Uma abordagem diferenciada à Sessões de Usuário em Microsserviços usando Redis

Jonatas de Moraes Junior
Posted on February 4, 2021

Read in english: click here
Você decidiu quebrar o seu velho e ultrapassado monolito em uma arquitetura mais moderna e eficiente de microsserviços. Um dos primeiros problemas que certamente irá surgir vem do fato de que ter uma arquitetura distribuída significa que suas novas pequenas peças não estão mais amarradas umas às outras, elas vão precisar se conversar através de serviços e não mais conseguirão compartilhar áreas de memória. Bem, acontece que um dos dados mais importantes da sua aplicação era mantido em memória e compartilhado entre todos os módulos da aplicação: a sessão do usuário.
Quando você faz uma pesquisa rápida sobre autenticação e autorização em microsserviços, uma certa tecnologia aparece como sendo a melhor, senão a única, solução: JWT. Basicamente, essa abordagem sugere que você coloque todos os seus dados de sessão em um hash assinado e encriptado (a token) e envie isso de volta para o cliente que se logou na sua aplicação. Então, a cada requisição, o cliente deve enviar de volta essa token (geralmente no cabeçalho da requisição), e então podemos verificar a autenticidade dessa token e extrair dela os dados da sessão. Com os dados em mãos, podemos enviá-los para qualquer serviço que necessite deles até que a requisição seja respondida. Podemos subir uma função serverless para desencriptar e verificar a assinatura da token, ou até mesmo delegar essa tarefa para o nosso API Gateway.
Parece muito bonito e elegante à primeira vista, mas espera um pouco ... isso está parecendo bem mais complexo do que costumava ser, certo? Vamos dar uma olhada em como isso funcionava no nosso monolito, e porquê teve que mudar tão drasticamente.
Os velhos tempos
Antigamente, sessões de usuário em HTTP eram armazenadas na memória do servidor, indexadas por um hash gerado aleatoriamente e que não tinha significado - inclusive o termo "token opaca" surgiu pra identificar essa token sem dado algum nela. Essa token sem dados era então enviada de volta ao browser, e o servidor gentilmente pedia a ele que salvasse esta token em um Cookie.
Pela sua natureza, os Cookies são automaticamente enviados de volta ao servidor a cada requisição feita posteriormente, então depois de o usuário estar logado, a próxima requisição ao mesmo servidor certamente irá conter o cookie, que por sua vez irá conter a token necessária para recuperar os dados do usuário da memória do servidor.
Essa abordagem vem sendo utilizada por mais de uma década por vários servidores de nível enterprise (jboss, weblogic, etc), e é considerada segura. Mas agora nós temos microsserviços, então não podemos contar mais com isso, pois cada serviço é isolado dos outros, então não temos mais uma área comum para armazenar esses dados.
A solução então, conforme proposta, é enviar os dados ao cliente, deixá-lo com a responsabilidade de guardar esses dados, e enviá-los de volta quando necessário. Isso apresenta uma enorme quantidade de problemas que não tínhamos antes, e eu vou tentar explicar alguns deles agora:
Problemas de segurança
A maioria das implementações com JWT sugere que você envie a token do cliente de volta ao servidor através de um cabeçalho HTTP chamado "Authorization". Para poder fazer isso, o seu client precisa ter a capacidade de receber, armazenar e recuperar a token. O problema é, se o client tem acesso a esses dados, então qualquer código malicioso também tem. De posse da token, o malfeitor pode tentar decriptá-la para visualizar os dados, ou apenas utilizá-la para obter acesso à aplicação.
No monolito, o servidor simplesmente enviava a token opaca ao browser em um cabeçalho HTTP chamado SetCookie, então o código no cliente não precisava lidar com a informação pois o browser faz isso automaticamente. Até mesmo o cookie pode ser setado de uma forma que sequer possa ser acessado via javascript, sendo assim códigos maliciosos jamais conseguiriam acesso.
Problemas de performance
Para poder manter tudo seguro, você deve assinar a token rodando um algoritmo de criptografia para que ninguém possa alterar seu conteúdo, e também encriptar a token pra ter certeza de que ninguém poderá ler facilmente esse conteúdo.
Além disso, pra cada requisição recebida no servidor, o mesmo deverá rodar a desencriptação da token, bem como rodar novamente o algoritmo de criptografia que gera a assinatura a fim de verificar sua validade. Todos nós sabemos o quanto esses algoritmos de criptografia são custosos computacionalmente, e nada disso era necessário no nosso velho monolito, salvo pela única execução no momento de comparar as senhas durante o login - mas essa execução também é necessária quando se usa JWT.
