Become a DevOps in 2021 pt. 1

Hugo Estrada S.
Posted on March 7, 2021

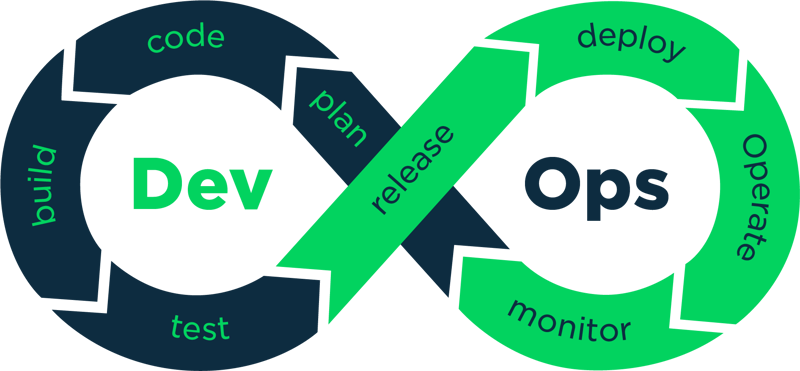
The DevOps Concept
DevOps is the combination of cultural philosophies, practices, and tools that increases an organization’s ability to deliver applications and services at high velocity: evolving and improving products at a faster pace than organizations using traditional software development and infrastructure management processes. This speed enables organizations to better serve their customers and compete more effectively in the market.
How DevOps Works
Under a DevOps model, development and operations teams are no longer “siloed.” Sometimes, these two teams are merged into a single team where the engineers work across the entire application lifecycle, from development and test to deployment to operations, and develop a range of skills not limited to a single function.
In some DevOps models, quality assurance and security teams may also become more tightly integrated with development and operations and throughout the application lifecycle. When security is the focus of everyone on a DevOps team, this is sometimes referred to as DevSecOps.
These teams use practices to automate processes that historically have been manual and slow. They use a technology stack and tooling which help them operate and evolve applications quickly and reliably. These tools also help engineers independently accomplish tasks (for example, deploying code or provisioning infrastructure) that normally would have required help from other teams, and this further increases a team’s velocity.
Benefits of DevOps:
Speed
Rapid delivery
Reliability
Improved collaboration
Security
Continuous Integration
Continuous integration is a software development practice where developers regularly merge their code changes into a central repository, after which automated builds and tests are run. The key goals of continuous integration are to find and address bugs quicker, improve software quality, and reduce the time it takes to validate and release new software updates.
Continuous Delivery
Continuous delivery is a software development practice where code changes are automatically built, tested, and prepared for a release to production. It expands upon continuous integration by deploying all code changes to a testing environment and/or a production environment after the build stage. When continuous delivery is implemented properly, developers will always have a deployment-ready build artifact that has passed through a standardized test process.
Infrastructure as Code
Infrastructure as code is a practice in which infrastructure is provisioned and managed using code and software development techniques, such as version control and continuous integration. The cloud’s API-driven model enables developers and system administrators to interact with infrastructure programmatically, and at scale, instead of needing to manually set up and configure resources. Thus, engineers can interface with infrastructure using code-based tools and treat infrastructure in a manner similar to how they treat application code. Because they are defined by code, infrastructure and servers can quickly be deployed using standardized patterns, updated with the latest patches and versions, or duplicated in repeatable ways.
Communication and Collaboration
Increased communication and collaboration in an organization is one of the key cultural aspects of DevOps. The use of DevOps tooling and automation of the software delivery process establishes collaboration by physically bringing together the workflows and responsibilities of development and operations. Building on top of that, these teams set strong cultural norms around information sharing and facilitating communication through the use of chat applications, issue or project tracking systems, and wikis. This helps speed up communication across developers, operations, and even other teams like marketing or sales, allowing all parts of the organization to align more closely on goals and projects.
Learn a Programming Language
DevOps teams can choose from many available programming languages. All languages have both strengths and weaknesses -- some inherent to the language itself, and others dependent on a given application or context in which the language is used.
