Techniques for building predictable and reliable API

Aleksei Popov
Posted on March 26, 2024
Introduction
Application Programming Interfaces (APIs) facilitate communication and data sharing between various applications, empowering developers to construct integrated and sophisticated systems. Nonetheless, crafting APIs that are scalable, reliable and user-friendly presents significant challenges.
There are many useful design patterns that can guide you in building scalable APIs to serve the needs of your consumers, such as:
- Versioning
- Caching
- Pagination
- Rate liming
- Authentication and authorisation
- Circuit Breaker
However, in this article, I am going to focus on a less popular topic related to the predictability and reliability of APIs by providing examples of such challenges and techniques to tackle them. Most of these techniques are very basic and obvious, yet they are periodically missing in implementations. From time to time, I will provide examples using C# and .NET, but all of these are language agnostic.
Before jumping into the problems, let us talk a bit about networks and their reliability.
What is network?
A network, in the context of computing and telecommunications, is a collection of interconnected devices that can communicate and share data with each other. These devices can range from computers, mobile devices, and servers to IoT (Internet of Things) devices, routers, and switches. Networks can be small and localized, like a home Wi‑Fi network, or vast and global, like the internet.
As we can see from this definition, there are so many things that can go wrong. This leads us to the conclusion that networks are unreliable and failure is unavoidable
But why is this the case? Is it because of the well-known principle, Murphy's Law?
Murphy's Law states that:
Whatever can go wrong, will go wrong. So a solution is better the less possibilities there are for something to go wrong.
Partly, yes :) However, the reality is somewhat different. There are many obvious reasons why it might fail, such as:
- Physical Disruptions
- Interference and Capacity Issues
- Cyber Attacks
- Configuration and Human Errors
- Propagation Delays and Routing Issues
- Compatibility and Standardization Issues
- Maintenance and Upgrades
- Technical Limitation
And there are many other reasons that we, as a software engineers, are unlikely to be able to impact drastically.
Retry
Okay, if networks are so unreliable, what can we do about that?

The simplest solution is to retry. If it fails, it is very likely due to a temporary issue. For example, someone might have temporarily disconnected the cable from the server and then reconnected it.
So, we decided to add retry policies with expotential backoff to our HttpClient using Polly
using Microsoft.Extensions.DependencyInjection;
using Polly;
using Polly.Contrib.WaitAndRetry;
using Polly.Extensions.Http;
namespace MyService
{
public static class ServiceCollectionExtensions
{
public static IServiceCollection AddMyService(this IServiceCollection services)
{
services.AddHttpClient<IMyService, MyService>((sp, client) =>
{
// ... configure http client
})
.AddPolicyHandler(GetRetryPolicy());
return services;
}
private static IAsyncPolicy<HttpResponseMessage> GetRetryPolicy()
{
var delay = Backoff.DecorrelatedJitterBackoffV2(medianFirstRetryDelay: TimeSpan.FromSeconds(1), retryCount: 5);
return HttpPolicyExtensions
.HandleTransientHttpError()
.WaitAndRetryAsync(delay);
}
}
}
and are happy to be deploying this stuff to production. Now it works better because it helps to avoid temporary issues.

However, let us imagine that the situation is a bit more tricky because we didn't receive a response from the server. This could be due to a network issue, a timeout, a proxy or firewall issue, HTTP version incompatibilities, or just a client-side bug.

It it wasn't processed by server and we didn't get response from the server, in this case retry will work help us to avoid this issue.
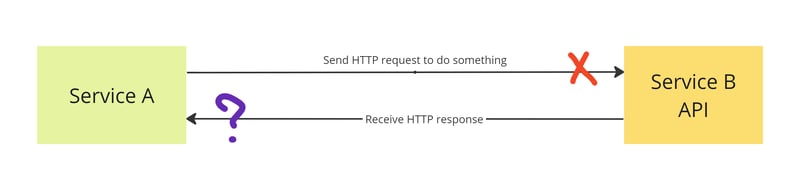
However, the situation becomes more interesting if it was processed successfully. So, the question is, what will a retry do in this case? Will it cause any harm?

The answer is simple: it depends on the implementation. In some cases, it will throw an error, in others, it can produce unexpected changes and side effects in the system.
