🫖 What is WebRTC? Explained in plain language

Fora Soft
Posted on September 28, 2021

The majority of WebRTC-related material is about the application level of code writing and doesn’t help understand the technology. Let’s dive deeper into the topic and find out how the connection establishes, why we need the TURN and STUN servers, and what a session descriptor and candidates are.
What is WebRTC for?
WebRTC is a browser-oriented technology that allows us to connect to clients to transmit video data. Internal browser support (external technologies, such as Adobe Flash, aren’t needed) and an ability to connect clients without using any additional servers (p2p connection) are the main peculiarities of WebRTC.
Establishing a p2p connection is complicated as computers don’t always possess public IPs (their internet addresses). Due to a low amount of IPv4 addresses and for the security’s sake, NAT was invented. It allows creating private networks, for instance, for home use. Many home routers support NAT, thus all devices that are connected to the router have internet access, although service providers usually allow one IP address. Public IPs are unique, whereas private ones aren’t, hence p2p connection is difficult.
To better understand the concept, let’s take a look at three scenarios:
- Both nodes are within the same network

- Both nodes are within different networks (private and public)

- Both nodes are within different private networks with the same IPs

The first letter in the images above represents a node type: r for a router, p for a peer.
- Image one shows a nice situation. Nodes within their networks identify with network IP addresses, and they can directly connect with each other.
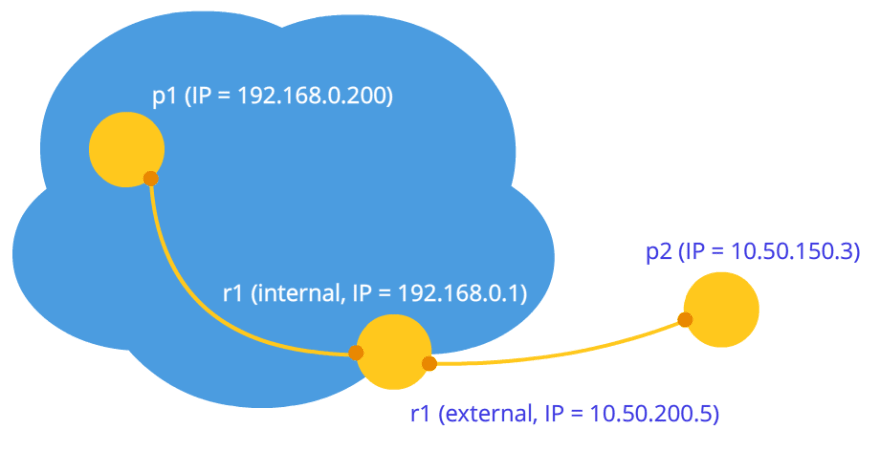
- Image two shows two different networks with similarly sequenced nodes. We introduce routers here, and they have two network interfaces: inside and outside their system. Hence, they have two IPs. Usually, nodes have only one interface, and they use it to interact within their networks, and if they transmit data to something outside their system, they only do it with the help of NAT inside of a router. That’s why these nodes appear as a router IP address – it’s their external IP. Therefore, the p1 node has an external IP (10.50.200.5) and an internal one (192.168.0.200), with the first address also being external for all other nodes within the network. The p2 node experiences similar circumstances, so their connection is impossible as long as only their internal addresses are used. It’s possible to go with external IPs, but it poses a challenge since all nodes within the same private network are under the same external address. NAT solves this problem.
- What happens if we decide to connect nodes via their internal addresses? The data won’t leave the network. To magnify the effect, imagine a situation from the third image, where both nodes have the same internal addresses. If they use those addresses to communicate with one another, they both will be communicating with themselves.
Here is where WebRTC steps in. In order to solve these problems, WebRTC uses the ICE protocol which requires additional STUN and TURN servers.
The two phases of WebRTC
In order to connect two nodes with the WebRTC protocol (or just RTC if there are two iPhones), it’s necessary to complete some preliminary steps to establish a connection. That’s the first phase. The 2nd phase is video data transmission.
Although WebRTC uses lots of means of communication (TCP and UDP) and can flexibly switch between them, this technology does not possess a protocol for transmitting connection data, which is not surprising as connecting two p2p nodes isn’t a simple task. Having said that, we need an additional, not related to WebRTC, data transmission way. It can be an HTML protocol, socket transmission, or an SMTP protocol. This way of sending initial data is a signaling mechanism. Not too much information is transmitted. The data is transmitted as text and is split into two categories: SDP and Ice Candidate (you can also read about them here) SDP is used to establish a logical connection, Ice Candidate is for a physical connection. It’s important to remember that WebRTC gives you the information that needs to be passed on to the next node. As soon as we transmit the necessary information, the nodes will be able to connect, and our help won’t be needed anymore. Therefore, a signaling mechanism which we need to create separately, will be used only upon connection and not while we transmit video data.