DevOps explores the intersection between software development and traditional IT operations. While developers work most closely with programming languages, IT ops admins and DevOps engineers still need some level of familiarity with the languages used in their organizations to, for example, handle integrations and develop scripts.
There are some general tradeoffs to consider when choosing a programming language. For example, many IT operations admins use scripted or interpreted languages, as they enable rapid development. Compared to compiled languages, however, interpreted languages have a slower execution speed.
In addition, some programming languages are statically typed, while others are dynamically typed. Statically typed languages check data types for errors at compile time -- which results in fewer errors at runtime; dynamically typed languages don't check for errors until runtime. Statically typed languages also require DevOps teams to define variables before use -- something dynamic typing does not require.
Go
Golang, also known as “Go,” is a compiled language, fast and high-performance language intended to be simple and is designed to be easy to read and understand. Go was created at Google by Rob Pike, Robert Griesemer, and Ken Thompson, and it first appeared in Nov 2009.
The syntax of Golang is designed to be highly clean and accessible.
Here is a classic “hello world” example code with Golang:

Python
What’s Python’s role in DevOps? Python is one of the primary technologies used by teams practicing DevOps. Its flexibility and accessibility make Python a great fit for this job, enabling the whole team to build web applications, data visualizations, and to improve their workflow with custom utilities. On top of that, Ansible and other popular DevOps tools are written in Python or can be controlled via Python.
Unlike Go, Python has been around for a very long time. Python is an interpreted language, which means it is evaluated at runtime, but it supports quick development speeds -- a notable advantage in a fast-moving DevOps environment. Additionally, Python is very flexible, as it's a dynamically typed language; this enables it to interface with a variety of other tools within a DevOps workflow.
However, because it's an interpreted language, Python has a more complicated prerequisite setup and slower execution speed. The nature of dynamic typing can also introduce runtime errors more easily.
Here is a classic “hello world” example code with Python.

C and C++
Both the C and C++ languages have a long and storied history. Powerful and developed extensively, these languages offer unparalleled capability across a variety of OSes. Execution speed and low-level access are among the most desirable features. C is a classic low-level procedural language, while C++ is a superset of C that offers object-oriented features on top.
Disadvantages include the languages' complexity, need for manual memory management, longer build times and the challenge to configure compilers correctly for the organization's needs.
Here is a classic “hello world” example code with C++:

Ruby
The biggest advantage of Ruby -- another interpreted language -- is its simplicity, as well as the industry's diverse support for Ruby Gems, or modules. Ruby's simplicity enables the rapid development and implementation of necessary scripts for DevOps processes.
Ruby, however, often has a slower execution speed, not only in terms of general performance, but also for boot speed in certain circumstances. Finally, if an IT organization uses Ruby for database access, its tight Active Record coupling means that admins might lose necessary flexibility, depending on the requirements.
Here is a classic “hello world” example code with Ruby:

Linux Basics
Modern Linux and DevOps have much in common from a philosophy perspective. Both are focused on functionality, scalability, as well as on the constant possibility of growth and improvement. While Windows may still be the most widely used operating system, and by extension the most common for DevOp practitioners, it is not the preferred OS by many. That honor goes to Linux. There are many DevOp practitioners who would like to try Linux for a variety of reasons but do not know exactly which distribution to use. This is a common problem and one that stems from a poor understanding of what each distribution offers.
No single distribution can be considered the best. One of the core principles behind Linux is customization. Different distributions, or versions, of Linux, can be created depending on the exact needs of a particular individual or group much the same way different cryptocurrencies are based on the same blockchain technology but with minor changes to fulfill specific functions; take Ethereum classic vs Ethereum for example.
DevOps and Linux
As previously mentioned, Linux and DevOps share very similar philosophies and perspectives; both are focused on customization and scalability. The customization aspect of Linux is of particular importance for DevOps. It allows for design and security applications specific to a particular development environment or development goals to be created. There is much more freedom over how the operating system functions compared to Windows. Another item of convenience is that most Software delivery pipelines use Linux based servers. If the DevOps team is using a Linux based operating system they can do all testing in house and with extreme ease.
