JavaScript Event Loop And Call Stack Explained

Felix Gerschau
Posted on October 5, 2020

Originally published on my blog: JavaScript Event Loop And Call Stack Explained
My goal with this article is to teach you how JavaScript works in the browser. Even though I've been working with JavaScript my whole career, I didn't get how these things work until recently.
I still forget how this works from time to time. That's why I wrote this article. I hope it will make you understand these concepts as well.
I want to make this article as easy to understand as possible. If you have any open questions, please send me an email or leave a comment. I will try to help you and improve the article with your feedback.
How JavaScript works in the browser
Before I dive into the explanation of each topic, I want you to have a look at this high-level overview that I created, which is an abstraction of how JavaScript interacts with the browser.
Don't worry if you don't know what all of the terms mean. I will cover each of them in this section.
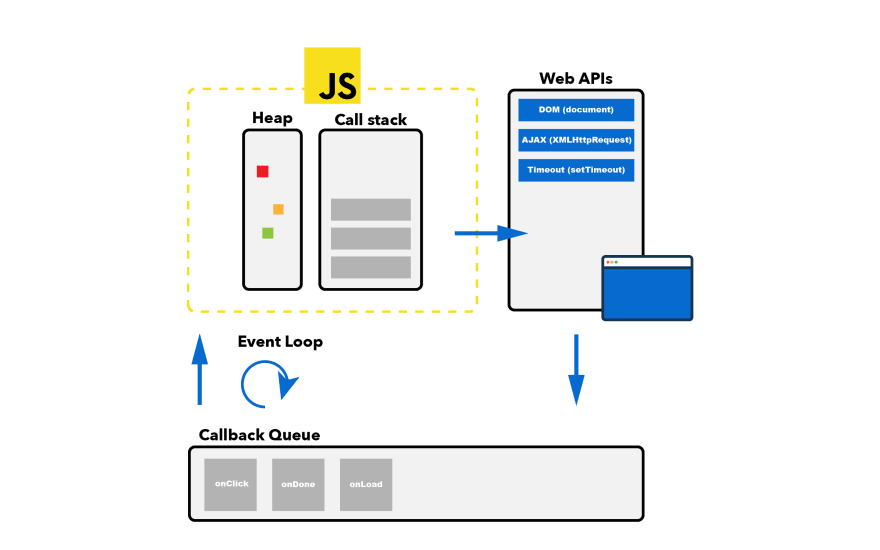
Note how most of the things in the graphic aren't part of the JavaScript language itself. Web APIs, the callback queue, and the event loop are all features that the browser provides.
A representation of NodeJS would look similar, but in this article, I'll focus on how JavaScript works in the browser.
Call stack
You've probably already heard that JavaScript is single-threaded. But what does this mean?
JavaScript can do one single thing at a time because it has only one call stack.
The call stack is a mechanism that helps the JavaScript interpreter to keep track of the functions that a script calls.
Every time a script or function calls a function, it's added to the top of the call stack.
Every time the function exits, the interpreter removes it from the call stack.
A function either exits through a return statement or by reaching the end of the scope.
Every time a function calls another function, it's added to the top of the stack, on top of the calling function.
The order in which the stack processes each function call is following the LIFO principle (Last In, First Out).
The steps of the previous example are the following:
- The file loads and the
mainfunction is being called, which stands for the execution of the entire file. This function is added to the call stack. -
maincallscalculation(), which is why it is added to the top of the call stack. -
calculation()callsaddThree(), which again is added to the call stack. -
addThreecallsaddTwo, which is added to the call stack.
...
-
addOnedoesn't call any other functions. When it exits, it is removed from the call stack. - With the result of
addOne,addTwoexits as well and is being removed from the call stack. -
addThreeis being removed as well. -
calculationcallsaddTwo, which adds it to the call stack. -
addTwocallsaddOneand adds it to the call stack. -
addOneexits and is being removed from the call stack. -
addTwoexits and is being removed from the call stack. -
calculationcan exit now with the result ofaddThreeandaddTwoand is being removed from the call stack. - There are no further statements or function calls in the file, so
mainexits as well and is being removed from the call stack.