So, let’s take a look at the first phase. It consists of several steps. First, let’s look at it as for the connection initiating node, and then as for the connection receiving node.
- Initiator (caller):
- Receiving a local media stream and establishing its transmission (getUserMediaStream)
- An offer to begin video data transmission (createOffer)
- Receiving an own SDP object and sending it via the signaling mechanism (SDP)
- Receiving own Ice candidate objects and sending them via the signaling mechanism (Ice candidate)
- Receiving a remote media stream and showing it on the screen (onAddStream)
- Receiver (callee)
- Getting a local media stream and establishing its transmission (getUserMediaStream)
- An offer to begin video data transmission and answer creation (createAnswer)
- Receiving an own SDP object and sending it via the signaling mechanism (SDP)
- Receiving own Ice candidate objects and sending them via the signaling mechanism (Ice candidate)
- Receiving a remote media stream and showing it on the screen (on AddStream)
Only the 2nd step is different.
However complicated these steps might seem, as a matter of fact, there are just three of them: sending a local media stream (step 1), establishing the connection parameters (steps 2-4), receiving a remote media stream (step 5). The 2nd step is the most difficult one as it consists of two parts – we need to establish the logical and physical connection. The latter shows the way for the packet to follow to get from one node to the other, and the former points at video and audio parameters – what quality and codecs to use.
Connect the createOffer and the createAnswer steps to the steps with the transmission of SDP and Ice Candidate objects.
Now we are going to take a look at some entities, such as MediaStream, SDP, and Ice Candidate.
Main entities
MediaStream
MediaStream is a basic entity, it consists of video and audio data streams. There are two types of media streams, local and remote. Local streams receive data from the input devices (camera, mic), remote streams receive data from the network.
Therefore, every node has a local and a remote stream. In WebRTC, for these streams, there is a MediaStream interface, as well as a LocalMediaStream sub-interface which is out there specifically for a local stream. In JavaScript, you can only face the former one, but if you use libjingle, you can also encounter the latter.
WebRTC suggests a difficult hierarchy within a stream. Every stream consists of several media tracks (MediaTrack), which can consist of several media channels (MediaChannel). There can also be several media streams.
For example, we not only want to transmit a video of ourselves but also our table with a piece of paper on it, as we are about to write something on the piece of paper. We’ll need two videos (of us and the table) and one audio (us). Obviously, we and the table should be divided into different streams, as they aren’t really dependent on each other. That’s why we’ll have two MediaStreams: one for us and one for the table. The first one will have video and audio data, and the 2nd one – video data only.

The media stream has to provide an opportunity to keep different types of data, namely video and audio. This is accounted for in the technology, therefore every data type is realized through MediaTrack. MediaTrack has a special quality called kind which determines whether it’s a video or audio before us.

So how does everything happen inside the program? We create two media streams. Then we’ll proceed to create two video tracks and one audio track. Get access to the camera and microphone. Tell every track what feature it needs to use. Add a video and audio tracks into the first media stream and the video track from the 2nd camera – into the 2nd media stream.
How to distinguish media tracks on the other end? By the feature label that every media channel has. Media tracks have the same feature.

So, if we could identify the media tracks with a mark, why do we need to use two of them instead of one in this example? You can transmit one media stream and use different tracks within it. Now we’ve reached an important feature of media tracks, they synchronize media tracks. Different media tracks aren’t synced between each other, but all tracks are played simultaneously within each media track.
Therefore, if we want our words, facial expressions and the piece of paper to be played at the same time, we need to use the same media track. If it’s not too important, it’d be better to use different media tracks, so the picture is smoother.
If a track needs to be switched off during the transmission, we can use the enabled feature of a media track.
In the end, it’d be nice to think about stereo sound. Stereo is two different sounds, and they have to be transmitted separately. MediaChannel is used for that. Media track can use different channels (for instance, 6 if we need a 5+1 sound). The channels inside the media track are also synced. When a video is played, usually one channel is used, but it’s possible to use several of them, for example, to apply advertisement.
