The sword refers to immer, the faster and stronger immutable data js tool limu stable version released!

幻魂
Posted on August 18, 2023

Preface
Welcome to understand and pay attention to limu, visit documentation and right-click to bring up the console, you can ** Real-time experience **limu api and immer api for comparison (limu and immer objects are bound globally).
Next, let us learn more about the birth process of limu ^_^
The state of immutable data
Immutable data has the characteristics of structure sharing, which allows some frameworks that rely heavily on shallow comparisons to quickly gain performance benefits (such as react), and also allows some scenarios that require strict immutable data to avoid deep cloning. Redundant performance overhead, and apart from the two very popular tool libraries immutablejs and immer, is there an immutable data tool library with better performance and ease of use than them? Before answering this question, let's look at the dilemma that immutablejs and immer got into.
As a pioneer, immutablejs, the earliest git submission record can be traced back to April 2014. With the immutable state programming concept of react, it became more and more popular after 2015, and has now reached 30K+ stars. In the js language world, it has an important position as a guide for immutable data, leading everyone to realize the importance of immutable data in certain specific programming fields.
However, its problems are also more prominent, mainly attributed to 2 points
- 1 The api is complex and isolated from the original js operation processing, which has a heavy learning cost and memory burden
- 2 A set of its own data structure is built in, and it is necessary to directly convert between ordinary json and immutable data through
fromJsandtoJs, which brings additional overhead.
// additional learning cost and memory burden
immutableA = Immutable. fromJS([0, 0, [1, 2]]);
immutableB = immutableA.set 1, 1;
immutableC = immutableB. update 1, (x) -> x + 1;
immutableC = immutableB. updateIn [2, 1], (x) -> x + 1;
However, immer, which was born in 2018, perfectly solved the above two problems. It cleverly uses Proxy to proxy the original data, allowing users to complete all immutable data operations like the original js (unsupported environments are automatically downgraded defineProperty), so that users do not have any learning cost and memory burden.
const { produce } = limu;
const baseState = {
a: 1,
b: [ 1, 2, 3 ],
c: {
c1: { n: 1 },
c2: { m: 2 },
}
};
// Operate immutable data as smoothly as original js
const nextState = produce(baseState, (draft)=>{
draft.a = 2;
draft.b['2'] = 100;
});
console.log(nextState === baseState); // false
console.log(nextState.a === baseState.a); // false
console.log(nextState.b === baseState.b); // false
console.log(nextState.c === baseState.c); // true
But is immer really the ultimate answer? The performance problem of immer is more prominent in large arrays and deep-level object scenarios. See this issue description, many authors in the community began to try to make breakthroughs, and noticed that structura and mutative, I found that it is indeed many times faster than immer as they said, but it still fails to solve the problem of both fast speed and good development experience. I will analyze the two issues in detail below.
limu is born
At the end of 2021, I started to conceive the v3 version of the state library concent, one of the key points is to support deep dependency collection (v2 only supports the first collection of state One-layer read dependency), then you need to use Proxy to complete this action in depth, and use immer in depth to find that viewing drafts in debug mode is very frustrating, and you need to use JSON.parse(JSON.stringify(draft)) to complete, although it was later discovered that the current interface can export a draft copy and view the data structure, but it really annoys me to insert extra current and then erase it at compile time, and current itself has a lot of problems Overhead, plus the following similar performance problems of immer found through issue
const demo = { info: Array.from(Array(10000).keys()) };
produce(demo, (draft) => {
draft.info[2000] = 0; // take long time
});
I began to try to design and implement limu, expecting to maintain the same API as immer, but faster and better to use, so after countless small iterations, I found some key speed-up techniques (will be introduced below to), solved the memory leak problem, and reached two key points to ensure quality:
- Run through 370+ test cases
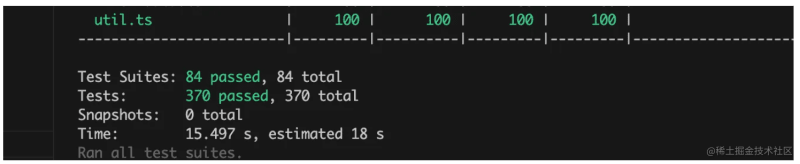
- Test coverage reached
97%
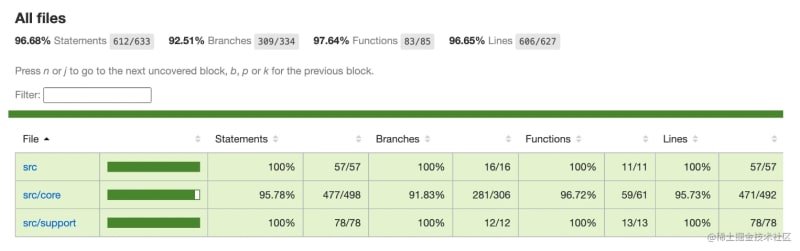
At the same time, after making the performance and ease of use meet my ideals, I can finally officially announce the release of the stable version, and it has begun to serve as a basic component in News Portal, and then we will focus on the three major advantages of limu.
faster

