Moving my serverless project to Ruby on Rails

Alex Kotliarskyi
Posted on November 24, 2020
I have a small side project: digital gift cards for hackers. It uses Shopify for all the store-related stuff: frontend, payments, refunds, reports, etc.
But unlike regular digital products (ebooks, videos) I wanted each card that the user purchases from the store to be unique. So I made a script that generate personalized images and ran it manually for every order.
The next logical step was automating this process. I started with serverless AWS Lambda. At the time it was a hot new tech and I wanted to learn more. It seemed very fitting for my use-case: single-responsibility functions that can run at any time and don’t require server maintenance.
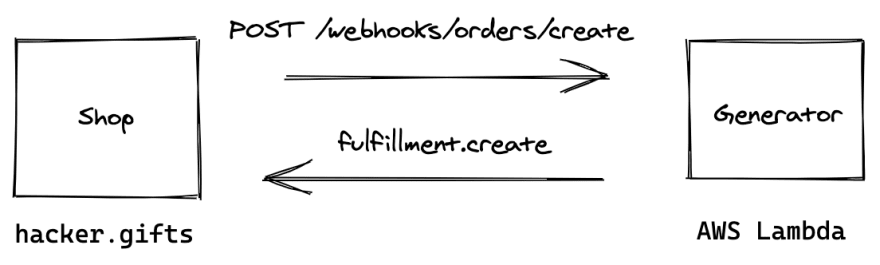
It was super easy to get started. I built a JavaScript function and deployed it to AWS Lambda, added Shopify web hook and it all worked!
Early benefits of serverless (for hobby projects):
- Easy to get started
- Don’t have to configure or maintain servers
- Free for small loads
In reality, writing the simple Lambda functions turned out to be only 10% of the work.
The time passed and my backend started getting more complex: I needed to store some state for each puzzle, send confirmation emails, show order details page. What started as a simple function, grew into a bunch of serverless functions, SNS topics, S3 buckets, DynamoDB tables. All bound together with plenty of YAML glue, schema-less JSON objects passed around and random hardcoded configs in AWS console.
I think it’s just a typical software development life-cycle: things grow organically, become a mess, and require some refactoring. Make it run first (discover market fit), then make it right (refactor to integrate the new discoveries).
But this time it was different. I couldn’t refactor things as easily as I used to in the traditional monolithic apps. Here’s why:
When the building blocks are too simple, the complexity moves into the interaction between the blocks.
And the interactions between the serverless blocks happen outside my application. A lambda publishes a message to SNS, another one picks it up and writes something to DynamoDB, the third one takes that new record and sends an email…
I could test every single block in that flow, but I didn’t have the confidence in the overall process. What if publishing fails, how would I know that? How would system recover? Can I rollback and try again? Where do the logs go?
Another swarm of problems was hiding in my configuration: bad Route 53 record, typos in SNS topics, wrong S3 bucket region. Tracing errors was a challenge, there’s no single log output I can look into.
With serverless, I was no longer dealing with my project's domain, I was dealing with the distributed system's domain.
At this point I felt fooled.
I came for the easy way to deploy code and not think about servers, but in the end had to design my system around the platform’s limitations.
Drawbacks of serverless (for hobby projects):
- Hard to follow information flow
- Impossible to replicate production environment
- Slow iteration speed
- Lack of end-to-end testing
- Immature documentation (dominated by often outdated Medium posts)
- No conventions (have to make hundreds of unessential decisions)
—
I was clearly not enjoying the serverless. So I decided to rewrite it. After all, it is a side project I’m doing for fun. The tech stack of choice — Ruby on Rails.
I haven’t used Rails since 2013, and for the last 8 years at Facebook I’ve been mostly doing JavaScript.
![]()
The experience of picking Rails back up was really nice but… uneventful. Nothing really changed that much. Few things got added, a few small things moved around.
Of course I did hit some magical Ruby issues. But unlike my typical experience with JavaScript, I was quickly able to find the solution.
Rails comes with so many things built-in and configured. Over the years without Rails I used to gluing random JavaScript libraries together to roll my own routing, file storage wrappers, email preview pipeline, managing secrets, test setup with fixtures, database migrations, logging, performance reporting, deployment scripts. With Rails I didn’t have to think about all these details and could simply focus on making product-visible changes.
It was as like driving a Tesla after years of making my own scrappy cars. Similar components, but all configured and aligned to work well together.
Benefits of Rails (for hobby projects):
- Conventions
- Tooling, libraries
- Documentation
- Monolith is easy to understand and test
Drawbacks of Rails (for hobby projects):
- Feels heavyweight in the beginning
- Hurts if your opinions differ from Rails conventions
- Have to host on a server
- Doesn’t sound cool in 2020 (anymore and maybe yet)
—
Serverless is like a black hole. It promised exciting adventures, but the gravity sucked me in and I spend most of my efforts dealing with its complexity, instead of focusing on my product.
Posted on November 24, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.