To summarize: we use a media stream to transmit video and audio data. The data is synced inside each media stream. We could use different media channels if we don’t aim for synchronization. There are two media tracks inside each stream, for video and audio. There can be more tracks if we need to transmit different videos (interlocutor and their table). Every track can consist of different channels but usually is used for stereo sound only.
In the simplest situation, we won’t have a video chat, and there’ll only be one local media stream of two tracks, audio and video. Each track will consist of one primary channel. The video track is responsible for the camera, while the audio track – for the microphone. The media stream is a container for both of them.
Session descriptor (SDP)
Different computers have different cameras, mics, graphics cards, etc. There is a multitude of parameters to them. It all needs to be coordinated for the media data transmission between two network nodes. WebRTC does it automatically and creates a special object – SDP. Transmit SDP to another node, and you can transmit the video data. There is no connection with another node, though.
Any signaling mechanism can help here. SDP can be sent via sockets, humans (tell the SDP to another node via the phone), or.. well, post office. You get a ready SDP, and it needs to be sent out – as simple as that. When the other guy receives SDP, they need to send it to WebRTC. It is stored as a text and can be changed from the applications, but it’s rarely needed. As an example, with a desktop <-> phone connection, sometimes it’s obligatory to forcefully choose the right audio codec.
Usually, when the connection is established, it’s obligatory to mention an address, such as a URL. There is no necessity to do it here, as you yourself will send the data via the signaling mechanism. To tell WebRTC that we want to establish a p2p connection, function createOffer has to be invoked. After that’s been done, and the special callback created, a new SDP object will be created and sent to the same callback. All you need to do is transmit this object to another node (interlocutor) via the network.
The signaling mechanism will help data, this SDP object, to arrive. This session descriptor is alien for this node, therefore it bears useful information.
Receiving this object is a signal to start the connection. So, you have to agree with it and call the createAnswer function. It is an absolute analog to createOffer. Your callback will receive a local session descriptor and then will need to be transmitted via the signaling mechanism back again.
It’s worth mentioning that calling a createAnswer function is only possible after receiving an alien SDP object. That’s because the local SDP object that will generate upon calling createAnswer has to rely on a remote SDP object. Only then will it be possible to coordinate your video settings with those of your interlocutor. Also, don’t call createAnswer and createOffer before receiving a local media stream, as they will have nothing to write to the SDP object.
Since WebRTC allows you to edit an SDP object, you will need to install the local descriptor upon receiving it. Sending the things WebRTC gave us back to it might seem strange, but that’s the protocol. A remote descriptor also needs to be installed upon receiving.
After this handshaking of some sort, the nodes will learn about each other’s wishes. For example, if node 1 supports codecs A and B, and node 2 supports codecs B and C, they both will choose codec B. That’s because these nodes know local and alien descriptors. The connection logic has been established and it’s possible to send media streams now. There is another problem, though: the nodes are still connected with just a signaling mechanism.


Ice candidates
Upon establishing a connection, the address of the node that you need to connect with isn’t mentioned. First, logical connection establishes, then physical, although it used to be the other way around. It won’t be so strange, however, if we keep in mind that we use an external signaling mechanism.
So, the logical connection has been established but there’s no path that the nodes can use to transmit data yet. Not everything is simple here, but we can still start with the simple things. Imagine that the nodes are within the same private network. As we know, they can easily connect with each other via their internal IPs (or other addresses if TCP/IP is not in use).
WebRTC tells us the Ice candidate objects through some callbacks. They too arrive in the form of text, and they too need to be sent through a signaling mechanism, just like the session descriptors. If the session descriptor contained information about our settings on the camera and phone level, candidates do that with our placement inside a network. Send them to another node, and it will be able to logically connect with us. As it already has a session descriptor, the data will flow in. If it doesn’t forget to send us its candidate object (information on where it’s placed inside the network), we’ll be able to connect with it.
There is another difference from a classical client-server interaction. Communication with an HTTP server goes as request-answer. The client sends data to the server, the server processes it and sends it to the address mentioned in the request packet. It’s obligatory to know two addresses in WebRTC and connect them from both sides.
The difference from session descriptors is that only remote candidates have to be installed. Editing is prohibited here and won’t be of use. In different WebRTC realizations, candidates must be installed only after the installation of session descriptors.
So, why can there be one session descriptor but lots of candidates? Because placement within a network can be determined not only by an own internal IP address but also by an external router address (one or more) and by TURN server addresses.
