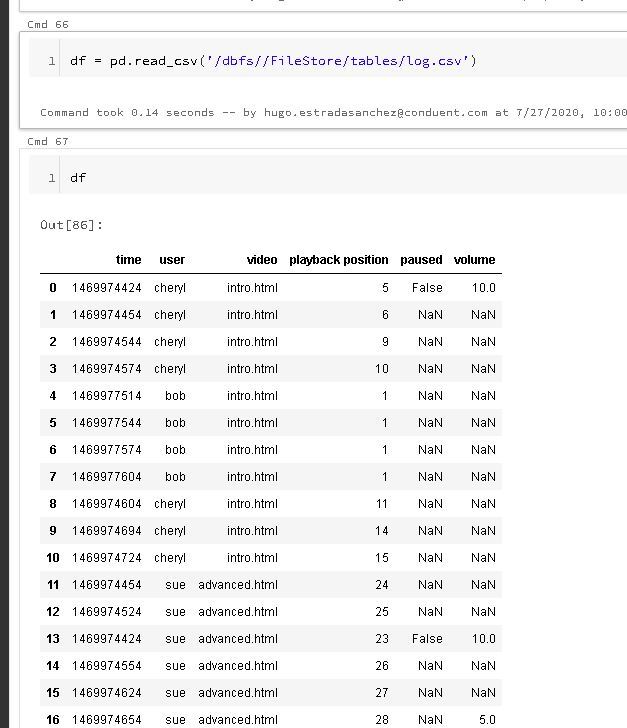
In this data the first column is a timestamp in the Unix epoch format. The next column is the user name followed by a web page they're visiting and the video that they're playing.
Each row of the DataFrame has a playback position. And we can see that as the playback position increases by one, the time stamp increases by about 30 seconds.
Except for user Bob. It turns out that Bob has paused his playback so as time increases the playback position doesn't change. Note too how difficult it is for us to try and derive this knowledge from the data, because it's not sorted by time stamp as one might expect. This is actually not uncommon on systems which have a high degree of parallelism.
There are a lot of missing values in the paused and volume columns. It's not efficient to send this information across the network if it hasn't changed. So this particular system just inserts null values into the database if there's no changes.
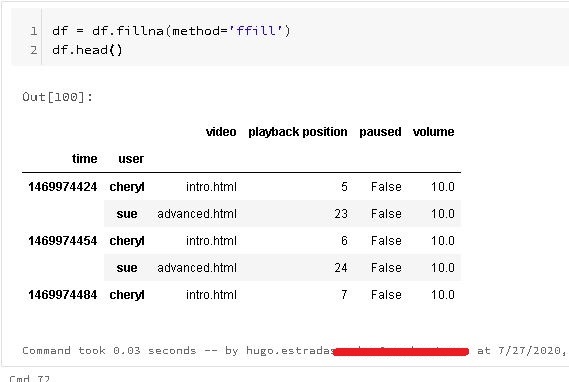
One of the handy functions that Pandas has for working with missing values is the filling function, "fillna".
This function takes a number or parameters, for instance, you could pass in a single value which is called a scalar value to change all of the missing data to one value. This isn't really applicable in this case, but it's a pretty common use case. Next up though is the method parameter. The two common fill values are ffill and bfill. ffill is for forward filling and it updates an na value for a particular cell with the value from the previous row. It's important to note that your data needs to be sorted in order for this to have the effect you might want. Data that comes from traditional database management systems usually has no order guarantee, just like this data. So be careful.
