
Vladislav Filinkov
Posted on May 22, 2023
Introduction:
Job hunting can feel like a wild roller coaster ride, full of peaks, valleys, and unexpected turns.
- Resume Format Frustrations: Hours spent polishing your resume can seem pointless if it doesn't fit a specific format. The ATS (Applicant Tracking System) has no room for non-conformity, just like many recruiters. It feels like wrestling with mismatched puzzle pieces.
- Endless Applications: Job applications can feel like an eternal marathon with no end in sight. It seems you're scattering applications like confetti, but responses are as elusive as a lucky clover. The process seems to prioritize quantity over quality, leaving you questioning if your painstakingly crafted cover letters ever get read.
- The Ever-changing Resume: Adapting your resume for each job application can feel like you're continuously dressing up your qualifications to fit the mold of the day, often spending more time on this than on actual work-related tasks.
- The Feedback Void: After application and interview, you're often left waiting in silence. Feedback is a rarity, making the job hunt feel like casting calls into the abyss, with no echoes to guide you.
Navigating job hunting can be arduous, but I hope this humorous look at its challenges brings you a smile. It's essential to step back sometimes, have a laugh, and remember that this roller coaster ride is a shared experience. Happy job hunting!
What if we can solve these problems?
Imagine a job-hunting utopia requiring minimum effort. Although we can't address all problems but we can surely tackle a few.
- Create a resume whatever you want. Describe everything you think is important, feel free about the format and size of description.
- Do not need an application anymore - just upload a resume and wait! Wait until our app finds the best fit for you.
- Now you will know exactly what positions your resume is relevant to, and in which open positions you are in what "place" compared to other candidates. The level of openness can be radically different.
The Solution:
The solution revolves around using contextual embeddings and vector similarities.
Embeddings:
Embeddings are mappings of discrete variables to a vector of continuous numbers. They are low-dimensional, learned continuous vector representations of discrete variables within a neural network. Their uses include finding nearest neighbors in the embedding space, serving as input to a machine learning model, and for visualization of concepts and relations.
Contextual embeddings assign each word a representation based on its context to solve the issue of contextual meaning.

In a nutshell, our solution involves these steps:
- We generate embeddings for both CVs and job descriptions.
- We calculate the Euclidian distance between the CV and Jobs (many-to-many)
- This distance indicates the match level between a CV and a job description.
- We identify the top-X CVs for each job and top-X jobs for each CV.
- These lists represent the best-fitting candidates for each job and the most suitable jobs for each CV.
Dataset example:
resumes = [
{
"id": "1",
"name": "John Doe",
"description": "Software engineer with 5+ years of experience in Python and JavaScript."
},
{
"id": "2",
"name": "Jane Doe",
"description": "Digital marketing specialist with a focus on SEO and content creation."
},
…
jobs = [
{
"id": "1",
"name": "Software Engineer",
"description": "Seeking a Software Engineer with 5+ years of experience in Python and JavaScript."
},
{
"id": "2",
"name": "Digital Marketing Specialist",
"description": "Looking for a Digital marketing specialist with a focus on SEO and content creation."
},
…
High-level concept:

Embedding calculation
In the next segment, I'll share a code example that illustrates how you can generate embeddings using two leading models: Ada from OpenAI and BERT from Hugging Face. I won't be going into detail about choosing the ideal model for your specific needs. Nonetheless, from my investigations, it's clear that in terms of accuracy, OpenAI's model significantly outshines BERT, as well as several other models. Here, we measure accuracy using the chat CV, where we expect the model to precisely identify relevant job ads based on a distance metric.
The Python code snippet provided below outlines how to compute embeddings using the OpenAI Ada model and the Hugging Face BERT model:
import openai
from transformers import AutoTokenizer, AutoModel
import torch
openai.api_key = '<OPENAI_API_KEY>'
# OpenAI API embeddings
def openai_embedding(text, model="text-embedding-ada-002"):
text = text.replace("\n", " ")
return openai.Embedding.create(input = [text], model=model)['data'][0]['embedding']
# Bert Transformer embeddings
def bert_embedding(text):
model_name = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
# Tokenize and encode the text
input_ids = tokenizer.encode(text, return_tensors="pt", max_length=512, truncation=True)
# Get the embeddings
with torch.no_grad():
output = model(input_ids)
hidden_states = output.last_hidden_state
# Calculate the mean of the token embeddings to get the sentence embedding
sentence_embedding = torch.mean(hidden_states, dim=1).squeeze()
return sentence_embedding
# Load the CV to variable
cv = Path('cv.txt').read_text()
cv = cv.replace('\n', '')
# Create embeddings for the CV
cv_embed_openai = openai_embedding(cv)
cv_embed_openai = bert_embedding(cv)
Euclidian distance
Fantastic, we're now ready to move on to the next step: calculating the Euclidean distance between two vectors. However, keep in mind that a singular distance value doesn't provide much insight. For instance, a distance of 12432 - is it a significant or minor distance? This is where the power of relativity comes in. We should calculate the distances between numerous CVs - say 10, 100, or 1000 - and select the top 10 or top 50 CVs that are closest to our job description. The more comparisons we make, the more precise our decision will be regarding the relevance of a CV to the open position.