So, we have two candidates within one network (picture below). How to identify them? With the help of IP addresses only. Of course, different transport can be used (TCP and UDP), as well as different ports. This is the information that’s contained inside the candidate object – IP, TRANSPORT, PORT, etc. For instance, let’s take port 531 and UDP transport.

So, when we’re inside the p1 node, WebRTC will send us this as a candidate object: [10.50.200.5, 531, udp]. It’s not an exact thing, just a scheme. If we’re inside the p2 node, the candidate will change to [10.50.150.3, 531, udp]. P1 will receive p2’s IP and PORT through a signaling mechanism and will be able to connect to p2 directly. In fact, p1 will send data to 10.50.150.3:531, hoping that it will reach p2. Whether that address is owned by p2 or an intermediary, not important. What is important is that the data will be sent to this address and will be able to reach p2.
While the nodes are inside the same network, everything is a piece of cake, as every node only has one candidate object (their own, which is their placement in the network). But the number of candidates will grow by a lot if the nodes are in different networks.
Let’s take a look at a more complicated case. One node is behind a router (NAT), and the 2nd node is in the same network as that router (for example, on the internet).
This case has its own solution. A home router usually has a NAT table. This mechanism is created for the nodes inside a private router network to communicate with, for example, websites.
Let’s assume that a web-server is connected to the internet directly, meaning it has a public IP. Let it be the p2 node. Then, the p1 node (web client) sends a request to the 10.50.200.10 address. First, the data arrives at the r1 router or, to be precise, to its internal interface 192.168.0.1. After that, the router memorizes the source address (p1) and puts it in the NAT table. Then, the router changes the source address to its own (p1 -> r1). Then, using its external interface, the router sends the data to the p2 web server. The web server processes the data generates an answer which it sends back to the router. When the router receives the data, it checks the NAT table and sends the data over to the p1 node. The router here is an intermediary.
Well, what if several nodes from the internal network send a request to the external network? How does a router realize where to send the answer? This problem is solved with the help of ports. When the router substitutes the node address with its’ own, it also substitutes the port. If two nodes request the internet, then the router substitutes their source ports to different ones. Then, when the packet from the web server returns to the router, the router will understand the recipient of the packet by the port. The example is down below.
Going back to the WebRTC and the part where it uses an ICE protocol (hence Ice candidates). The p2 node has one candidate (its placement inside the network, 10.50.200.10), and the p1 node that is with the router with NAT, has 2 candidates: local (192.168.0.200) and a router candidate (10.50.200.5). The first one isn’t of much use here, however, it is being generated as WebRTC knows nothing about a remote node – it can be within the same network or not. The second candidate is useful and as we know, the port will have an important role to get through NAT.
The entry in the NAT table is generated only when the data leaves the internal network. That’s why the p1 node has to send its data first, and only then can the data from p2 reach p1.
Actually, both nodes will be behind NAT. To create an entry in every router’s NAT table, nodes have to send something to a remote node, but this time none will be able to reach the other. That’s because nodes don’t know their external IP addresses, and sending data to the internal addresses is pointless.
However, if external addresses are known, the connection will be easily established. If the first node sends the data to the second node router, the router will ignore the data as its NAT table is empty at that moment. However, the first node router has got an entry in the NAT table. Now, as soon as the 2nd node sends the data to the first node router, the router will successfully send to the 1st node. Now, the NAT table of the 2nd router has the needed data.
The problem is, to find out an external IP, we need a node that is inside a public network. In order to deal with this problem, additional servers are used, that are connected to the internet directly. They also help create those entries in the NAT table.
STUN and TURN servers
Available STUN and TURN servers must be mentioned upon a WebRTC initialization, and we’ll be calling them ICE servers from now on. If the servers aren’t mentioned, only nodes from the same network will be able to connect (those that are connected to the network without NAT). It’s important to mention that 3g networks require you to use TURN servers to be operational.
The STUN server is a server on the internet that sends a return address (source address of the node) back. The node behind the router communicates with a STUN server to bypass NAT. A packet that arrived at the STUN server contains a source address. It is a router address, in other words, an external address of our node. This is the address that a STUN server returns. Therefore, a node receives its external IP and port that makes him available in the network. Then, WebRTC creates an additional candidate with this address (external router address and port). Now the NAT table has an entry that allows the packets that are sent to the router via a correct port, to our node.
A STUN server example: how it works
The STUN server will be s1. Router and node stand as r1 and p1 respectively. We will also need to look after a NAT table, let’s make it r1_nat. In that table there is usually a lot of entries from different subnetwork nodes – we won’t mention them.