Real world use cases
In theory, it looks dangerous, but do we exactly have systems that might be seriously affected by this?
First of all, based on statistic from different sources and just personal feelings, service oriented and microservices architectures are adopted by vast majority of companies which automatically puts them in situation of having distributed system.
Although microservices are gaining popularity due to their advantages, such as independent deployment, a heterogeneous development stack, simplified architecture control, and the ability to scale independently, they also bring a lot of challenges.
All of these companies are engaged in the development and maintenance of complex and highly available systems. These systems are designed to provide a wide array of services, including but not limited to payment processing, delivery logistics, file management, and the operation of online storefronts, among others. Their goal is to ensure uninterrupted service and optimal performance across a variety of sectors, catering to the diverse needs of their customer base while maintaining security, efficiency, and scalability
Who would be happy if they received two taxis, were charged twice, or purchased more than the desired amount of things?
No one, so, we must have solutions in place to avoid such situations.
Idempotency
Idempotency is a concept where doing the same thing multiple times has the same effect as doing it just once. In computing, an idempotent operation can be repeated many times without changing the result beyond the initial application.
It is believed that the HTTP methods GET, PUT, and DELETE are idempotent, whereas POST and PATCH are not. Formally, that's true, but what's to stop you from implementing DELETE in a non-idempotent way? It also depends on the approach used to define the API. If REST Level 0 is utilized, everything uses POST. Even an operation like RetrieveMyInvoices would be exposed as POST. In addition, if RetrieveMyInvoices returns a new set of invoices after a second call, does that mean it is not idempotent?
API and Exactly Once Semantics
It refers to the concept and implementation within APIs ensuring that an operation or a message is processed exactly once. For example, if an order is submitted to the delivery system, it will be delivered only once. The same principle applies to charges or transactions.
Idempotency key
To achieve exactly-once semantics, we can leverage a solution that attaches an idempotency key to the request, either in the headers or explicitly in the payload.
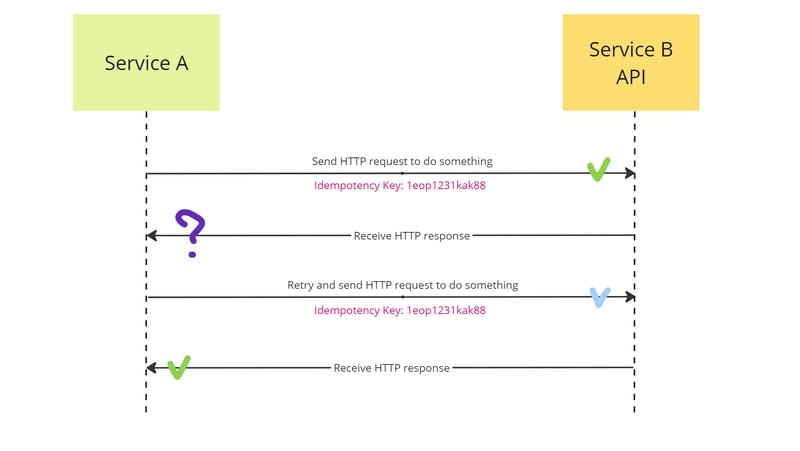
After retrying the same request with the identical idempotency key, Service B will verify that a request with such a key has already been processed and will simply return the previous response.
How to choose idempotency key?
Initially, we need to ensure the absence of duplicate idempotency keys to guarantee unique request identification. UUIDs or GUIDs can be employed for this purpose. Referring to the Wikipedia definition
While each generated GUID is not guaranteed to be unique, the total number of unique keys (2128 or 3.4×1038) is so large that the probability of the same number being generated twice is very small. For example, consider the observable universe, which contains about 5×1022 stars; every star could then have 6.8×1015 universally unique GUIDs.
Okay, now we need to set a reasonable expiration time for the idempotency key to clean up already processed requests. For instance, Stripe uses the following
You can remove keys from the system automatically after they’re at least 24 hours old. We generate a new request if a key is reused after the original is pruned. The idempotency layer compares incoming parameters to those of the original request and errors if they’re the same to prevent accidental misuse.
How to store idempotency keys?
