Text Generation with Artificial Intelligence: Generation of Target Sentences with Q-Learning Algorithm

Ertugrul
Posted on March 21, 2024

1. Introduction
Artificial intelligence and machine learning stand as some of the most exciting fields of our era, offering vast potential in various applications such as creating human-like intelligence, solving complex problems, and making data-driven decisions. Within this scope, subfields like natural language processing (NLP) focus on understanding, processing, and generating human language.
In this article, we will focus on an application of the Q-learning algorithm in the field of natural language processing. Specifically, we will tackle the task of generating a specific target sentence. Q-learning is a type of reinforcement learning technique that relies on the agent (here, the algorithm) interacting with its environment to develop strategies for obtaining the highest reward. Using this method, we will teach the algorithm to generate the required character sequence to form the target sentence and enable the model to produce the desired text.
In this section, we will provide a general introduction to artificial intelligence and machine learning concepts, then focus on the fundamental principles of the Q-learning algorithm. Next, we will introduce the specific problem this article will focus on and the approach it will use. Finally, we will give an overview of the topics to be covered in the rest of the article.
1.2 What is the Q-Learning Algorithm and Where is it Used?
Q-learning is one of the reinforcement learning algorithms. This algorithm aims to select the best action by using the information that an agent (e.g. an artificial intelligence) learns from its environment by interacting with it. The Q-learning algorithm shapes the agent's behavior through feedback such as reward and punishment. This algorithm is especially used in situational decision-making problems (e.g. games, robotics and automatic control systems).
In the following sections of this paper, we analyze the application of Q-learning to the text generation problem. In this problem, it will be shown how to train the model using the Q-learning algorithm to generate a target sentence and how to use it to produce the desired text.
2 Problem

The text generation problem is a sub-field of artificial intelligence techniques that aims to automatically generate a given text (usually a sentence or a paragraph). In this problem, a target text or sentence is specified and the goal is to train a model that can generate this text. Such a model has an important application in the field of natural language processing (NLP) and is widely used in the development of text-based systems.
2.2 Relationship between Targeted Sentences and Characters
In this particular case, the targeted expression is Hello, how are you?. This expression is a basic example of communication and the text generation model is intended to be able to generate this expression. To generate this utterance, the model has to go step by step, choosing the right character at each step. However, the model's success in character selection will be learned and improved by the Q-learning algorithm.
2.3 Problem Solving Approach with Q-Learning
To solve this problem, the Q-learning algorithm is used to model the text generation process. Q-learning allows an agent (here text generation model) to learn the best action (here character selection) by interacting with its environment. At each step, the model evaluates the current state, chooses an action based on the current state, and updates its behavior based on the reward it receives. This process continues until the target sentence is generated. In this paper, we will focus on the text generation problem and analyze in detail how to use the Q-learning algorithm and how to train the model based on this algorithm. Then, we will focus on the details of using the trained model and evaluating the results.
3. Code Structure and Explanations