Let’s start with an empty r1-nat:
| Internal IP | Internal PORT | External IP | External PORT |
|---|---|---|---|
There are 4 columns in the table. It gives each column from the first two (IP, PORT), their couple from the last two (IP, PORT).
P1 sends a packet to s1. We see four interesting fields in the table down below, they’re in the title of a transport packet (TCP or UDP) – IP and PORT of the source and receiver. Let us imagine that these are the addresses.
| Src IP | Src PORT | Dest IP | Dest PORT |
|---|---|---|---|
| 192.168.0.200 | 35777 | 12.62.100.200 | 6000 |
P1 sends this packet to r1. The router will need to substitute the address of a source Src IP, as the address that’s mentioned in the packet won’t work for an external network. Furthermore, addresses from that range are reserved, and there is no address on the internet that has that address. The router substitutes the packet and creates a new entry in r1_nat. That’s why it needs to come up with a port number. Since different nodes within a subnetwork can call out to an external network, the NAT table has to contain additional information, so that the router can determine, what node is the recipient for the return packet from the server. Let’s imagine that the router created a port 888.
The changed packet heading:
| Src IP | Src PORT | Dest IP | Dest PORT |
|---|---|---|---|
| 10.50.200.5 | 888 | 12.62.100.200 | 6000 |
10.50.200.5 – router’s external address.
r1_nat:
| Internal IP | Internal PORT | External IP | External PORT |
|---|---|---|---|
| 192.168.0.200 | 35777 | 10.50.200.5 | 888 |
IP address and a subnetwork port are the same as in the initial packet. Actually, sending it back, we need to have a way to completely restore them. IP for the external network is a router address, and the port will change to one created by the router.
An actual port, to which node p1 accepts connection is, indeed, 35777, but the server sends data to a dummy port 888. It will be later changed to the real one, 35777.
So, the router has substituted an address and a port of the source in the packet heading and added an entry to the NAT Now the packet is sent via the network to the server – to the s1 node. S1 has a packet like this upon entrance:
| Src IP | Src PORT | Dest IP | Dest PORT |
|---|---|---|---|
| 10.50.200.5 | 888 | 12.62.100.200 | 6000 |
So, a STUN server knows that it received a packet from 10.50.200.5:888. The server sends this address back now. It’s worth stopping here for a bit and look once again at this.
The tables above are a piece from a packet heading, not from its content. We haven’t discussed the content since it’s not so important – it’s described in the STUN protocol. Now, however, we also will be looking at the content. It will be simple and will contain the router address – 10.50.200.5:888, despite us taking it from the packet heading. It’s not done often as protocols don’t usually care about node addresses. The only important thing is that the packets are delivered as intended. But here we are looking at a protocol that establishes a path between the two nodes.
Now we got the 2nd packet which goes backward:
| Src IP | Src PORT | Dest IP | Dest PORT |
|---|---|---|---|
| 12.62.100.200 | 6000 | 10.50.200.5 | 888 |
The heading has changed because the source and the receiver swapped places which is logical as the packet’s destination is different now.
Content
10.50.200.5:888
This is the content of the packet. Actually, it could contain a lot of information. But only what’s important for understanding how the STUN server works is mentioned here.
Then the packet travels throughout the network unless it ends up on the external interface of r1. The router understands that the packet isn’t meant for him. How? It can be determined by the port. Port 888 isn’t used by the router for its own purpose but for the NAT mechanism. That’s why the router is looking at that table. It also looks at the External PORT column and searches for a row that matches with the Dest PORT from the arriving packet, which is 888.
| Internal IP | Internal PORT | External IP | External PORT |
|---|---|---|---|
| 192.168.0.200 | 35777 | 10.50.200.5 | 888 |
We’re lucky that this row exists. If we weren’t so lucky, the packet would be dropped away. Now we need to understand, to what subnetwork node to send the packet. Don’t hurry, let’s remember how important ports are in this mechanism. Two nodes in the subnetwork could be sending requests to an external network. Then, if the router created port 888 for the first node, it created port 889 for the 2nd one. Let’s assume that that’s the case, and r1_nat looks like this:
| Internal IP | Internal PORT | External IP | External PORT |
|---|---|---|---|
| 192.168.0.200 | 35777 | 10.50.200.5 | 888 |
| 192.168.0.173 | 35777 | 10.50.200.5 | 889 |
We can understand by port 888 that the needed internal address is 192.168.0.200:35777. The router changes that receiver’s address from
| Src IP | Src PORT | Dest IP | Dest PORT |
|---|---|---|---|
| 12.62.100.200 | 6000 | 10.50.200.5 | 888 |
to
| Src IP | Src PORT | Dest IP | Dest PORT |
|---|---|---|---|
| 12.62.100.200 | 6000 | 192.168.0.200 | 35777 |
The packet successfully reaches node r1 and, upon looking at the packet content, the node finds out its external IP address – its address in the external network. It also knows the port that it makes way for through NAT.