The simplest solution would be to create a separate table for processed idempotency keys.
CREATE TABLE [dbo].[IdempotencyKey] (
[Key] VARCHAR(255) PRIMARY KEY,
[Namespace] VARCHAR(255) NOT NULL,
ExpiresAt DATETIME NOT NULL,
Payload NVARCHAR(MAX)
);
And during the processing of the message or request, insert the value in the same transaction.
INSERT INTO IdempotencyKey (Key, Namespace, ExpiresAt, Payload)
VALUES ('uniqueKey123', 'myservice', '2024-03-25 10:00:00', '{"status": "processed", "details": "Transaction completed successfully."}');
Let us look at what we need to configure on the application level.
By the way, the whole implementation can be found in the GitHub repository by this link
First of all, we need to create an entity and configure mapping with EF Core. There are many cases where frameworks with less overhead, for instance, Dapper, could be more efficient, but for simplicity and familiarity, let us stick with EF Core.
Let's create entity an first
public class IdempotencyKey
{
protected IdempotencyKey() { }
public static IdempotencyKey Create(string @namespace, string key, string? payload, TimeSpan expiration)
{
var expiresAt = DateTime.UtcNow.Add(expiration);
return Create(@namespace, key, payload, expiresAt);
}
public static IdempotencyKey Create(string @namespace, string key, string? payload, DateTime absoluteExpirationTime)
{
var idempotencyKey = new IdempotencyKey(@namespace, key, v, absoluteExpirationTime);
return idempotencyKey;
}
private IdempotencyKey(string @namespace, string key, string? payload, DateTime expiresAt)
{
Key = key ?? throw new ArgumentNullException(nameof(key));
Payload = payload;
Namespace = @namespace ?? throw new ArgumentNullException(nameof(@namespace));
ExpiresAt = expiresAt;
}
public string Namespace { get; protected set; } = null!;
public string Key { get; protected set; } = null!;
public string? Payload { get; protected set; }
public DateTime ExpiresAt { get; protected set; }
}
Then mapping
internal sealed class IdempotencyKeyEntityMap : IEntityTypeConfiguration<IdempotencyKey>
{
public void Configure(EntityTypeBuilder<IdempotencyKey> builder)
{
builder.HasKey(x => x.Key);
builder.Property(x => x.Key).HasMaxLength(128).IsRequired();
builder.HasIndex(o => new { o.Namespace, o.Key })
.HasDatabaseName("IX_IdempotencyKey_Uniqueness")
.IsUnique();
}
}
Ensure you register it with your DbContext
public class MyDbContext : DbContext
{
public MyDbContext(DbContextOptions options)
: base(options)
{
}
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
base.OnModelCreating(modelBuilder);
modelBuilder.ApplyConfigurationsFromAssembly(
typeof(SafeAssemblySearchAncestor).Assembly);
}
}
SafeAssemblySearchAncestor is simply an empty type located in the assembly where all IEntityTypeConfiguration implementations are found.
We also need a repository to store keys. I won't dive into the implementation of this one since it heavily depends on how you work with the DbContext.
public interface IIdempotencyKeyRepository
{
Task RemoveAsync(string @namespace, string key, CancellationToken token);
Task AddEntityAsync(IdempotencyKey idempotencyKey, CancellationToken token);
Task SaveChangesAsync(CancellationToken token);
Task<IdempotencyKey?> GetFirstOrDefaultAsync(string @namespace, string key, CancellationToken token);
Task<IdempotencyKey?> GetNotExpiredFirstOrDefaultAsync(string @namespace, string key, CancellationToken token);
Task<IdempotencyKey[]> GetExpiredAsync(int count, CancellationToken token);
Task RemoveRangeAsync(IdempotencyKey[] expired, CancellationToken token);
}
I prefer to separate business logic from persistence details to ensure it remains agnostic about storage methods, thereby enhancing maintainability. Therefore, let's define several behaviours that interact with keys.
public interface IIdempotencyCache
{
Task<CacheEntry?> GetAsync(string @namespace, string key, CancellationToken token);
Task SetAsync(string @namespace, string key, object? payload, TimeSpan expiration, CancellationToken token);
Task RemoveAsync(string @namespace, string key, CancellationToken token);
}
And for cleaning expired ones
public interface IIdempotencyCacheCleaner
{
Task CleanExpiredAsync(int maxSize, CancellationToken token);
}
The only step missing is attaching this logic to Web API.