Now, let's take a look at a basic outline of our architecture
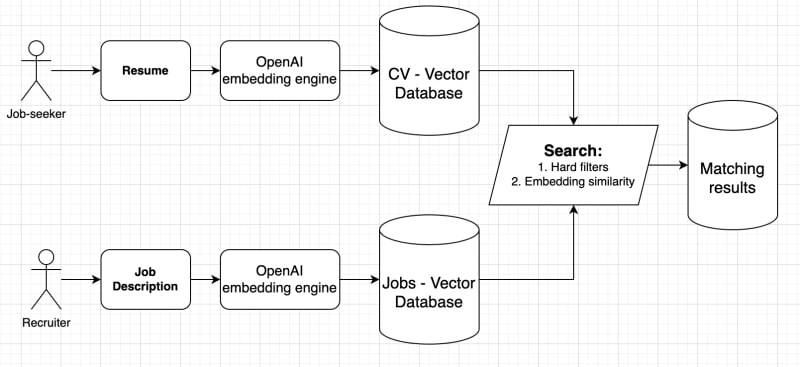
The first step is to establish collections (tables) for the CVs and job descriptions. We will employ MilvusDB, an open-source vector database that is user-friendly and easy to configure. All you need to do is grab the pre-configured Docker compose, and you're good to go! I've decided to omit the part about saving the matching results to a relational database like PostgreSQL, as it's not essential for demonstrating our solution.
Here is an example of how to set this up in Python:
def collection_create(collection_name, dimension):
if utility.has_collection(collection_name):
utility.drop_collection(collection_name)
fields = [
FieldSchema(name='id', dtype=DataType.INT64, descrition='Ids', is_primary=True, auto_id=True),
FieldSchema(name='name', dtype=DataType.VARCHAR, descrition='name', max_length=200),
FieldSchema(name='description', dtype=DataType.VARCHAR, description='description', max_length=20000),
FieldSchema(name='embedding', dtype=DataType.FLOAT_VECTOR, description='CV embedding', dim=dimension)
]
schema = CollectionSchema(fields=fields, description='Datasets descrption')
collection = Collection(name=collection_name, schema=schema)
index_params = {
'index_type': 'IVF_FLAT',
'metric_type': 'L2',
'params': {'nlist': 1024}
}
collection.create_index(field_name="embedding", index_params=index_params)
print(f"Collection '{collection_name}' has been created.")
def openai_embedding(text, model="text-embedding-ada-002"):
return openai.Embedding.create(input = text, model=model)['data'][0]['embedding']
def data_insert(collection_name, data):
collection = Collection(name=collection_name)
for row in data:
ins=[[row['name']], [row['description']], [openai_embedding(row['description'])]]
collection.insert(ins)
time.sleep(1) # Free OpenAI account limited to RPM
print(f"Inserted {len(data)} objects to the {collection_name} collection.")
And the last part is execution.
Here are a few important considerations to keep in mind:
- The process of searching for relevant open positions for a CV and vice versa is technically challenging and represents a classical high-load problem. However, in this discussion, we're not delving into that aspect.
- For our demonstration, we're selecting the top three most relevant jobs. However, in practice, you can choose any number that suits your needs. The more CVs and job descriptions you have, the more relevant the results will be, giving you flexibility in adjusting this variable.
- It's crucial to understand that our approach to relevant search is based on the entire description, rather than just tags, keywords, or other simplified elements. This approach offers the freedom to create a solution that is highly productive and adaptable to your specific needs.
if __name__ == "__main__":
# Connection to the Milvus DB
connections.connect(host='localhost', port='19530')
print("Connected to Milvus DB...")
# Create collections for resumes and jobs
collection_create('resumes', 1536) # The dimension of your embeddings should match the output of the model used. Here it is assumed to be 768.
collection_create('jobs', 1536)
# Insert the data into the respective collections
data_insert('resumes', resumes)
data_insert('jobs', jobs)
# Demonstrate a search
cv = resumes[0]['description'] # Let's say we're searching for jobs that match the first resume
name = resumes[0]['name']
print(f"Let's find related jobs for {name}")
print(f"His CV is {cv}")
print(f"Search results:")
print(search('jobs', cv, 3)) # The 3 most relevant jobs will be printed
Connected to Milvus DB...