Because the Linux Kernel can process huge amounts of memory any Linux based system is highly scalable. If the hard drive or other hardware requirements change during the development process these requirements can be added without losing processing power. The same cannot always be said of Windows.
There are many good reasons why DevOps practitioners should implement Linux distributions in their workplace. The benefits far outweigh the negatives and it can ultimately lead to a smoother, more efficient development environment. This being said, choosing the right distribution is not always easy. One must properly identify what exact requirements need to be fulfilled before making the decision.
As development requirements become more demanding, especially with the rise in cloud computing software, many more developers will begin turning to Linux not only for its customization and scalability but also because of its efficiency and superior processing capabilities compared to Windows and Apple.
Best Linux Distros for DevOps
Ubuntu
CentOS
Fedora
Cloud Linux OS
Debian
Shell Commands
$ ls
This command lists all the contents in the current working directory.
ls
By specifying the path after ls, the content in that path will be displayed.
ls -l
Using the ‘l’ flag, lists all the contents along with its owner settings, permissions & time.
ls -a
Using ‘a’ flag, lists all the hidden contents in the specified directory.
$sudo
The sudo command allows you to run programs with the security privileges of another user (by default, as the superuser). It prompts you for your personal password and confirms your request to execute a command by checking a file, called sudoers , which the system administrator configures.
sudo useradd
Adding a new user.
sudo passwd
Setting a password for the new user.
sudo userdel
Deleting the user.
sudo groupadd
Adding a new group.
sudo groupdel
Deleting the group.
sudo usermod -g
Adding a user to a primary group.
$ cat {flag}
This command can read, modify or concatenate text files. It also displays file contents.
cat -b
This adds line numbers to non-blank lines.
cat -n
This adds line numbers to all lines.
cat -s
This squeezes blank lines into one line.
cat –E
This shows $ at the end of line.
$ grep {filename}
It’s used to search for a string of characters in a specified file. The text search pattern is called a regular expression. When it finds a match, it prints the line with the result. The grep command is handy when searching through large log files.
grep -i
Returns the results for case insensitive strings.
grep -n
Returns the matching strings along with their line number.
grep -v
Returns the result of lines not matching the search string.
grep -c
Returns the number of lines in which the results matched the search string.
$ sort {filename}
It’s used to sort a complete file by arranging the records in a specific order. By default, the sort command sorts files assuming that the contents are ASCII characters. The file is sorted line by line, and the blank space is used as the field separator.
sort -r
The flag returns the results in reverse order.
sort -f
The flag does case insensitive sorting.
sort -n
The flag returns the results as per numerical order.
$ head
The head command is a command-line utility for outputting the first part of files given to it via standard input. It writes results to standard output. By default head returns the first ten lines of each file that it is given.
$ tail
It is complementary to head command. The tail command, as the name implies, prints the last N number of data of the given input. By default, it prints the last 10 lines of the specified files. If you give more than one filename, then data from each file precedes by its file name.
$ chown
Different users in the operating system have ownership and permission to ensure that the files are secure and put restrictions on who can modify the contents of the files. In Linux there are different users who use the system:
Each user has some properties associated with them, such as a user ID and a home directory. We can add users into a group to make the process of managing users easier.
A group can have zero or more users. A specified user is associated with a “default group”. It can also be a member of other groups on the system as well.
Ownership and Permissions: To protect and secure files and directories in Linux we use permissions to control what a user can do with a file or directory. Linux uses three types of permissions:
Read: This permission allows the user to read files and in directories, it lets the user read directories and subdirectories stores in it.
Write: This permission allows a user to modify and delete a file. Also, it allows a user to modify its contents (create, delete and rename files in it) for the directories. Unless you give the execute permission to directories, changes do not affect them.