What’s next? How is it useful? The usefulness lies within the entry to table r1_nat. If anyone sends a packet with port 888 to r1, the packet will be redirected to p1. Thus, a narrow way to a hidden node p1 is created.
From the example above you can imagine how NAT and STUN server work. Actually, ICE and STUN/TURN servers are there to bypass NAT restrictions.
Between node and a server, there can be several routers. In case the node receives the address of the router that is the first in the same network as the server. In other words, we’ll receive an address for the router that’s connected to the STUN server. It is exactly what we need for the p2p communication if we keep in mind the fact that each router will be updated with an important row in the NAT table. That’s why the way back will be as smooth as silk.
TURN server is an upgraded STUN server, therefore each TURN server can work as a STUN server. However, there are advantages to the TURN server. If a p2p communication is impossible (in 3g networks), the server becomes a relay and starts working as an intermediary. Of course, p2p is out of the question then, but outside of the ICE mechanism, nodes think that they have direct interaction.
When is the TURN server a must? Why is the STUN server not enough? Because there are different kinds of NAT. They substitute IP address and a port in the same manner, but some of them have embedded falsification protection. For example, in the symmetrical NAT table, two more parameters are stored, IP, and a remote node port. A packet from an external network goes through NAT to the internal network only when the address and port of the source match those mentioned in the table. That’s why the trick with the STUN server doesn’t work out NAT table stores the address and port of the STUN server. When the router receives a packet from a WebRTC interlocutor, it drops it off as it deems the packet falsified. The packet has arrived not from the STUN server.
Therefore, the TURN server is needed when the two interlocutors are behind a symmetric NAT (everyone’s behind their own)
TL;DR
Media stream
- Video and audio data are packed into media streams
- Media streams synchronize media tracks that they consist of
- Different media streams aren’t synced between themselves
- Media streams can be either local or remote. Local ones are in charge for camera and microphone, whereas remote ones receive data from the network as a code
- There are two types of media tracks: for video and for audio
- Media tracks can be turned on or off
- Media tracks consist of media channels
- Media tracks synchronize the media channels they consist of
- Media streams and media tracks have marks that help to distinguish them from one another
Session descriptor
- Session descriptor is used for a logical connection of two nodes within a network
- Session descriptor stores information about available ways to code audio and video data
- WebRTC uses an external signaling mechanism. Transferring session descriptors (SDP) becomes an application’s task
- Mechanism of logical connection consists of two steps: offer and answer
- Session descriptor generation is impossible without using a local media stream with an offer. It’s also impossible without using a remote session descriptor with an answer
- A received descriptor must be given to WebRTC realization, regardless of whether this descriptor was received remotely or locally from the same WebRTC realization
- There is also an opportunity to slightly change session descriptor
Candidates
- Ice candidate is a node’s address within a network
- The address can be own, router’s or the TURN server’s
- There are many candidates
- A candidate consists of an IP address, port and a transport type (TCP or UDP)
- Candidates are used to establish a physical connection between two nodes within a network
- Candidates need to be sent via a signaling mechanism
- Only remote candidates should be transferred to a WebRTC realization
- In some WebRTC realizations, candidates can be sent only after a session descriptor is installed
STUN/TURN/ICE/NAT
- NAT is a mechanism that allows access to an external network
- Home routers support a special NAT table
- Routers substitute addresses in packets. The source address becomes their own if the packet goes to an external network, and the source address becomes a node address within the internal network if the packet arrived from an external network.
- NAT uses ports to allow multi-channel access to an external network
- ICE is a mechanism to bypass NAT
- STUN and TURN servers help to bypass NAT
- STUN server allows the creation of obligatory entries in a NAT table and returns an external node address
- TURN server generalizes STUN mechanism and makes it always working
- In the worst-case scenarios, a TURN server is used as a relay, so a p2p turns into a client-server-client connection
Posted on September 28, 2021
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related