
Hargunbeer Singh
Posted on September 21, 2021
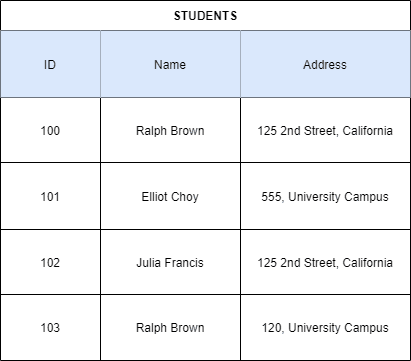
A relational database consists of rows and columns in a table, relational databases use SQL as their query language. They follow a relational data modeling paradigm. In a table, we need to uniquely identify each row, suppose it is a table of students in a university, you cannot uniquely identify a row based on the student's name as two students might have the same name, you cannot even uniquely identify a row based on the student's address as two students might be living at the same place, so you need to uniquely identify each student by a student ID that is unique to every student, this in the relational data modeling paradigm, is called the primary key, it is the key which uniquely identifies a row in a table.
In this university database analogy, you would have another table that would store the data for the classes. In the classes table, you also need a primary key that would uniquely identify each row in the table. The name of the class cannot act as the primary key as there could be two classes with the same name, likewise, the instructor cannot act as the primary key as an instructor might be teaching more than one class. So, here we would use the class id as the primary key to uniquely identify each class.

We can use the relational data modeling scheme of the relational databases to connect the two tables by their primary keys into a single table which would contain only the primary keys of both the tables. For example, we need to create a table that would store the enrollments which are the classes a student is taking. In this scenario, we could just link the primary keys of both the tables in a single table like this:

This can become complex when the number of rows of data increases so it is really difficult to scale. The new table that has been formed can be really useful as it provides us with the data about the attendees of a particular class as well as the data regarding the classes a student is taking. You can add another column to the new table formed by the merging of the primary keys of the two tables. For example, we can add a grade column to the newly formed table, and now we are having a lot of useful data in the newly formed table.
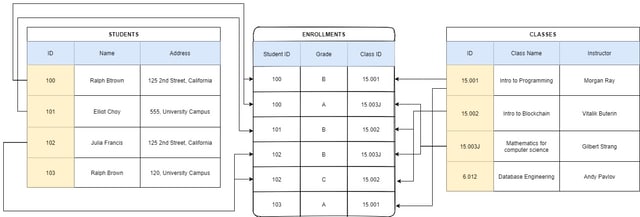
Note that the student id, as well as the class id, do not act as primary keys in the ENROLLMENTS table, and thus the enrollments table does not have a primary key, so we would go ahead and add a primary key to the enrollments table. We would use Enrollment ID as the primary key as it can uniquely identify rows of data.

The student ID is the primary key of a specific table and the class id is the primary key for a specific table. So, in the grades table, the student id is the foreign key for the students table and the class id is the foreign key for the classes table. A foreign key is a key in a table that is the primary key of another table's row. Foreign keys are really useful as you can use them to retrieve more data about a specific foreign key
For example, I am looking at the Grades table, and from there I get to know that the student with student ID 103 has only taken one class this semester, so I want to contact the student but the grades table does not have the student's address, but as the student id is a primary key of the students table, I would go on to look the students table with the primary key I found in the Grades table to fetch more information about the particular student, and there I would find student id 103's address. So the relationship between the students table and the grades table is one to many. The relationship between the Grades table and the classes table is many to one. A many to one relationship is a relationship between two tables, where many foreign keys relate to a single primary key in another table, like in this case, the same class ids in the grades table link to a single primary key in the classes table. The class ids in the grades table are the foreign keys for the classes table.
These types of relationships are formed to avoid redundant data in a database and also to avoid some other problems. As described earlier, by using foreign keys for a particular table, we can usually find more information about the particular foreign key. Foreign key relationships are possible due to the relational data modeling paradigms. What if we did not have a relation between the Grades and the Classes table and we had information about the Classes combined in the Grades table.
So, with relationship, we do not need to write all the data about a particular class in the grades table, but without a relationship, we have to write about the classes in the grades table, so a particular class id would have the same instructor and the same name which would result in redundant data. Redundant data is different as compared to duplicate data, duplicate data will have different primary keys whereas redundant data would have the same foreign key. Storing redundant data is a huge loss of space, and in this scenario, there would be hundreds of students taking the same class, thus we would have to write the instructor and the class name hundreds of times, wasting a lot of storage.
The other problem with redundant data storage is that it causes a lot of problems with updating and retrieving data from the database. So we continue the previous example, suppose the instructor for a particular class changed, you will have to change the instructor name hundreds of times in the Grades table because the name of the previous instructor has been written there multiple times. After all, there is redundant data. There are databases with millions of rows of data and updating the data in millions of rows is fatal for the speed as the CPU would be millions of times slower in completing the task as compared to updating a single row of data where the relationship between tables exists. If you do not update each row of data in a table that has redundant data, it may cause a lot of problems with retrieving data from the database.
Suppose the instructor changed and you did not update every row with the new instructor name, so when somebody wants to send an email to the instructor of a particular course, he would perform a query to the database for the specific class instructor, what if the query returns the first result which is the old data which was not updated and contained the name of the old instructor rather than the new instructor, thus causing a discrepancy in the application of the database. To avoid all this, we use relationships between different tables. There are some limitations for lots of reading and write queries per second, this is due to the relations between data and because SQL enforces ACID requirements.
Posted on September 21, 2021
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related