Execute: The write permission on a file executes the file. For example, if we have a file named sh so unless we don’t give it execute permission it won’t run.
Types of file Permissions:
User: This type of file permission affects the owner of the file.
Group: This type of file permission affects the group which owns the file. Instead of the group permissions, the user permissions will apply if the owner user is in this group.
Other: This type of file permission affects all other users on the system.
To view the permissions we use:
ls -l
The chown command is used to change the file Owner or group. Whenever you want to change ownership you can use the chown command.
$ chmod {filename}
This command is used to change the access permissions of files and directories.
$ lsof [option] [username]
While working in the Linux/Unix system there might be several files and folders which are being used, some of them would be visible and some not. lsof command stands for List Of Open File. This command provides a list of files that are opened. Basically, it gives the information to find out the files which are opened by which process. With one go it lists out all open files in the output console.
$ id [option]… [user]
It’s used to find out the user and group names and numeric IDs (UID or group ID) of the current user or any other user in the server. This command is useful to find out the following information as listed below:
User name and real user id.
Find out the specific Users UID.
Show the UID and all groups associated with a user.
List out all the groups a user belongs to.
Display security context of the current user.
Options:
-g: Print only the effective group id.
-G: Print all Group IDs.
-n: Prints name instead of a number.
-r: Prints real ID instead of numbers.
-u: Prints only the effective user ID.
–help: Display help messages and exit.
–version: Display the version information and exit.
$ cut
It’s used for extracting a portion of a file using columns and delimiters. If you want to list everything in a selected column, use the “-c” flag with the cut command. For example, let's select the first two columns from our demo1.txt file.
$ sed
Sed is a text-editor that can perform editing operations in a non-interactive way. The sed command gets its input from standard input or a file to perform the editing operation on a file. Sed is a very powerful utility and you can do a lot of file manipulations using sed. I will explain the important operation you might want to do with a text file.
If you want to replace a text in a file by searching it in a file, you can use the sed command with a substitute “s” flag to search for the specific pattern and change it. For example, lets replace “mikesh” in test.txt file to “Mukesh”
$ diff
It’s used to find the difference between two files. This command analyses the files and prints the lines which are not similar. Let's say we have two files, test and test1. you can find the difference between the two files using the following command.
$ history
It’s used to view the previously executed command. This feature was not available in the Bourne shell. Bash and Korn support this feature in which every command executed is treated as the event and is associated with an event number using which they can be recalled and changed if required. These commands are saved in a history file. In Bash shell history command shows the whole list of the command.
$ dd
It’s a command-line utility for Unix and Unix-like operating systems whose primary purpose is to convert and copy files.
$ find
command in UNIX is a command-line utility for walking a file hierarchy. It can be used to find files and directories and perform subsequent operations on them. It supports searching by file, folder, name, creation date, modification date, owner and permissions. By using the ‘-exec’ other UNIX commands can be executed on files or folders found.
$ free [option]
In LINUX, there exists a command-line utility for this and that is free command which displays the total amount of free space available along with the amount of memory used and swap memory in the system, and also the buffers used by the kernel.
Free command without any option shows the used and free space of swap and physical memory in KB.
When no option is used then free command produces the columnar output as shown above where column:
Options for free command:
-b, – -bytes :It displays the memory in bytes.
-k, – -kilo :It displays the amount of memory in kilobytes(default).
-m, – -mega :It displays the amount of memory in megabytes.
-g, – -giga :It displays the amount of memory in gigabytes.
$ ssh-keygen
Use the ssh-keygen command to generate a public/private authentication key pair. Authentication keys allow a user to connect to a remote system without supplying a password. Keys must be generated for each user separately. If you generate key pairs as the root user, only the root can use the keys.
ip [ OPTIONS ] OBJECT { COMMAND | help }
The ip command in Linux is present in the net-tools which is used for performing several network administration tasks.This command is used to show or manipulate routing, devices, and tunnels. This command is used to perform several tasks like assigning an address to a network interface or configuring network interface parameters. It can perform several other tasks like configuring and modifying the default and static routing, setting up a tunnel over IP, listing IP addresses and property information, modifying the status of the interface, assigning, deleting and setting up IP addresses and routes.