To achieve this, we can utilise ASP.NET Core Filters.
I developed a very primitive IdempotentFilter to achieve the desired behaviour.
public sealed class IdempotentFilter : IAsyncActionFilter
{
private readonly IIdempotencyCache _idempotencyCache;
private readonly string _namespace;
private readonly TimeSpan _expiration;
public IdempotentFilter(IIdempotencyCache idempotencyCache, IConfiguration configuration)
{
_idempotencyCache = idempotencyCache;
_namespace = configuration["IdempotencyNamespace"] ?? throw new ArgumentException("There is no such key in the configuration");
_expiration = TimeSpan.FromSeconds(int.Parse(configuration["IdempotencyKeyExpirationInSeconds"] ?? throw new ArgumentException("There is no such key in the configuration")));
}
public async Task OnActionExecutionAsync(ActionExecutingContext context, ActionExecutionDelegate next)
{
var idempotencyKey = context.HttpContext.Request.Headers[IdempotencyHeaders.IdempotencyKey].SingleOrDefault();
var cancellationToken = context.HttpContext.RequestAborted;
if (idempotencyKey is null)
{
await next();
return;
}
var cacheEntry = await _idempotencyCache.GetAsync(_namespace, idempotencyKey, cancellationToken);
if (cacheEntry != null)
{
if (cacheEntry.Payload is not null)
{
//Requires more complicated logic to handle different types of MVC results
context.Result = new ObjectResult(cacheEntry.Payload) { StatusCode = 200 };
return;
}
else
{
context.Result = new OkResult();
return;
}
}
var executedContext = await next();
if (executedContext.Result is ObjectResult { Value: not null } result)
{
await _idempotencyCache.SetAsync(_namespace, idempotencyKey, result.Value, _expiration, cancellationToken);
}
else
{
await _idempotencyCache.SetAsync(_namespace, idempotencyKey, null, _expiration, cancellationToken);
}
}
}
And then used it for the controller's action.
[ApiController]
[Route("[controller]")]
public class InvoicesController : ControllerBase
{
private readonly IInvoiceService _invoiceService;
public InvoicesController(IInvoiceService invoiceService)
{
_invoiceService = invoiceService;
}
[HttpPost]
[Transactional]
[Idempotent]
public async Task<InvoicePayload> CreateInvoice([FromBody] InvoiceModel model, CancellationToken cancellationToken)
{
var invoiceId = await _invoiceService.CreateInvoice(model, cancellationToken);
return new InvoicePayload
{
Id = invoiceId
};
}
}
It is noteworthy to say that we need to apply both filters in specific order to achieve the desired behaviour: Transactional and Idempotent.
Why?
Because we need to have a global (shared) transaction for both operations to be atomic: creating an invoice and storing the idempotency key.
TransactionFilter is very simple, and it utilises a transaction with a snapshot isolation type (optimistic locking) to gain better performance.
This is the sequence diagram that explains how it works.
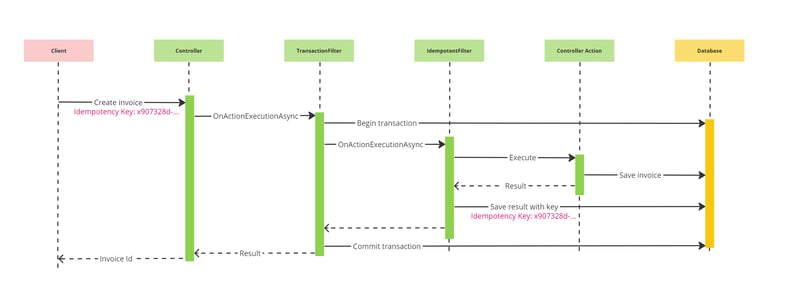
And very simple TransactionFilter
public class TransactionFilter : IAsyncActionFilter
{
private readonly IUnitOfWork _unitOfWork;
public TransactionFilter(IUnitOfWork unitOfWork)
{
_unitOfWork = unitOfWork;
}
public async Task OnActionExecutionAsync(ActionExecutingContext context, ActionExecutionDelegate next)
{
var cancellationToken = context.HttpContext.RequestAborted;
await using var transaction = await _unitOfWork.BeginSnapshotTransactionAsync(cancellationToken);
var executedContext = await next();
if (executedContext.Exception == null)
{
await transaction.CommitAsync(cancellationToken);
}
else
{
await transaction.RollbackAsync(cancellationToken);
}
}
}
Now, let us try to call it.