Different from the copy-on-write mechanism of immer, limu adopts shallow clone on read and mark-on-write mechanism. Let’s take the following figure as an example to explain the specific operation process. After using the produce interface to generate draft data , limu will only make a shallow clone of the relevant data nodes passing through the draft data reading path
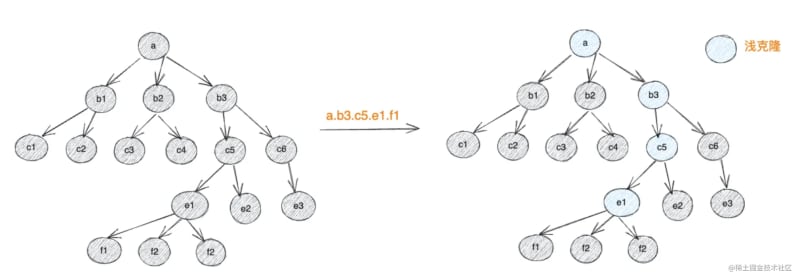
When the value under the target node is modified, all path nodes from the node to the root node will be traced back and marked as modified
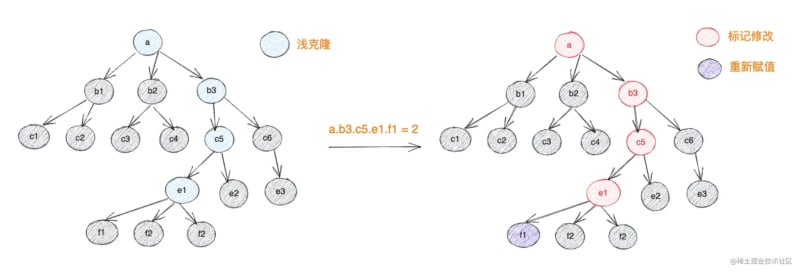
When finalizing the draft and generating the final object, limu only needs to replace the copies of all marked modified nodes from the root node to the corresponding positions, and no copies will be used for nodes without marked modified (note: generating a copy does not mean that it has been completed) modified)
Such a mechanism performs exceptionally well in scenarios where the original hierarchical relationship of the object is complex and the modification path is not wide, and there is no need to freeze the original object, which can reach 5 times or more faster than immer. Only when the modified data gradually spreads When the entire object has all nodes, the performance of limu will show a linear download trend, gradually approaching immer, but it is also much faster than immer.