I called the context that executes our code
main, but this is not how the official name of the function. In the error messages that you can find in the browser's console, the name of this function isanonymous.
Uncaught RangeError: Maximum call stack size exceeded

You probably know the call stack from debugging your code. Uncaught RangeError: Maximum call stack size exceeded is one of the errors you might encounter. Below we can see a snapshot of the callstack when the error occured.
Follow the stack trace of this error message. It represents the functions calls that led to this error. In this case, the error was in the function b, which has been called by a (which has been called by b and so on).
If you see this specific error message on your screen, one of your function has called too many functions. The maximum call stack size ranges from 10 to 50 thousand calls, so if you exceed that, it's most likely that you have an infinite loop in your code.
The browser prevents your code from freezing the whole page by limiting the call stack.
I re-created the error with the following code. A way to prevent this is by either not using recursive functions in the first place, or by providing a base case, which makes your function exit at some point.
function a() {
b();
}
function b() {
a();
}
a();
In summary, the call stack keeps track of the function calls in your code. It follows the LIFO principle (Last In, First Out), which means it always processes the call that is on top of the stack first.
JavaScript only has one call stack, which is why it can only do one thing at a time.
Heap
The JavaScript heap is where objects are stored when we define functions or variables.
Since it doesn't affect the call stack and the event loop, it would be out of the scope of this article to explain how JavaScript's memory allocation works.
I plan to write a blog post on this topic. If you haven't already, make sure to subscribe to my newsletter to get notified when it's out.
Web APIs
Above, I said that JavaScript can only do one thing at a time.
While this is true for the JavaScript language itself, you can still do things concurrently in the browser. As the title already suggests, this is possible through the APIs that browsers provide.
Let's take a look at how we make an API request, for instance. If we executed the code within the JavaScript interpreter, we wouldn't be able to do anything else until we get a response from the server.
It would pretty much make web applications unusable.
As a solution to this, web browsers give us APIs that we can call in our JavaScript code. The execution, however, is handled by the platform itself, which is why it won't block the call stack.
Another advantage of web APIs is that they are written in lower-level code (like C), which allows them to do things that simply aren't possible in plain JavaScript.
They enable you to make AJAX requests or manipulate the DOM, but also a range of other things, like geo-tracking, accessing local storage, service workers, and more.
If you're interested in what new APIs we can expect to surface in the future, check out my article on project Fugu, a cross-company effort, brought to life by Google, that intents to bring more native features to the web platform.
Callback queue
With the features of web APIs, we're now able to do things concurrently outside of the JavaScript interpreter. But what happens if we want our JavaScript code to react to the result of a Web API, like an AJAX request for instance?
That's where callbacks come into play. Through them, web APIs allow us to run code after the execution of the API call has finished.
What is a callback?
A callback is a function that's passed as an argument to another function. The callback will usually be executed after the code has finished.
You can create callback functions yourself by writing functions that accept a function as an argument. Functions like that are also known as higher-order functions. Note that callbacks aren't by default asynchronous.
Let's have a look at an example:
const a = () => console.log('a');
const b = () => setTimeout(() => console.log('b'), 100);
const c = () => console.log('c');
a();
b();
c();
setTimeout adds a timeout of x ms before the callback will be executed.
You can probably already think of what the output will look like.
setTimeout is being executed concurrently while the JS interpreter continues to execute the next statements.
When the timeout has passed and the call stack is empty again, the callback function that has been passed to setTimeout will be executed.
The final output will look like this:
a
c
b
But what about the callback queue?
Now, after setTimeout finishes its execution, it doesn't immediately call the callback function. But why's that?
Remember that JavaScript can only do one thing at a time?
The callback we passed as an argument to setTimeout is written in JavaScript. Thus, the JavaScript interpreter needs to run the code, which means that it needs to use the call stack, which again means that we have to wait until the call stack is empty in order to execute the callback.
You can observe this behavior in the following animation, which is visualizing the execution of the code we saw above.
Calling setTimeout triggers the execution of the web API, which adds the callback to the callback queue.
The event loop then takes the callback from the queue and adds it to the stack as soon as it's empty.