curl -X 'POST' \
'https://localhost:7174/Invoices' \
-H 'accept: text/plain' \
-H 'x-idempotency-key: test-key' \
-H 'Content-Type: application/json' \
-d '{
"amount": 150000,
"dueDate": "2024-03-28T15:48:43.991Z"
}'
{
"Id": "01381c12-c3de-4f45-9b47-be7908b6c528"
}
If the idempotency key already exists, we will immediately return the response for processing. Let's try to call it again with the same key.
{
"Id": "01381c12-c3de-4f45-9b47-be7908b6c528"
}
But if a duplicate request happens simultaneously, we will receive a 'duplicate key value violates unique constraint' error.
Microsoft.Data.SqlClient.SqlException (0x80131904): Violation of PRIMARY KEY constraint 'PK_IdempotencyKey'. Cannot insert duplicate key in object 'dbo.IdempotencyKey'. The duplicate key value is (id-2).
In such cases, it is better to have retries on the client side to smooth such situations.
Implementing this strategy significantly helps us in preventing race conditions. By ensuring that each message or request is processed in a synchronized manner within the same transaction, we effectively eliminate the possibility of concurrent processes interfering with each other.
Can Redis be utilised instead of SQL Database?
Some time ago, I was pretty sure that it could and could be used for all operations. However, this article from Martin Kleppmann made me doubt about it. The main danger is that to achieve exactly once execution, we need to acquire a lock using the idempotency key, execute the operation and then store the result. However, due to possible garbage collection (GC) pauses and clock desynchronization, we might find ourselves in a situation where two threads, operating under the same key, execute the same operation.
Although this problem is unlikely to occur often, we should avoid using it for critical operations.
What else can be chosen as the idempotency key?
Let us take a look on the situation with Order, Payment, and Delivery.
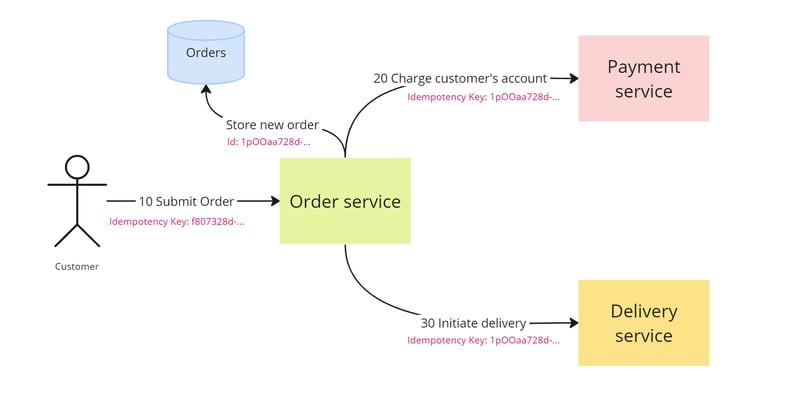
In this very simple use case, a customer submits an order, which automatically starts the order processing. It involves two simple steps: charging the customer's account and then initiating delivery. Of course, in real life, there are many more steps, with potential compensation in case of failure at some stage, but for simplicity, I will omit them.
So, to avoid submitting an order multiple times, an idempotency key is utilized. This key is generated on the client side and provided in the 'submit order' command.
It then creates a new order, stores it in the database, and initiates order processing. Now, we need to charge the customer for this order idempotently.
What should be used in this situation for idempotency? Surely, the same offer ID. Why? Because all the subsequent steps revolve around a certain process, which is represented by the order ID.
If the order is cancelled, or if we don't receive a response at some step, we will retry the operation for this order.
