Pandas 101 - pt. ii: Practicing with DataFrames

Hugo Estrada S.
Posted on June 29, 2020


For starters, as usual the repository with all the notebooks of this three-part series about Pandas is here:
In my previous lecture I showed you the basics of the two main data structures of the Pandas library: Series and DataFrames.
Let's focus on the DataFrames for now.
1) Main Methods of Pandas
I'll start by creating our dummy DataFrame for this section:
In lecture pt. i I renamed the DataFrame column heading, but there are other ways of doing this.
You can rename your heading columns, by using another list:

If you'd like to keep the naming of the columns headings, but would like to replace some text-format, like special characters or spaces in-between names, you can use "str.replace()" function:

By default, the DataFrame has a numerical index.
You might want to change it according to your needs:

If just so happens you need to edit the entire DataFrame, with an apply and lambda function (more about that here: https://dev.to/hugoestradas/5-cool-python-tricks-4gcl) you can edit all the information in the DataFrame according to my needs, like add twice the value of "col three" to the "col two" column:

If you need to delete a record from the DataFrame, would come in handy to have a nice-defined index when using the drop() funtion:

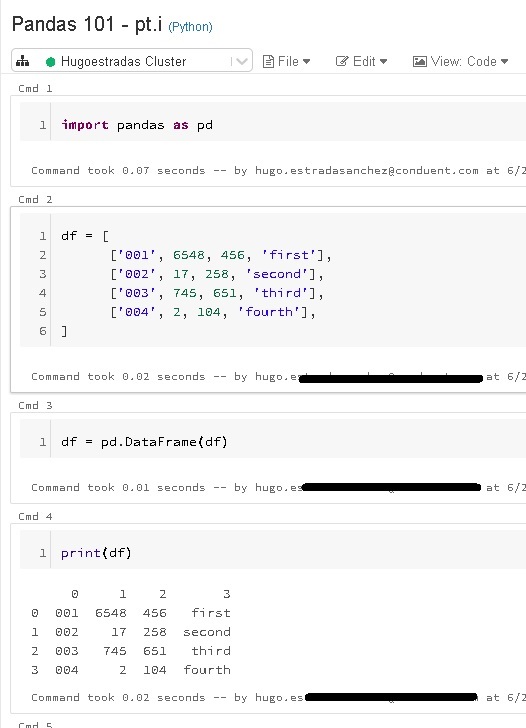
As a Data Scientist you might want to create copies of your DataFrame:
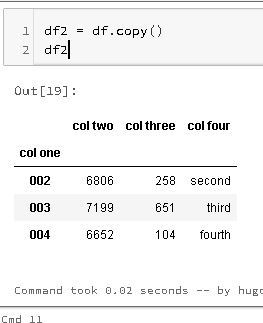
You might want to keep certain data in the DataFrame, using .loc with the help of some operators you can achieve this:
2) Multi-Indexing
Let's say you're reading a book with lots of chapters, in the index you look the title, that leads you to an specific page or chapter you might be looking for, in Pandas an Index it's a lot lot like this. An Index works like an address, that's how any data point across the DataFrame or series can be accessed.
For this section I'll need a bigger and more complex DataFrame with I'm going to create from a .csv file (which you can find here: https://www.kaggle.com/mokosan/lord-of-the-rings-character-data/download):
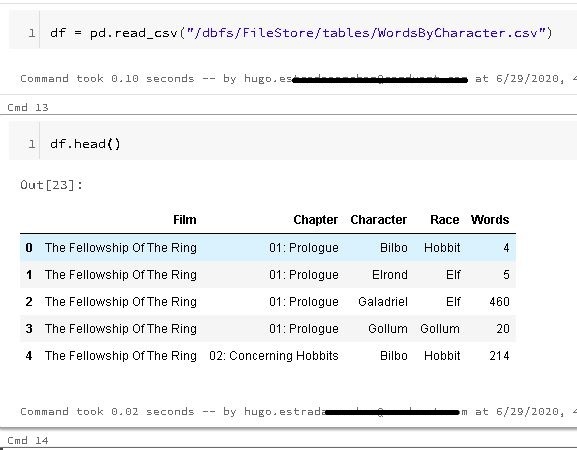
Since I'm using Azure Databricks I'm charging the file into the DBFS system, but you might not need to do this (depending on what Jupyter-like tool you're using).
If you want to know more about your DataFrame simply use ".info()" or if you want to take a glimpse to it use ".head()":
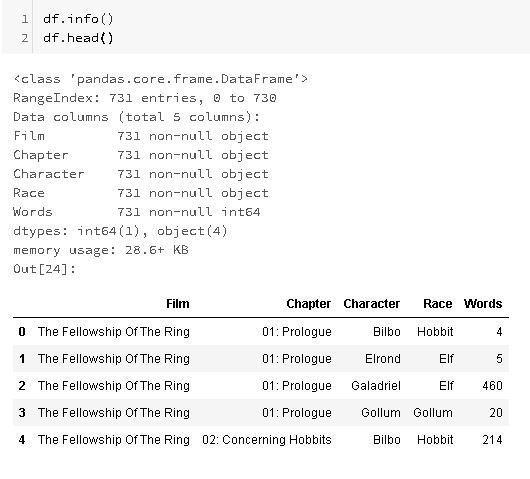
A MultiIndex is as a multi-level index or hierarchical index, that allows you to have multiple columns acting as a row identifier, while having each index column related to another through a parent/child relationship.
Now to start this exercise first I need to obtain the original DataFrame’s index label, we can use this code:
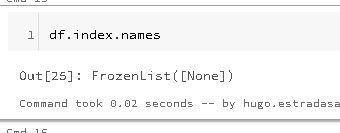
This output's result: “FrozenList”, is a Pandas specific construct used to show the index label(s) of a DataFrame.
Here, we see the value is “None”, as this is the default value of a DataFrame’s index.
In order to create a MultiIndex with the original DataFrame, all we need to do is pass a list of columns into the .set_index() Pandas function like this:


You can see that the new DataFrame called “multiindex” has been organized so that there are now four columns that make up the index. We can check this by looking at the index names once more:
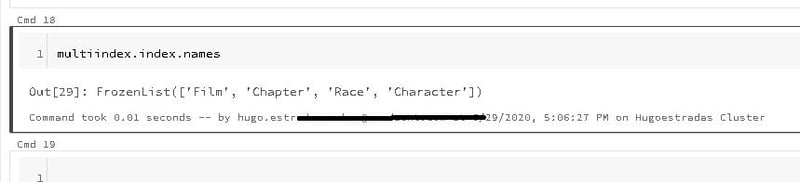
The previous “None” value has been replaced by the names of the four columns we assigned to be our new index.
Each index value in the regular, unaltered DataFrame would just be a number from 0 to 730 (because the DataFrame has 731 rows). To show you what each index value is in our newly created :multiindex", we can use this line of code:
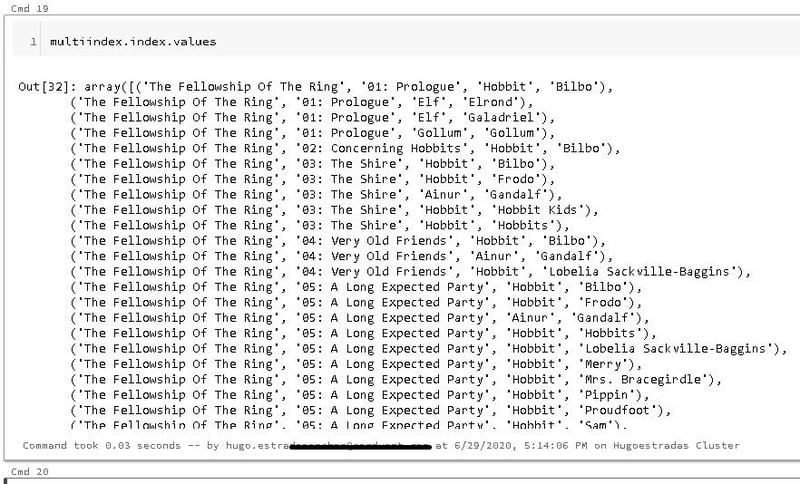
When creating a DataFrame with a MultiIndex, make sure to append that to the end of the line of code like this:

3) Select Columns by Data Type
For this section I'm going to use another DataSet (which you can find in the repository's "data" folder):
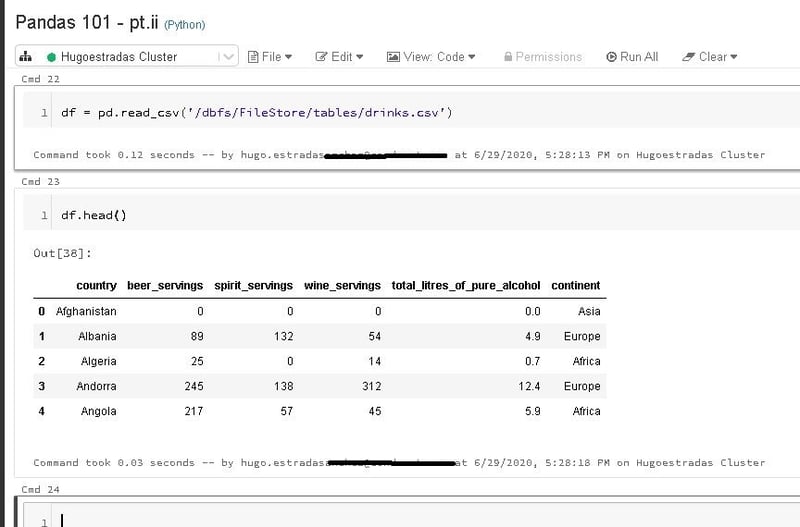
Let's start by checking all the data types of the DataFrame:

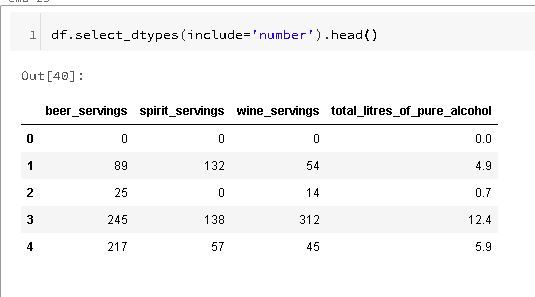
If you're interested exclusively in numeric columns, use the "select_dtypes" method:
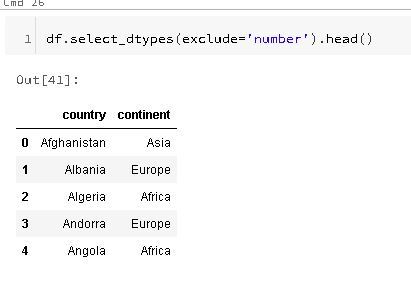
Or... maybe the opposite of that:
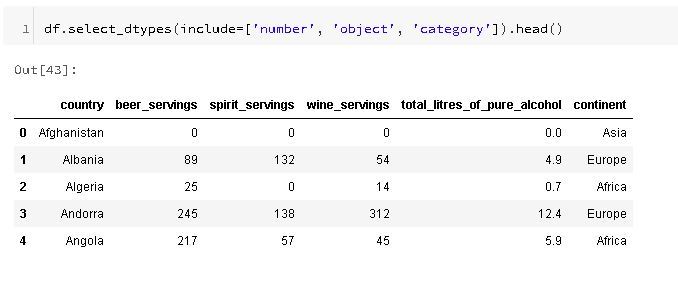
You can even be more specific, by creating a list of each data type you're interested in the DataFrame:
4) Reduce the DataFrame Size
The Pandas DataFrames are designed to fit into memory, and sometimes it's necessary to reduce the size of the DataFrame to smoothly work with it.
Let's start by getting the current size of the DataFrame:
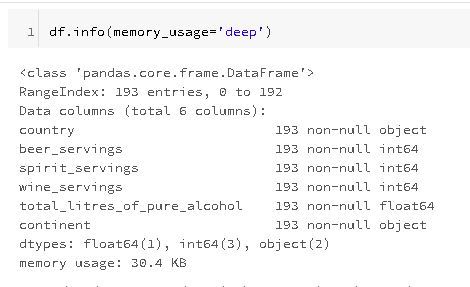
Currently it is using 30.4KB.
This is a very small DataFrame, but if just so happens you're experiencing performance problems, or you're not able to read the DataFrame these are the steps to follow to reduce the size of the DataFrame.
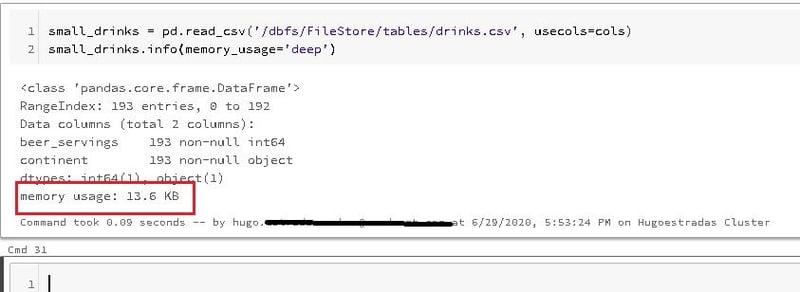
First let's reduce only the columns that you really need to work, you can do this by creating a list of them:

After that, simply recreate the DataFrame with the columns you specified, and see how it considerably reduces its size (from 30.4KB to 13.6BK):
Posted on June 29, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related