Collection 'resumes' has been created.
Collection 'jobs' has been created.
Inserted 10 rows to the resumes collection...
Inserted 10 rows to the jobs collection...
Let's find related jobs for John Doe
His CV is Software engineer with 5+ years of experience in Python and JavaScript.
Search results:
[{'name': 'Software Engineer', 'description': 'Seeking a Software Engineer with 5+ years of experience in Python and JavaScript.', 'distance': 0.07440714538097382}, {'name': 'Content Writer', 'description': 'Seeking a Content Writer specializing in tech and software development topics.', 'distance': 0.3115929365158081}, {'name': 'IT Consultant', 'description': 'Looking for an experienced IT consultant with a background in network security.', 'distance': 0.3668628931045532}]
Link to the python source code
Additional Considerations:
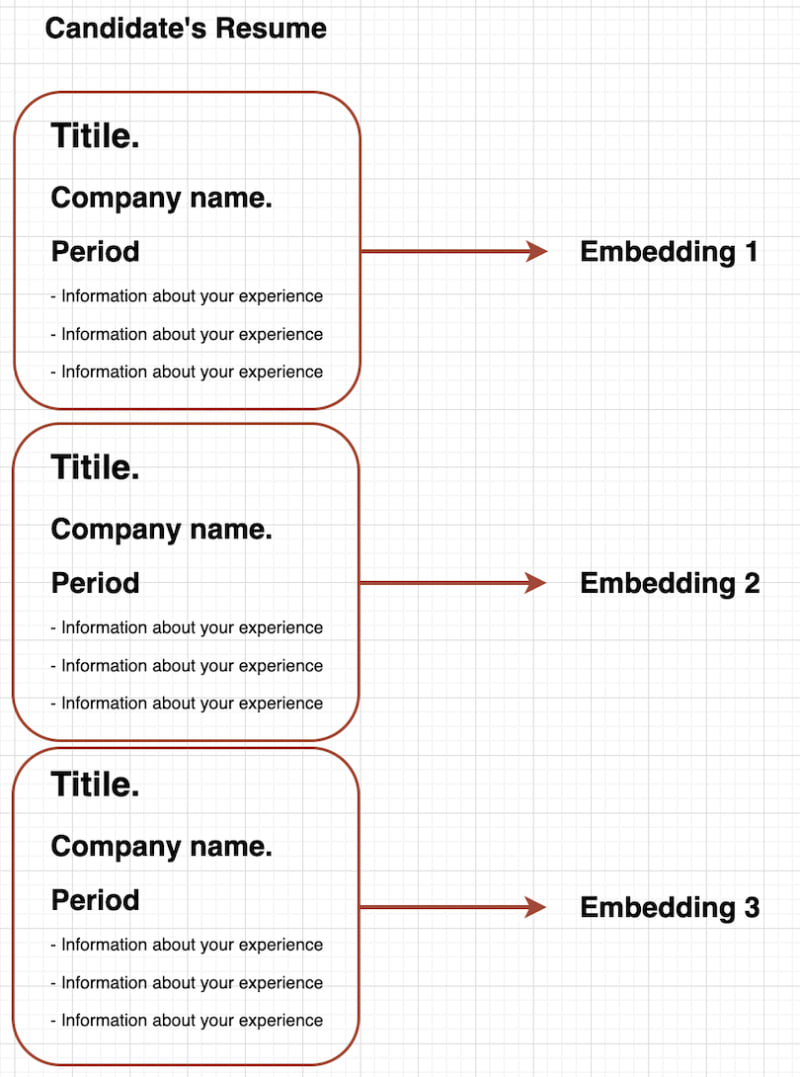
Recruiters typically search for candidates with "relevant experience," which is a significant aspect of their decision-making process. To cater to this, we could match individual sections of a CV, each representing different periods of a person's work history, instead of the entire CV. This approach would allow us to identify candidates whose most recent job aligns perfectly with what the recruiter is looking for, even if their overall CV isn't as relevant. Consequently, this would significantly boost such candidates' chances of being considered for the position.
In conclusion, envisioning this as an open-source project could indeed be a game-changer, aiming to solve the longstanding issues in recruitment in a more effective manner. By eliminating opaque mechanisms and introducing transparent and open algorithms and results, we can revolutionize the recruitment process.
Thank you for joining us on this exploration! I hope you found this article insightful. Enjoy the rest of your day!
Posted on May 22, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.