Technically, both the delivery service and the payment service are aware of the OrderID in their respective domains, and they are likely to require the OrderID in commands to charge the customer and to initiate delivery.
Thus, a custom idempotency key is redundant since the idempotency key is represented as part of the business domain objects.
Therefore, idempotency is one of the pivotal things in building reliable and predictable distributed systems.
Now, let us take a look at another problem related to asynchronous processing.
Asynchronous processing
There are operations that are better processed asynchronously, meaning that instead of doing the job right now, we push it into the task queue and then notify the originators about the result once it is ready.
It could be useful if interaction is required with external systems that may be slow, operate asynchronously, having strict rate limits, or even have problems with availability.
Okay, what's the problem?
Let us imagine that we have the following system where the main components are:
(Originator) Revenue calculation service - This service is part of an analytics product that periodically requests data for the purpose of calculating revenue. It might analyze sales transactions, payments, or other financial data to provide insights into revenue trends, performance against forecasts, and areas for financial improvement.
(Originator) Risk assessment service - This service evaluates the risk associated with various operations or transactions. It could be assessing credit risk, fraud risk, operational risks, or other types of financial or non-financial risks. Its purpose is to mitigate potential losses by identifying high-risk scenarios and suggesting preventive measures.
Transaction Categorisation service - This service schedules transactions classifications into categories such as groceries, utilities, entertainment, revenue, etc.
Categorization Processor service - This service is purely a backend service responsible for the actual processing and categorization logic of transactions.
Webhooks delivery service - This service manages the sending of webhooks, which are automated messages sent from one app to another when something happens.
Bank transactions provider service - This service acts as an interface to bank systems for retrieving transaction data. It may authenticate, fetch, and format bank transaction data for use by other components in the financial technology ecosystem.
Queue (Kafka / Azure Service Bus / RabbitMq / etc)
In the following diagram, you can see a blueprint of use cases. Both use cases consist of seven steps, starting with 10 Pull transactions for the last period (month or year) and ending with retrieving processing results by ID.
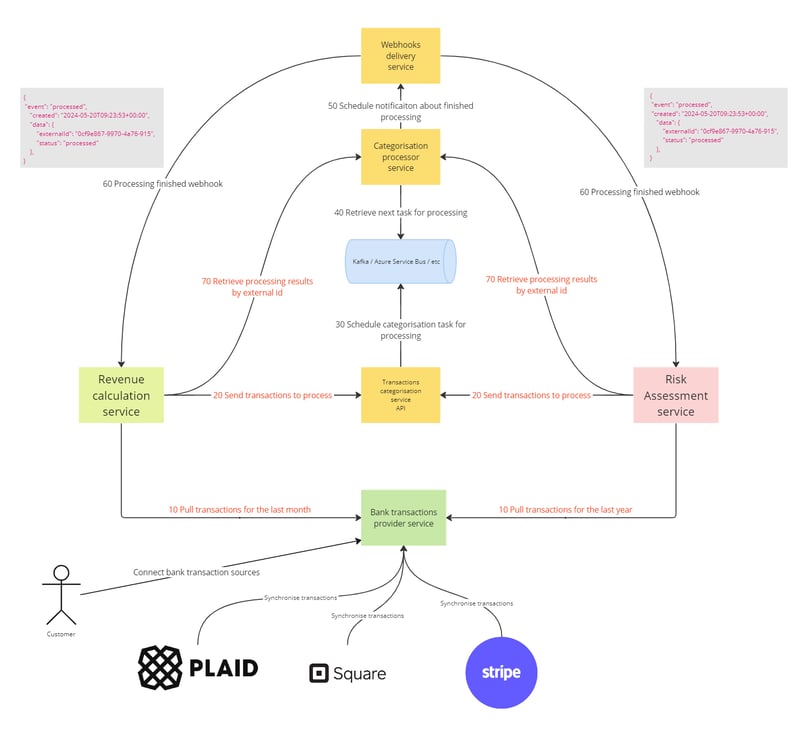
The Transaction Categorization service API requires the provision of an external ID. Under this external ID, all the transactions will be held and categorized. Since the architecture of the transaction categorization implies that it learns over time from data associated with a specific external ID, sending transactions for the same entity (for example, a B2C company) to different external IDs will lead to categorization issues and poor quality. Therefore, the main recommendation is to accumulate all transactions for the same entity together. Consequently, both the Revenue Calculation and Risk Assessment services provide a shared CustomerId throughout the entire system.