$ nslookup [option]
Nslookup (stands for “Name Server Lookup”) is a useful command for getting information from a DNS server. It is a network administration tool for querying the Domain Name System (DNS) to obtain domain name or IP address mapping or any other specific DNS record. It is also used to troubleshoot DNS related problems.
$ curl [options] [URL...]
curl is a command-line tool to transfer data to or from a server, using any of the supported protocols (HTTP, FTP, IMAP, POP3, SCP, SFTP, SMTP, TFTP, TELNET, LDAP or FILE). This command is powered by Libcurl. This tool is preferred for automation since it is designed to work without user interaction. It can transfer multiple files at once.
$ ps
Every process in Linux has a unique ID and can be seen using the command ps.
Options for the ps command:
-a: show processes for all users.
-u: display the process’s user/owner.
-x: also show processes not attached to a terminal.
$ kill
Kill command in Linux (located in /bin/kill), is a built-in command which is used to terminate processes manually. This command sends a signal to a process that terminates the process. If the user doesn’t specify any signal which is to be sent along with the kill command then the default TERM signal is sent that terminates the process.
$ df and $ du
The df (disk free) command reports the amount of available disk space being used by file systems. The du (disk usage) command reports the sizes of directory trees inclusive of all of their contents and the sizes of individual files.
The aim is to make sure you are not overshooting the 80% threshold. If you exceed the threshold it’s time to scale or clean-up the mess, because running out of resources you have to change your application shows some fickle behavior.
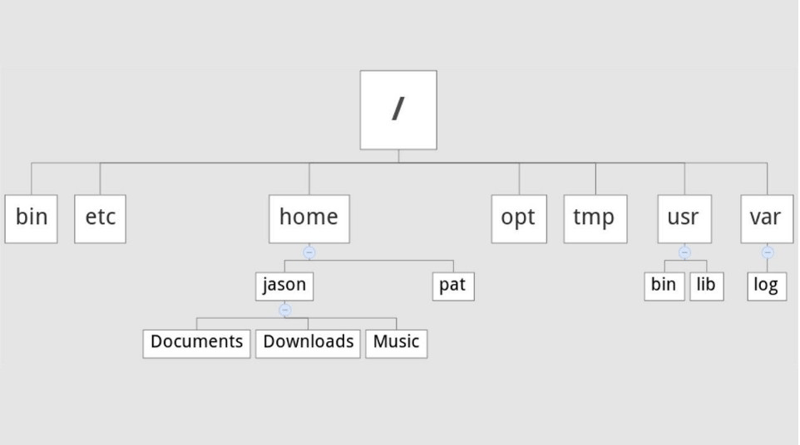
Linux Directory Structure
The directory separator in Linux is the forward slash (/). When talking about directories and speaking directory paths, “forward slash” is abbreviated to “slash.” Often the root of the file system is referred to as “slash” since the full path to it is /. If you hear someone say “look in slash” or “that file is in slash,” they are referring to the root directory.
/: The directory is called “root.” It is the starting point for the file system hierarchy. Note that this is not related to the root, or superuser, account.
/bin: Binaries and other executable programs.
/etc: System configuration files.
/home: Home directories.
/opt: Optional or third party software.
/tmp: Temporary space, typically cleared on reboot.
/usr: User related programs.
/var: Variable data, most notably log files.
Directory /bin
The /bin directory is where you will find binary or executable files. Programs are written in source code which is human readable text. Source code is then compiled into machine readable binaries. They are called binaries because machine code is a series of zeros and ones. The import thing to know is that commands, programs, and applications that you can use are sometimes located in /bin.
Directory /etc
Configuration files live in the /etc directory. Configuration files control how the operating system or applications behave. For example, there is a file in /etc that tells the operating system whether to boot into a text mode or a graphical mode.
