
Mark Harless
Posted on March 26, 2020

Today I learned how to scrape data from websites using Python and the BeautifulSoup module. I learned Ruby as my first programming language and have actually built a few scrapers in one app to gather nutritional data from foods. I used the Nokogiri gem for that project which seems very similar to BeautifulSoup. Here's how to get the price of an item's URL:
You will first have to import the BeautifulSoup and Requests module at the top of your .py file. BeautifulSoup and Pyperclip are not a standard Python module so you'll have to import them from your terminal if you haven't done so.
pip install bs4
pip install pyperclip
So your file should look like this now:
import bs4
import requests
import pyperclip
Requests allows you to send HTTP requests extremely easily while Pyperclip is used to copy or paste text into/onto your clipboard. We'll be using this to paste our Etsy URLs into our Python program.
Now, let's create part of our scraper method:
def getPrice():
res = requests.get(pyperclip.paste())
try:
res.raise_for_status()
except requests.exception.HTTPError as e:
print(e)
soup = bs4.BeautifulSoup(res.text)
# select price and return statement
Okay, so what's happening here? In the first line of our method, we are creating that HTTP call to the Etsy product link we have copied into our clipboard. What we get back from that request is called a response. For the sake of this demonstration, we'll be using this custom Settlers of Catan game board.
In the second block of our method I'm trying the next line of code res.raise_for_status(). If that returns an error, I don't want the program to continue to run because it didn't make a successful HTTP request so it returns an error instead.
If the HTTP request is successful, however, the code skips over the exception and carries on. What we get back from our response is the HTML of the Etsy page. Now, obviously, we don't want or need the entire page. We just want the price. What we need to do is dig into Chrome's inspector tool by right clicking anywhere on the Etsy product page and selecting 'inspector' from the dropdown list.
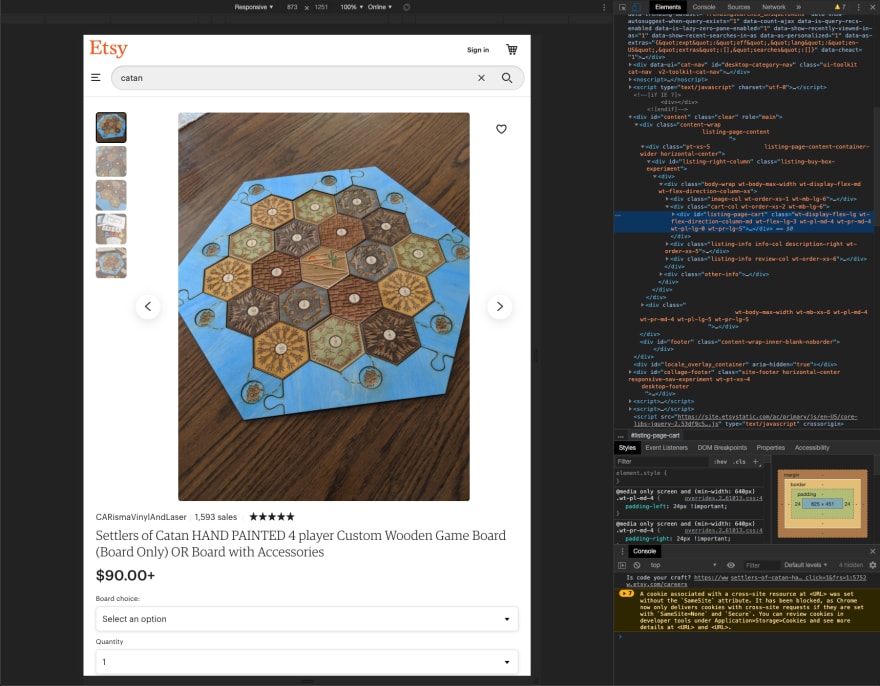
On the right-hand side you will see the webpage's HTML in its entirety. Now, click on the cursor icon located next to the 'Element' tab — besides the phone and computer icon. After clicking on it, navigate to where you see the price of the product on the actual website. Chrome will then find and highlight that section in the inspector to your right. Neat, huh?
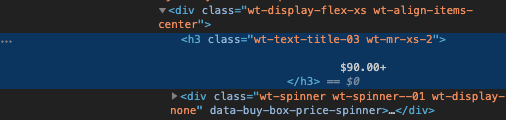
We want what's in the first line of the highlighted blue text. Let's go back to our Python program and replace our comment:
return soup.select('h3.wt-text-title-03.wt-mr-xs-2')
You can see how we translated the first line of the HTML into our select. The . indicate a class. If we saw id in our HTML we would be using # instead.
As it stands, our return statement returns the following line (you may have to scroll horizontally):
[<h3 class="wt-text-title-03 wt-mr-xs-2">\n \n $90.00+\n </h3>]
This is a huge step forward from having the entire website's HTML to a few lines but we can do better. You will see that the return is a list containing a single element so we will add [0] to the end of our return statement to select it. That will remove the brackets but there is still a lot of useless text we're getting back. To remove that we can add .text after [0]. This will remove all of the HTML and leave you with just the text that the website was showing: our price. Let's see what we get back now:
$90.00+
That's what we want! But what's with all that whitespace? We can easily remove that by adding our last bit of code .strip() to strip away any trailing or leading whitespaces. Now we will just have our price $90.00+ returned to us. Perfect!
Let's finish our program by setting the return to a variable then printing our price to the console:
price = getPrice()
print('The price of this product is ' + price)
Boom! You've just created a simple web scraper. For homework, I'm asking you to be able to have the following line print with the name of the product:
print('The price of ' + productName + ' is ' + price)
Here's our entire code (without your homework) for your notes:
import bs4
import requests
import pyperclip
def getPrice():
res = requests.get(pyperclip.paste())
try:
res.raise_for_status()
except requests.exception.HTTPError as e:
print(e)
soup = bs4.BeautifulSoup(res.text)
return soup.select('h3.wt-text-title-03.wt-mr-xs-2')[0].text.strip()
price = getPrice()
print('The price of this product is ' + price)
Posted on March 26, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related