Problemas de usabilidade
As tokens JWT não são muito boas em controlar expiração de sessão por inatividade. Quando se gera uma token, ela é dada como válida até a sua data de expiração, que é armazenada na própria token. Ou seja, ou você gera uma nova token a cada requisição, ou você gera uma outra token chamada de Refresh Token com uma expiração maior, e a utiliza unicamente para conseguir uma nova token quando a sua expirar. Mas perceba, isso só transfere o problema de um lugar para outro - a sessão de fato expirará quando a Refresh Token expirar, a menos que você também a atualize.
Como você pode perceber, a solução proposta traz consigo uma série de problemas não resolvidos. Mas como então podemos conseguir um gerenciamento de sessão de usuário efetivo e seguro em uma arquitetura de microsserviços?
Trazendo velhos conceitos ao novo mundo
Vamos nos focar no problema real: a sessão de usuário costumava ser armazenada na memória do servidor, e muitos servidores enterprise podiam replicar esse trecho de memória entre suas várias instâncias dentro do cluster, o que a tornava acessível em qualquer situação. Porém, nós mal temos servidores de aplicação hoje, sendo que a maioria dos módulos de microsserviços são aplicações standalone java / node / python / go / (escolha sua tecnologia). Como então eles irão compartilhar uma única porção de memória?
Na verdade é bastante simples: crie um servidor central de sessão.
A idéia aqui é armazenar a sessão do usuário da mesma forma que antes: deve-se gerar uma token opaca para ser usada como chave, e então pode-se adicionar a quantidade de dados que você quiser para ser indexado por essa chave. Faremos isso em um lugar que seja central e acessível por qualquer microsserviço na sua rede, sendo que quando qualquer um deles necessite dos dados, eles estarão a apenas uma chamada de distância.
A melhor ferramenta para esse trabalho é o Redis. O Redis é um banco de dados em memória que trabalha com pares chave-valor, e tem latência menor que um milissegundo. Seus microsserviços conseguirão ler os dados de sessão como se estivessem armazenados diretamente em sua própria memória (bem, quase, mas é rápido). Além disso, o Redis tem uma funcionalidade que é imprescindível pro nosso caso: conseguimos setar um timeout para um par chave-valor, sendo que assim que o tempo expira, o par é deletado do banco. O tempo pode ser resetado sob demanda. Soa exatamente como timeout de sessão, certo?
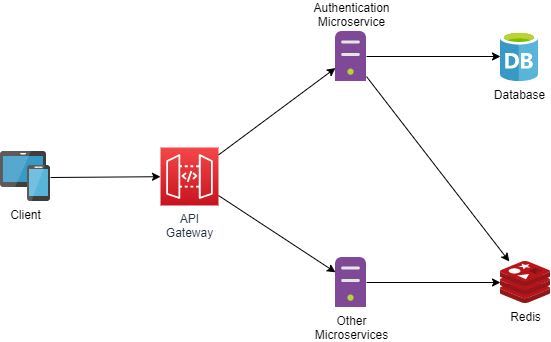
Pra tudo isso funcionar, precisaremos de pelo menos dois módulos:
1 - Módulo de autenticação
Você terá que criar um microsserviço responsável pela autenticação dos seus usuários. Ele irá receber a requisição com o login e a senha, irá checar se a senha é válida, e então criar a sessão no Redis.
Para isso ele irá gerar a token opaca, recuperar os dados do usuário do seu banco relacional (ou nosql, depende do seu caso), e então armazenar esses dados no Redis usando a token como chave. Em seguida, irá retornar a chave ao cliente que requisitou o login, de preferência em um header SetCookie caso o cliente seja um browser.
2 - Módulo de autorização
Eu particularmente prefiro que esse módulo seja parte integrante de cada um dos microsserviços, mas você pode colocá-lo dentro do seu API Gateway caso prefira. Sua responsabilidade é a de interceptar cada requisição feita, recuperar a token opaca, e com ela ir ao Redis e recuperar os dados de sessão, repassando esses dados junto com a requisição até o serviço que irá tratá-la.
Conclusão
Como você pode perceber, a solução aqui proposta é muito mais simples, rápida e segura do que utilizar JWT para gerenciar sessões de usuário. Mas tenha em mente o seguinte:
Se você estiver utilizando uma única shard do Redis, esse pode ser seu "single point of failure", ou seja, se ele falhar, você fica sem login. Eu recomendo utilizar um setup de produção mais robusto, com mais shards e replicação de dados entre eles.
Os dados de sessão podem ser modificados por qualquer módulo que tenha acesso ao Redis, sendo assim use uma abordagem de "sempre adicionar, nunca deletar", da mesma forma que era feito nos velhos tempos com o monolito.
Espero que isso ajude.
Como um bônus, deixo aqui uma classe SessionManager pra ajudar na implementação em Java usando Jedis e o gerador de token do Tomcat, que já é normalmente incluído no Spring Boot:
Bom divertimento!
Posted on February 4, 2021
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related
February 4, 2021