{
"event": "processed",
"created": "2024-05-20T09:23:53+00:00",
"data": {
"externalId": "0cf9e867-9970-4a76-915",
"status": "processed"
},
}
This is the webhook payload example received by both originators (Revenue Calculation and Risk Assessment services). However, since they use the same external ID, how can we distinguish between the two originators? Relying on the date? Unlikely, as it is not a reliable approach.
Okay, what if we prohibited having multiple processings in progress for a specific external ID?
This approach might slightly improve the situation if the originators somehow track that they have started processing. However, a problem arises if the first originator begins processing and finishes, but the webhook doesn't reach the originator for any reason. Meanwhile, another originator starts and successfully completes another processing, and the webhook is delivered to both. In this case, we will face an issue because the first originator might mistakenly pick up the second webhook.
Technique 1: Metadata
In order to distinguish webhooks somehow, we may utilize attaching custom metadata to the send transaction to process the request.
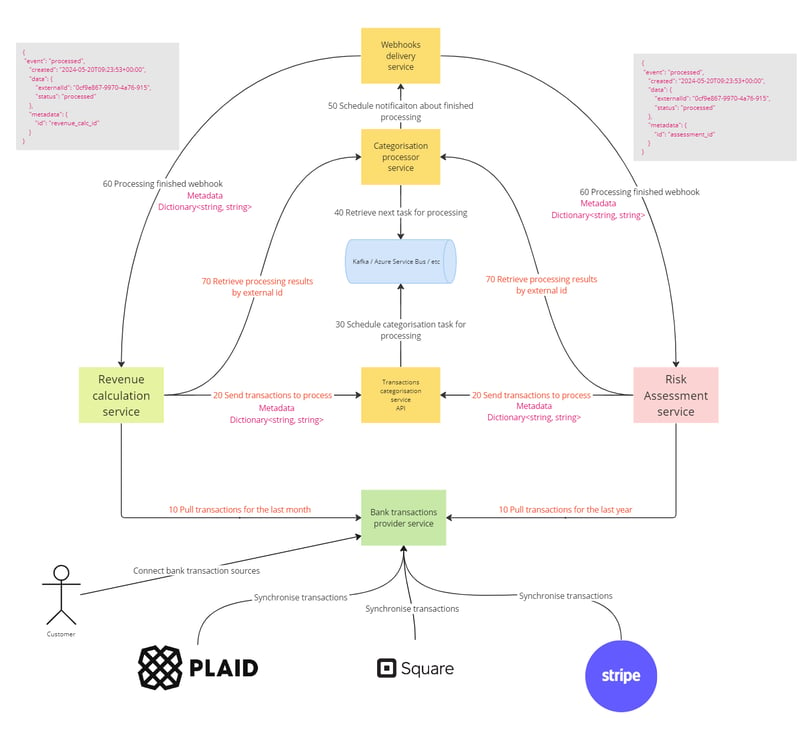
As you can see here, in this example, the Revenue Calculation service attached specific metadata in order to identify its processing result and skip others.
{
"event": "processed",
"created": "2024-05-20T09:23:53+00:00",
"data": {
"externalId": "0cf9e867-9970-4a76-915",
"status": "processed"
},
"metadata": {
"id": "revenue_calc_id"
}
}
However, since the categorisation processing service does not support searching by metadata due to potential complexity, we still face a situation with a race condition when webhooks are delayed, sent out of processing order, or when originators are pulling stale data.
Okay, then we need something much simpler!
Technique 2: Two-Steps processing
To completely avoid race conditions due to the distributed nature of the system and network failures, we can improve the architecture by introducing the following features.
- Sending transactions to the Process API will return a task ID related to this processing.
- The Send Transactions to Process API will accept an idempotency key to avoid starting duplicate tasks. It won't affect consumers but will save resources and reduce operational complexity.
- Task IDs will be added to the webhook payload.
- The Retrieve Processing Results API will be improved to allow searching by task ID.