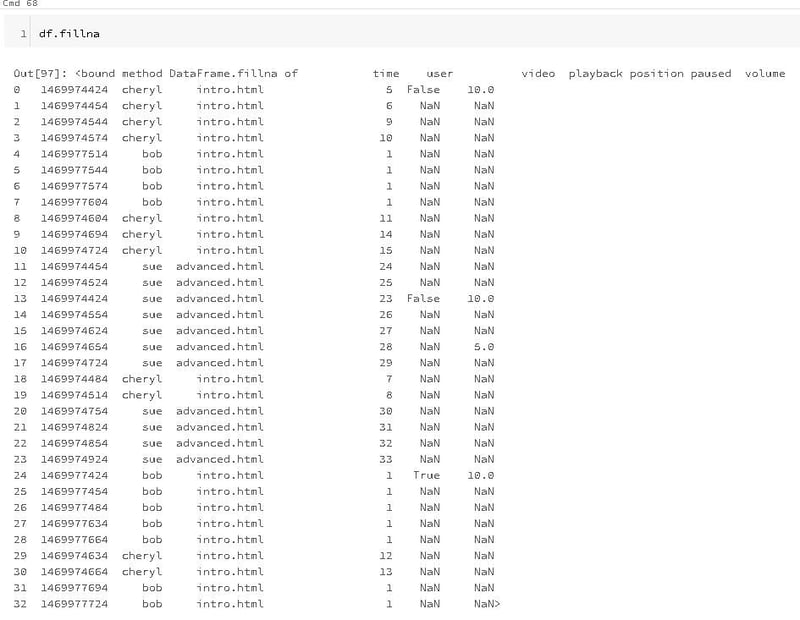
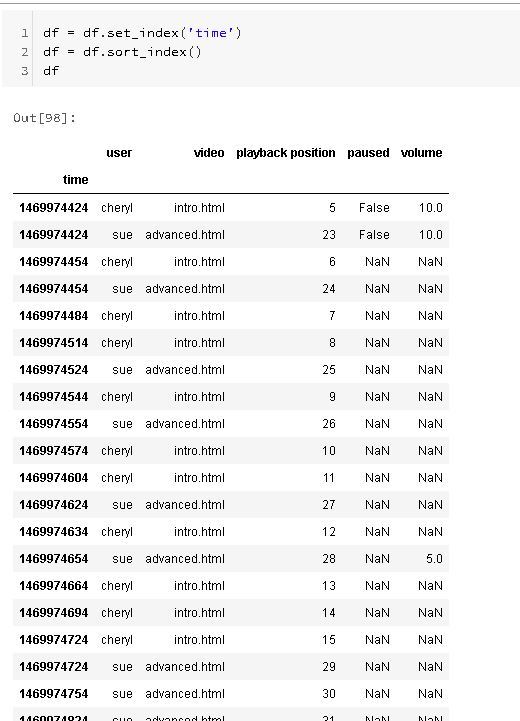
In Pandas we can sort either by index or by values. Here we'll just promote the time stamp to an index then sort on the index.
If we look closely at the output though we'll notice that the index isn't really unique. Two users seem to be able to use the system at the same time. Again, a very common case.
Let's reset the index, and use some multi-level indexing instead, and promote the user name to a second level of the index to deal with that issue.
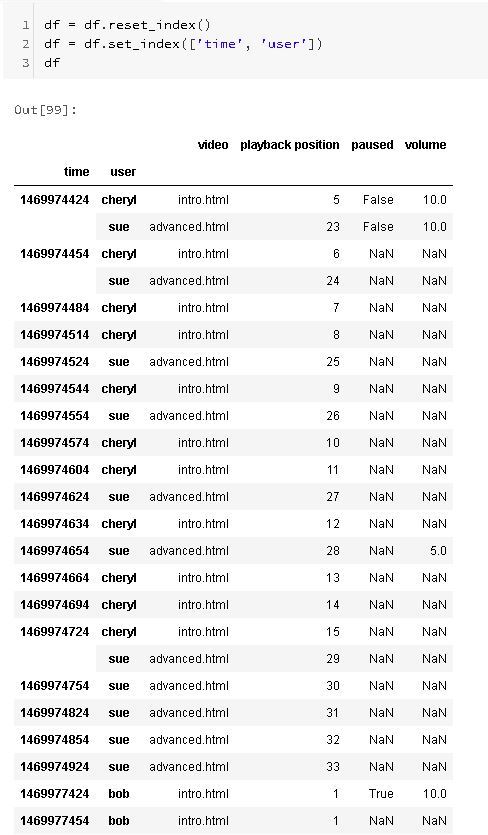
Now that we have the data indexed and sorted appropriately, we can fill the missing datas using ffill.
Posted on July 28, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related


