Pandas 101 - pt. I: Introduction to Data Structures

Hugo Estrada S.
Posted on June 28, 2020


First things first, the repository with all the notebooks of this three-part series about Pandas is here:
In case you've been living under a rock these past 7 years, the Pandas library is known for its easy-to-use data analysis capabilities.
As a matter of fact, its name does not come from the black and white Chinese bear, but from the abbreviation for "Panel Data", a fancy econometrics term for data sets that include observations over multiple time periods for the same individuals, more about that in this document:
https://www.dlr.de/sc/Portaldata/15/Resources/dokumente/pyhpc2011/submissions/pyhpc2011_submission_9.pdf
It comes with cool features such as loading data from multiple formats, function renaming, mapping and plotting data, data structures, advanced indexing, DataFrame joining and data aggregation features, a comprehensive I/O API... just to name a few.
There are two major data-structures within the Pandas library: Series and DataFrame.
1) Pandas Series
A "Series" object is an array with indexed data.
Here's an example of a series object on Python using Pandas:
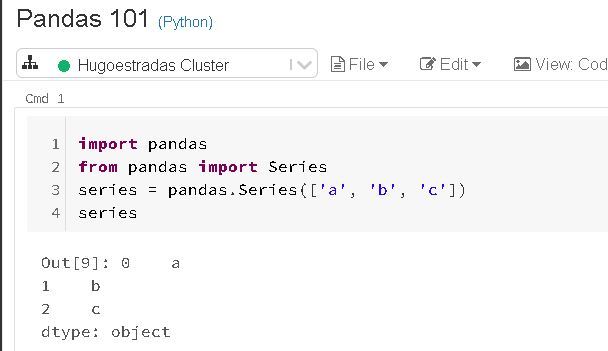
In this example, the output shows the index (position) on the left and the values on the right.
If you do not specify an index, Pandas will use the default one.
Also if you might need to, it is possible to create a Series object with a label pointing to each data:
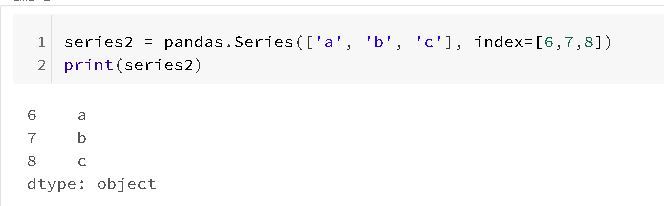
And you can even use these labels in the array to select a particular value from the series object:

Adding complexity to the examples, if you just so happens need to apply mathematical operations to the Series object, you can make use of NumPy (another Python library for scientific computing and mathematical operations).
For example, preserving the index-value link:
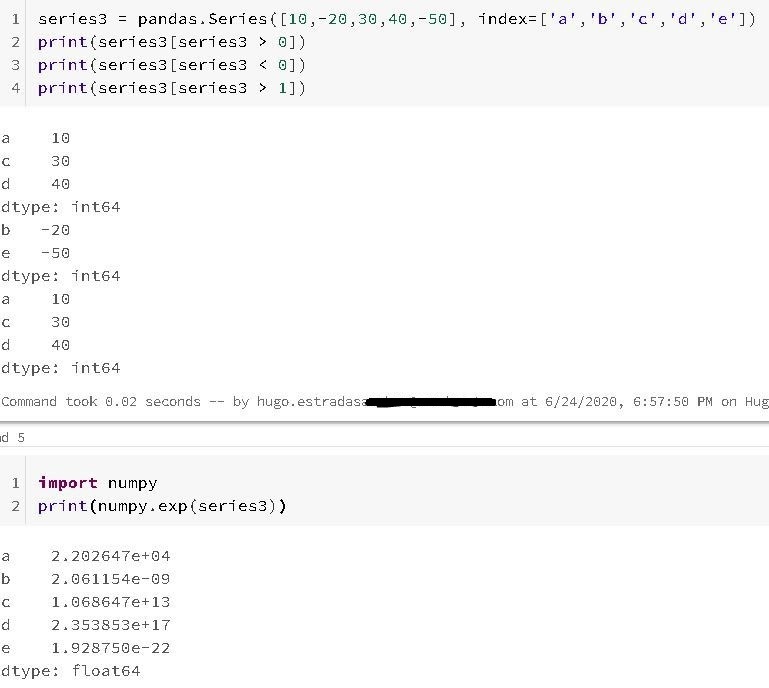
One common usage of the Series, is to create specialized dictionaries.
A dictionary is another form of data structure that maps arbitrary keys to a set of arbitrary values.
In the following example it is shown how to combine both structures to create a Series-as-Dictionary object:
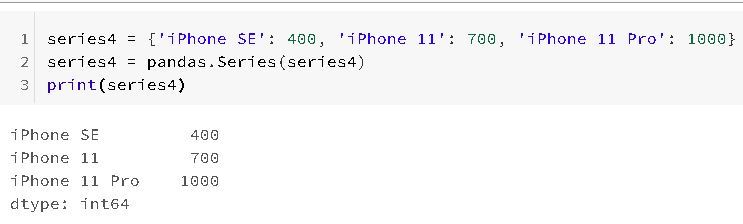
By default, a String will be created where the index is extracted from the ordered keys. From here, you can make typical access to dictionary style elements:
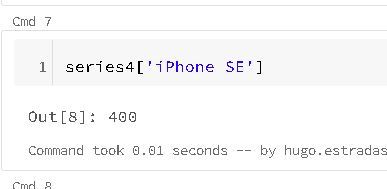
But Unlike a dictionary, Pandas Series also supports array-style operations such as slicing:
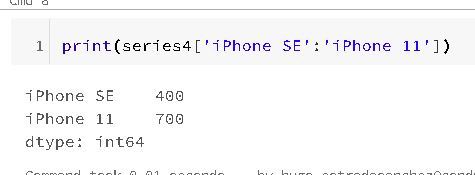
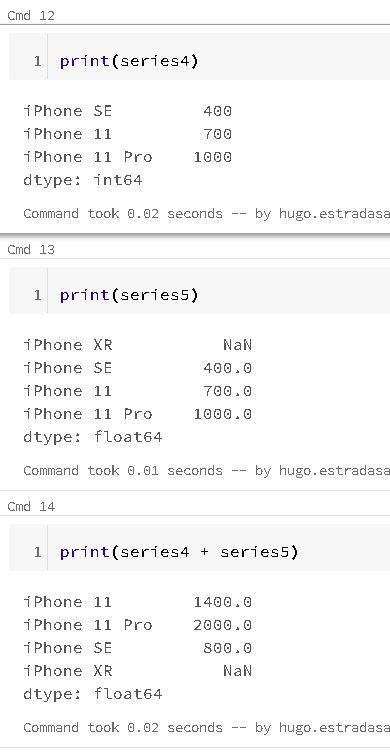
If you are passing a dict, the index in the resulting series will have this dict's key in sorted order. So it is possible to override this by passing the dict keys in the order you want them to be in the resulting Series:
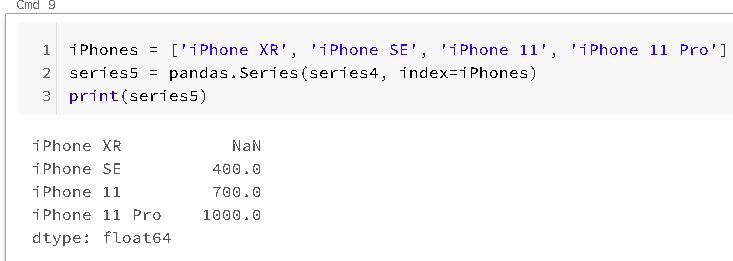
If you noticed I intentionally added one value that is not in the series4: "iPhone XR", hence Pandas mark its value in series5 as "Not a Number" (NAN). If you're interested into diving in this specific matter, here's the specific Pandas documentation for NAN values: https://pandas.pydata.org/pandas-docs/stable/user_guide/missing_data.html
Now the question you should be asking is: "how do I deal with missing data in Pandas Series (or in general)?"
The answer, the "isnull" and "notnull" functions:
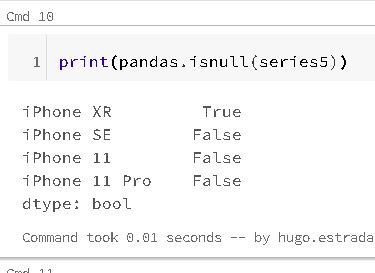
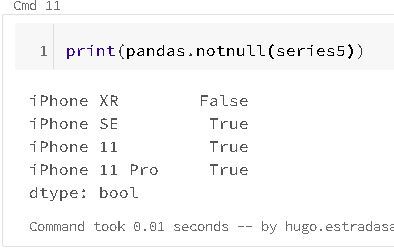
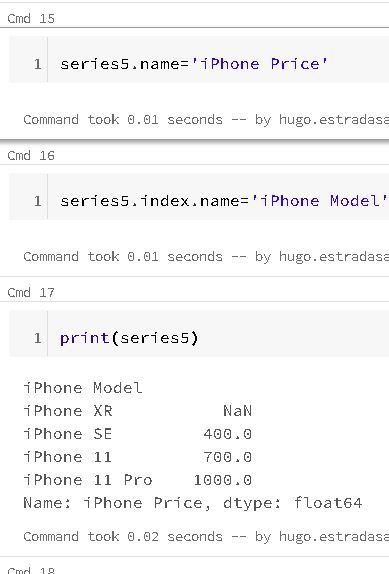
The functions are automatically aligned according to the index name when working with arithmetic operations, and both the series object itself and its index have a name attribute:
2) Pandas DataFrame
So Pandas Series are useful, but in a real world scenario it's very uncommon to work with just a simple array of data when analyzing a tons of data for a new project.
Let's talk about what is a DataFrame.
I'm going to leave the official documentation from the Pandas website, so you can read more a bout on your own what exactly is a DataFrame in the Pandas world: https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.html?highlight=dataframe#pandas.DataFrame
OK, in a nutshell: "A Pandas DataFrame is a two-dimensional, size-mutable, potentially heterogeneous tabular data structure with labeled axis".
So put it in more humble words, a DataFrame is a kind of like table from a relational database, with the twist that instead of being stored in an schema, disk, file-system, etc, this one stored in memory, during the time you need or you keep running the kernel upon your entire notebook is running.
Remember that Pandas is just a big Python library, not a "data store" in the way a RDBMS is, a Pandas DataFrame is not a data persistence tool.
Ok, hope the above text was useful, now let's get into some code.
I'm going to create some Pandas Series, and then transform them into a single Pandas DataFrame:
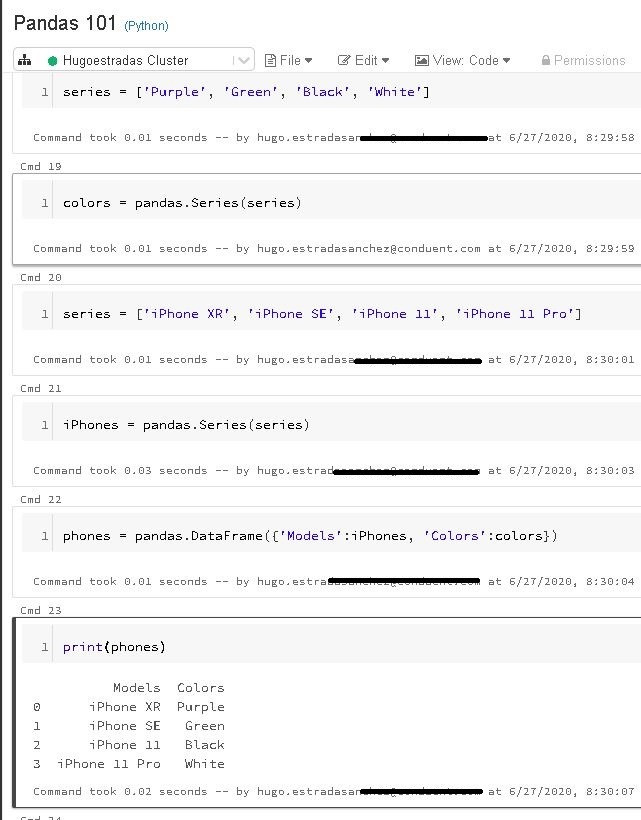
Let's analyze this section of the notebook cell by cell:
First I'm creating an array called "series" which later on I'm converting into a Pandas Series:

Then, I'm repeating the same process using the same "series" array with a new Series called "iPhones":
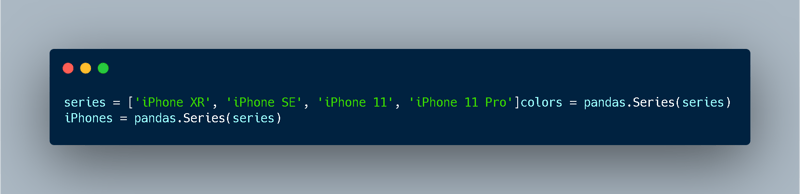
Now, basically I have 2 new Pandas Series, "colors" and "iPhones", and what I'm doing in the last 2 cells of the above image of my Databricks Notebooks, is merging these two series into a Pandas DataFrame with 2 columns, "Models" and "Colors":

Notice that the result it's pretty much very self-explanatory, a two-dimensional table-like structure created from 2 different series with the same number of elements:

Without the Series, the creation of the same DataFrame should look like this:
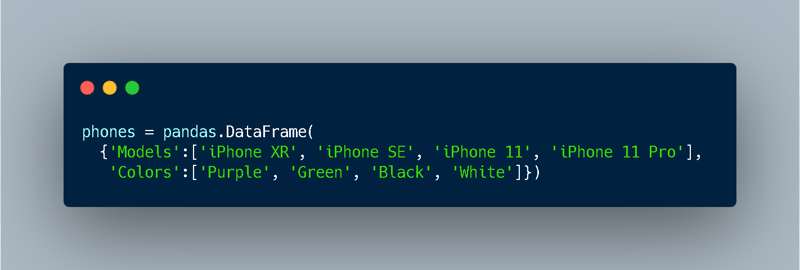
So it's like creating the "colors" and "iPhones" series within a single pair of parenthesis and curly brackets.
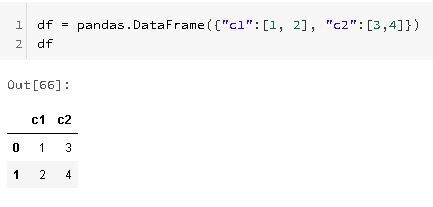
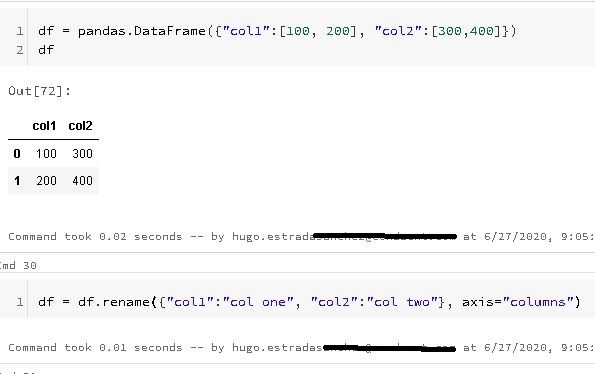
Now, there a lot of ways of creating Pandas DataFrames, one particularly interesting way of do it, is by passing a dictionary to the DataFrame constructor, in which the dictionary keys, are the column names and the dictionary values are lists of column values:
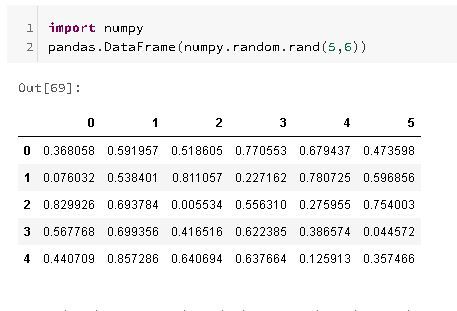
Moving forward, adding more complexity for a much larger Pandas DataFrame, you can use the NumPy library (used for working with arrays, linear algebra, fourier transform, and matrices)
using the "random.rand" function, to tell the number of rows and columns:
For non-numeric columns, it is possible to use a list of strings:

You can even rename the names of the columns at will, if just so happens that the DataFrame does not have proper naming in its columns, or you just want to rename them for a more formal or pleasing nomenclature:
Posted on June 28, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related