Multiple things are going on here at the same time. Follow the path that the execution of setTimeout takes, and in another run, focus on what the call stack does.
Unlike the call stack, the callback queue follows the FIFO order (First In, First Out), meaning that the calls are processed in the same order they've been added to the queue.
Event loop
The JavaScript event loop takes the first call in the callback queue and adds it to the call stack as soon as it's empty.
JavaScript code is being run in a run-to-completion manner, meaning that if the call stack is currently executing some code, the event loop is blocked and won't add any calls from the queue until the stack is empty again.
That's why it's important not to block the call stack by running computation-intensive tasks.
If you execute too much code or clog up your callback queue, your website will become unresponsive, because it's not able to execute any new JavaScript code.
Event handlers, like onscroll, add more tasks to the callback queue when triggered. That's why you should debounce these callbacks, meaning they will only be executed every x ms.
See it for yourself
Add the following code to your browser console. As you scroll, you can observe how often the callback prints
scroll.window.onscroll = () => console.log('scroll');
setTimeout(fn, 0) or setImmediate()
We can take the above-described behavior to our advantage if we want to execute some tasks without blocking the main thread for too long.
Putting your asynchronous code in a callback and setting setTimeout to 0ms will allow the browser to do things like updating the DOM before continuing with the execution of the callback.
Job queue and asynchronous code
In the overview that I showed in the beginning, I was leaving out one additional feature that's important to know.
In addition to the callback queue, there's another queue that exclusively accepts promises—the job queue.
Promises: A quick recap
EcmaScript 2015 (or ES6) first introduced promises, even though it has been available before in Babel.
Promises are another way of handling asynchronous code, other than using callbacks. They allow you to easily chain asynchronous functions without ending up in what's called callback hell or pyramid of doom.
setTimeout(() => {
console.log('Print this and wait');
setTimeout(() => {
console.log('Do something else and wait');
setTimeout(() => {
// ...
}, 100);
}, 100);
}, 100)
With a but of imagination, you can see how chaining callbacks can end up in a pyramid of doom—or straight ugly code.
With promises, this code can become much more readable:
// A promise wrapper for setTimeout
const timeout = (time) => new Promise(resolve => setTimeout(resolve, time));
timeout(1000)
.then(() => {
console.log('Hi after 1 second');
return timeout(1000);
})
.then(() => {
console.log('Hi after 2 seconds');
});
This code looks even more readable with the async/await syntax:
const logDelayedMessages = async () => {
await timeout(1000);
console.log('Hi after 1 second');
await timeout(1000);
console.log('Hi after 2 seconds');
};
logDelayedMessages();
That was a quick recap on how promises work, but in this article, I won't dive deeper into this topic.
Check out the MDN web docs in case you want to learn more about them.
Where do promises fit in?
Why am I talking about promises here?
Having the bigger picture in mind, promises behave a little differently than callbacks because they have their own queue.
The job queue, also known as the promise queue, has priority over the callback queue, just like a fast-track queue at an amusement park.
The event loop will take calls from the promise queue first, before processing the callback queue.
Let's have a look at an example:
console.log('a');
setTimeout(() => console.log('b'), 0);
new Promise((resolve, reject) => {
resolve();
})
.then(() => {
console.log('c');
});
console.log('d');
Taking into consideration your knowledge about how callback queues are working, you might think that the output will be a d b c.
But because the promise queue has priority over the callback queue, c will be printed before b, even though both are asynchronous:
a
d
c
b
Conclusion
I hope you now have a better understanding of what is happening behind the scenes of your JavaScript code. As I already mentioned in the beginning, if you have any questions or feedback please leave a comment.
I've learned this stuff on the internet as well, here are the resources that have helped me grasp this topic:
The best talk/video out there on this topic. I highly recommend you check it out.
A tools that lets you visualize how your code is being executed.
More artiles you might be interested in:
Reading is a great way of improving your programming skills. In this article, I share my key-takeaways of my favorite programming book.
A full walk-through of how you can make your React app a Progressive Web App (it's easier than it sounds).
Posted on October 5, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related




November 28, 2024