Directory /home
User home directories are located in /home. If your account name is “pat” your home directory will be /home/pat. Linux systems can and often do have multiple user accounts. Home directories allow each user to separate their data from the other users on the system. The pat directory is known as a subdirectory. A subdirectory is simply a directory that resides inside another directory.
Directory /opt
The /opt directory houses optional or third party software. Software that is not bundled with the operating system will often been installed in /opt. For example, the Google Earth application is not part of the standard Linux operating system and gets installed in the /opt/google/earth directory.
Directory /tmp
Temporary space is allocated in /tmp. Most Linux distributions clear the contents of /tmp at boot time. Be aware that if you put files in /tmp and the Linux system reboots, your files will more than likely be gone. The /tmp directory is a great place to store temporary files, but do not put anything in /tmp that you want to keep long term.
Directory /usr
The /usr directory is called “user.” You will find user related binary programs and executables in the /usr/bin directory.
Directory /var
The /usr directory is called “user.” You will find user related binary programs and executables in the /usr/bin directory.
Linux Directory Tree
SSH Management
SSH stands for Secure Shell and it is a protocol that is used to securely access a remote server on a local network or internet for configuration, management, monitoring, and troubleshooting, etc.
Official SSH Guide
https://www.ssh.com/ssh/command/
Networking Layers OSI Model
The Open System Interconnection model (OSI) is a seven layer model used to visualize computer networks. The OSI model is often viewed as complicated and many fear having to learn the model. However, the OSI model is an extremely useful tool for development and problem solving. Each of the seven layers goes up in increments of one as it gets closer to the human user. Layer one — the application layer, is closest to the person while layer seven — the physical layer is where the network receives and transmits raw data. The OSI model belongs to the International Organization for Standards (ISO) and is maintained by the identification ISO/IEC 7498–1. In this post, each of the seven layers of the OSI model will be explained in simple terms. The layers will be explained from layer seven to layer one, as this is where the data flow starts.
OSI Model Diagram

$ ip link
It’s for configuring, adding, and deleting network interfaces. Use ip link show command to display all network interfaces on the system.
$ ip address
Use the ip address command to display addresses, bind new addresses or delete old ones. The man page ipad.
$ ip route
Use the IP route to print or display the routing table.
$ nmap
Nmap (“Network Mapper”) is a powerful utility used for network discovery, security auditing, and administration. Many system admins use it to determine which of their systems are online, and also for OS detection and service detection.
The default Nmap scan shows the ports, their state (open/closed), and protocols. It sends a packet to 1000 most common ports and checks for the response.
$ ping
Use ping to see if a host is alive. This super simple command helps you check the status of a host or a network segment. Ping command sends an ICMP ECHO_REQUEST packet to the target host and waits to see if it replies.
However, some hosts block ICMP echo requests with a firewall. Some sites on the internet may also do the same.
By default, ping runs in an infinite loop. To send a defined number of packets, use -c flag.
$ iperf
While ping verifies the availability of a host, iPerf helps analyze and measure network performance between two hosts. With iPerf, you open a connection between two hosts and send some data. iPerf then shows the bandwidth available between the two hosts.
You can install an iPerf using your distribution package manager.
$ traceroute
If ping shows missing packets, you should use traceroute to see what route the packets are taking. Traceroute shows the sequence of gateways through which the packets travel to reach their destination.
$ tcpdump
tcpdump is a packet sniffing tool and can be of great help when resolving network issues. It listens to the network traffic and prints packet information based on the criteria you define.
$ netstat
Netstat command is used to examine network connections, routing tables, and various network settings and statistics.
Use -i flag to list the network interfaces on your system.
$ ss
Linux installations have a lot of services running by default. These should be disabled or preferably removed, as this helps in reducing the attack surface. You can see what services are running with the netstat command. While netstat is still available, most Linux distributions are transitioning to ss command.
use ss command with -t and -a flags to list all TCP sockets. This displays both listening and non-listening sockets.
Posted on March 7, 2021
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.