Test Validation
In order to verify the above conclusions, users can follow the procedure below to obtain performance test comparison data for limu and immer
git clone https://github.com/tnfe/limu
cd limu
npm i
cd benchmark
npm i
node opBigData.js // Trigger the test execution, the console echoes the result
# or
node caseReadWrite.js
We prepare two use cases, one adapted from immer's official performance test case (Note: see the header after the jump the link to)
Execute node opBigData.js to get the following results (the shorter the bar, the faster)
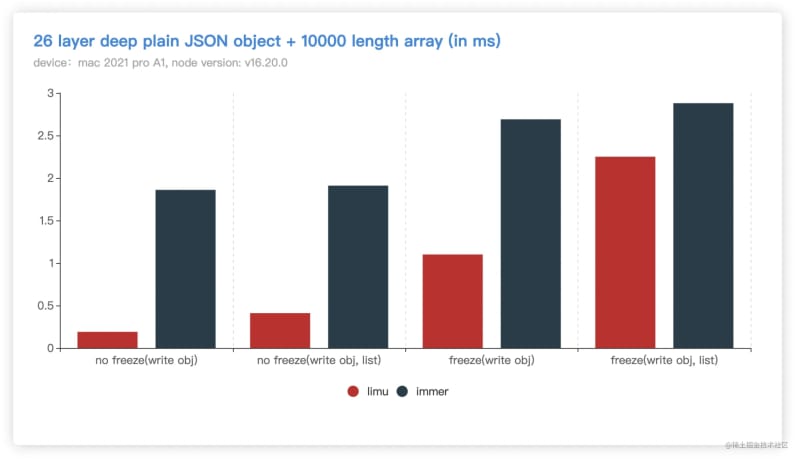
Note: The above is the v9 version. Immer released the v10 version in April 23. After testing, it was found that the results did not change much, and the performance improvement was not obvious
One is a deep-level json read and write case prepared by ourselves, and the results are as follows (the shorter the bar, the faster)
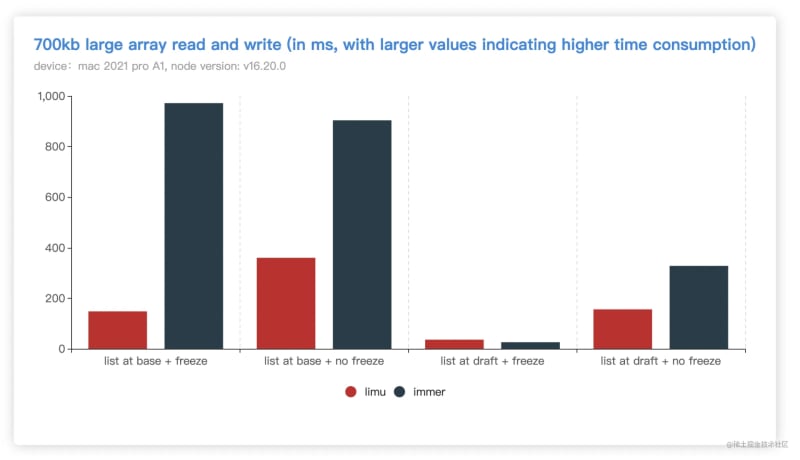
Different test strategies can be adjusted by injecting
STvalue, for exampleST=1 node caseReadWrite.js, the default is1when not injected
- ST=1, turn off freezing, do not operate arrays
- ST=2, turn off freeze, operate array
- ST=3, enable freezing, do not operate arrays
- ST=4, enable freezing, operate array
Stronger