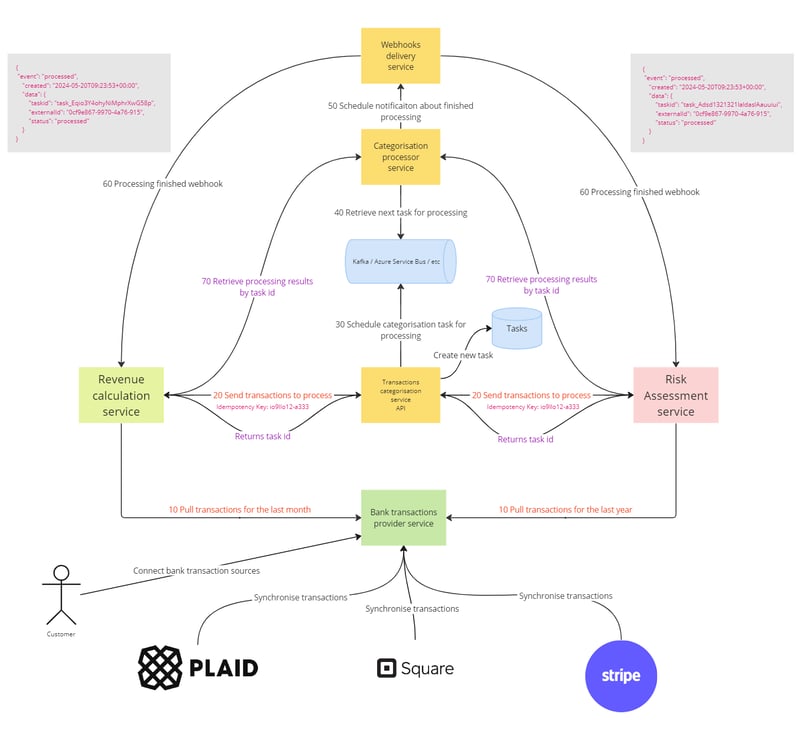
This is the payload example contains taskid value. Thus, originators can distinguish between webhooks and identify only those that are related to them.
{
"event": "processed",
"created": "2024-05-20T09:23:53+00:00",
"data": {
"taskid": "task_Eqio3Y4ohyNiMphrXwG58p",
"externalId": "0cf9e867-9970-4a76-915",
"status": "processed"
}
}
Asynchronous processing and timeouts
The last thing I would like to talk about in this article is related to timeouts.
In nature, there are two main types of communication between two services or components: Fire and forget and Request and Reply.
Fire and forget
This is a communication pattern where a client sends a message (or request) to a server and immediately continues its execution without waiting for a response. The server might process the message at some point in the future, but the client does not know when or indeed if the message has been successfully received or processed. Technically, it even doesn't care wherther it was processed or not.
Usually, this pattern refers to asynchronous nature and is used when the client does not require an immediate response or confirmation. It's often used for logging, sending notifications, or other tasks where receiving a response is not critical to the continuation of the client's processing.
Request and Reply
This is a communication pattern where a client sends a request to a server and waits for a response. The server processes the request and then sends back a reply to the client.
Usaully, this pattern refers to synchronous nature, meaning the client blocks and waits until the response is received before continuing its execution.
However, the interesting thing is that even when I use asynchronous (non-blocking for current execution) communication for account charging or order delivery, I am still interested in a reply. If there is no reply after some time, what should the system do? Cancel? Retry? Send an alert to the on-call team?
The main idea is that despite the communication approach you use (synchronous or asynchronous), you should be concerned about possible network failures and plan for them before they happen.
The simplest approach would be to incorporate a timeout on the caller side, similar to what we have in a blocking request. To implement this, we need to understand where to store the expiration date. The answer lies in the domain objects. Timeout behavior is usually part of their lifecycle. For instance, if a document request for a loan application isn't completed within 14 days, we should close this document request and probably try again.
Conclusion
In this article, I talked about one of the necessary techniques for building a predictable and reliable API. Also I have covered several problems related to the nature of distributed systems and the complexity of asynchronous operations, unavoidable network failures, and possible techniques to mitigate them, thereby improving the quality attributes of the system and experience for both customers and internal users.
See you next time!
Posted on March 26, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.