limu uses Symbol and the prototype chain to hide the proxy metadata, so that the metadata always follows the draft node and is erased after the draft is over, so that users can not only operate immutable data like operating native js, but also view native json to view the draft data (only need to expand a layer of proxy), and always allow the user to synchronize the modified data of the draft to the viewable node in real time, which greatly improves the debugging experience.
Here we will respectively enumerate the diagrams of limu, immer, mutative, and structura to expand the draft in the debugging state:
-
limu can view all nodes of the draft arbitrarily, and the data is always synchronized to the modified data
-
structura can view the original structure of the draft, but the draft data is expired (note: but the log data is correct)
-
mutative maintains a structure similar to immer and cannot be viewed quickly
immer uses Proxy layer by layer proxy, unable to quickly view


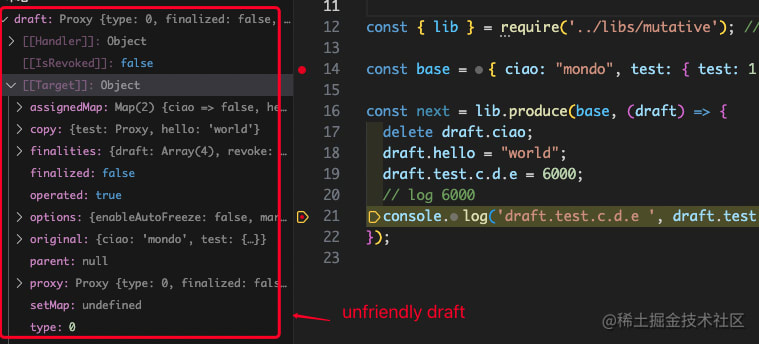

Lightweight

imu is designed as an immutable data js library for modern browsers. It only runs in js environments that support proxy features. The native support root objects are Map, Set, Array, Object, compared to immer 6.3kb The size capacity is nearly reduced by 1/3.
At the same time, more practical APIs are provided
immut
Generate an unmodifiable object im, but modifications to the original object will affect im synchronously
import { immut } from 'limu';
const base = { a: 1, b: 2, c: [1, 2, 3], d: { d1: 1, d2: 2 } };
const im = immut(base);
im.a = 100; // modification is invalid
base.a = 100; // modification will affect im
You can still read the latest value after merging
const base = { a: 1, b: 2, c: [1, 2, 3], d: { d1: 1, d2: 2 } };
const im = immut(base);
const draft = createDraft(base);
draft.d.d1 = 100;
console.log(im.d.d1); // 1, unchanged
const next = finishDraft(draft);
Object. assign(base, next);
console.log(im.d.d1); // 100, im and base always keep data in sync
immut adopts the shallow proxy mechanism when reading, which will have better performance than deepFreeze. It is suitable for scenarios where the original object is not exposed, but only the generated immutable object is exposed, and onOperate is used to collect read dependencies.
onOperate
Support for createDraft, produce, immt to configure onOperate callback to monitor all read and write changes (note: immut can only monitor read changes)
For example the following code:
const { createDraft, finishDraft } = limu;
const base = new Map([
['nick', { list: [1,2,3], info: { age: 1, grade: 4, money: 1000 } }],
['fancy', { list: [1,2,3,4,5], info: { age: 2, grade: 6, money: 100000000 } }],
['anonymous', { list: [1,2], info: { age: 0, grade: 0, money: 0 } }],
]);
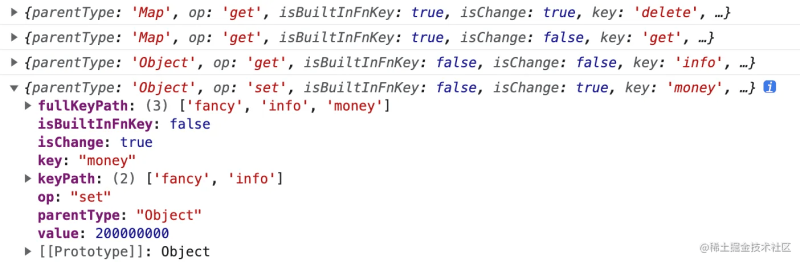
const draft = createDraft(base, { onOperate: console. log });
draft. delete('anonymous');
draft.get('fancy').info.money = 200000000;
const final = finishDraft(draft);
The following monitoring results will be generated, which is very beneficial for the upper framework to collect read and write dependencies
The upcoming helux v3 has completed a lot of interesting functions based on the
limudriver, please look forward to it.
Conclusion
After 2 years of hard work, it was an unexpected result for me to make a work that was initially a bit of a toy (incorporating concent and helux) into the ground. Combined with the recent Korean team of room temperature superconductors as an analogy, their LK-99 was burnt. For more than 20 years, no matter whether the result is satisfactory or not, at least one who loves science can persevere. Thinking of countless nights of npm run test and optimizing the code, why not indulge in it because of maintaining a true love heart What about refining code pills?
Regardless of whether limu will be submerged in the sea of stars in history, the release of the stable version is an explanation for myself. I hope that all coders will also maintain a steady stream of curiosity to refine the elixir in their hearts.
Friends Link
Welcome to follow my other projects 👇
Posted on August 18, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related