In this section, the structure, content and goals of the code used will be discussed in detail. The code includes how the Q-learning algorithm is implemented for the text generation problem. In addition, the libraries used, the roles of the variables and the operation of the algorithm will be explained.
3.2 Content and Objectives of the Code
The main purpose of our code, which we wrote in Python programming language, is to train a vir model that can generate a specific target sentence with the Q-Learning algorithm.
Code Structure:
- Defining the target sentence.
- Determination of characters and alphabet.
- Application of the Q-learning algorithm.
- Realization of the training and learning process._
- Using the trained model and making predictions.
3.3 Libraries and Tools Used
Numpy: A library for numerical calculations, ideal for matrix operations and data manipulation
Source: NumpyMatplotlib: It is a library used for data visualization and will be used to visualize the Q values obtained after training in the form of a heat map.
Source: Matplotlib
3.4 Definitions and Role of Variables
Target sentence: The sentence we want to teach.
sentence = "Hello, how are you?"
Character list: Characters to use while learning
characters = " abcdefghijklmnopqrstuvwxyz,?"
Learning rate: Learning curve
alpha = 0.1 # Learning rate
Discount factor for future rewards:
gamma = 0.9
Epochs: How many times will he learn
num_episodes = 10000
Each of these variables plays a role in determining which action to choose at a given step of the algorithm, how to calculate rewards and how to update the model.
Code 4
In this section we will break down and explain the code piece by piece.
4.2 Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
Here we import the Numpy and Matplotlib libraries.
4.3 Determination of required values
sentence = "Hello, how are you?"
characters = " abcdefghijklmnopqrstuvwxyz,?"
alpha = 0.1 # Learning rate
gamma = 0.9 # Discount factor for future rewards
num_episodes = 10000 # Number of training episodes
Q = np.zeros((len(sentence), len(characters)))
I already explained the values I set here in section 3.3. We just need to explain the value of Q.
Q: Each combination of state and action expresses the value of that combination. This value indicates how desirable or advantageous the action in that situation is. (Here, the situation is the formation of the sentence and the action is the selection of the letters).
4.4 Conducting the training
for episode in range(num_episodes):
state = 0
done = False
while not done:
action = np.random.randint(len(characters))
if status == len(sentence) - 1:
done = True
else
# Determine next state
next_state = state + 1
if sentence[status] == characters[action]:
reward = 1
else
reward = 0
Q[state, action] += alpha * (reward + gamma * np.max(Q[next_state]) - Q[state, action])
state = next_state
Our code is as shown above.
To break it down:
state = 0
done = False
In this section
state is determined by the number 0. This indicates how many letters into the sentence the model is.
done is set to False. This indicates whether a training process has been completed.
while not done:
action = np.random.randint(len(characters))
In this section
- Our While Loop starts and a random character is assigned in action.
if state == len(sentence) - 1:
done = True
In this section:
- If state is at the end of the sentence, we set done to True.
if state == len(sentence) - 1:
done = True
In this section:
- If state is at the end of the sentence, we set done to True. This concludes the tutorial.
else:
next_state = state + 1
In this section:
- If the end of the sentence is not reached, we increment the state value by one and keep it at a value called next_state.
if sentence[state] == characters[action]:
reward = 1
else:
reward = 0
In this section:
- We set reward to 1 if our model correctly predicted the character that should be predicted in the sentence, and set reward to 0 if it did not.
Q[state, action] += alpha * (reward + gamma *np.max(Q[next_state]) - Q[state, action])
state = next_state
In this section
- In this section, we update our Q value with the reward value and other values and provide learning. However, at the end, we set state equal to next_state so that we can transition to the next character in the sentence.
4.5 Making the prediction
The prediction process is simpler than the training process.
predicted_sentence = ""
state = 0
while state < len(sentence):
action = np.argmax(Q[state])
predicted_sentence += characters[action]
state += 1
print("Predicted Sentence:", predicted_sentence)
This is our prediction code. In short:
- We make the model predict each letter of the sentence we want to predict according to the Q value we have trained and save it to a String value in order (Saving part optional)
Example output:
- Trained with 100 repetitions:
![]()
- Trained with 500 repetitions:
![]()
- Trained with 1000 repetitions:
![]()
We will compare the sample outputs in the future, but for now, we can say that the model's ability to predict correctly increases in parallel with the increase in training time. This leads us to the conclusion that the model has learned.
4.6 Visualization of the Model
One of the most important sections is Visualization.
plt.figure(figsize=(12, 8))
plt.imshow(Q, cmap='hot', interpolation='nearest')
plt.colorbar(label='Q Value')
plt.title("Distribution of Q Values")
plt.xlabel("Action (Character)")
plt.ylabel("State")
plt.xticks(np.arange(len(characters)), list(characters))
plt.yticks(np.arange(len(sentence)), list(sentence))
plt.show()
With the code block above, it shows which action our model finds more accurate in which situation. I chose the Heat Map model for this visualization because I think it is simpler to understand and read, but you can try other visualization models as you wish.
Example output:
- Trained with 100 repetitions:
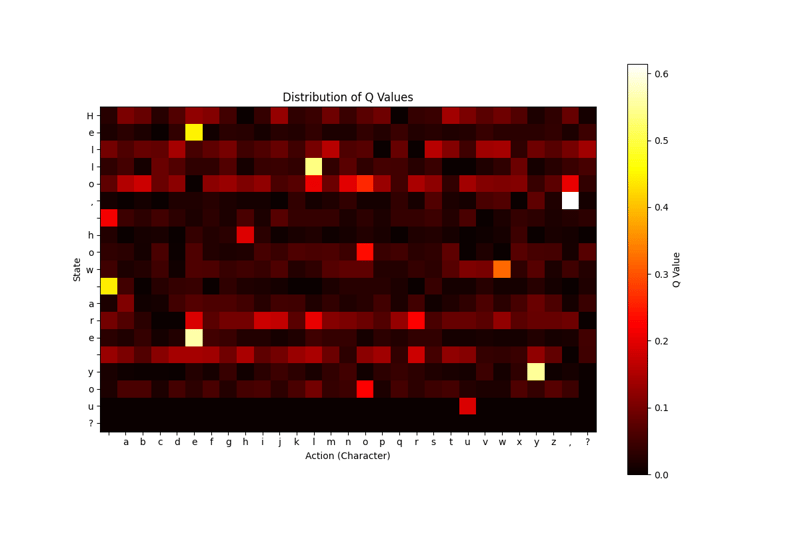
- Trained with 500 repetitions:
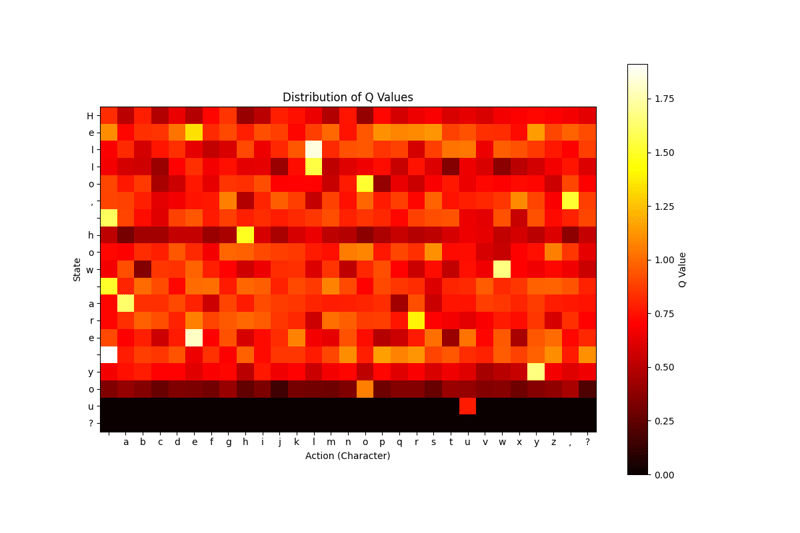
- Trained with 1000 repetitions:
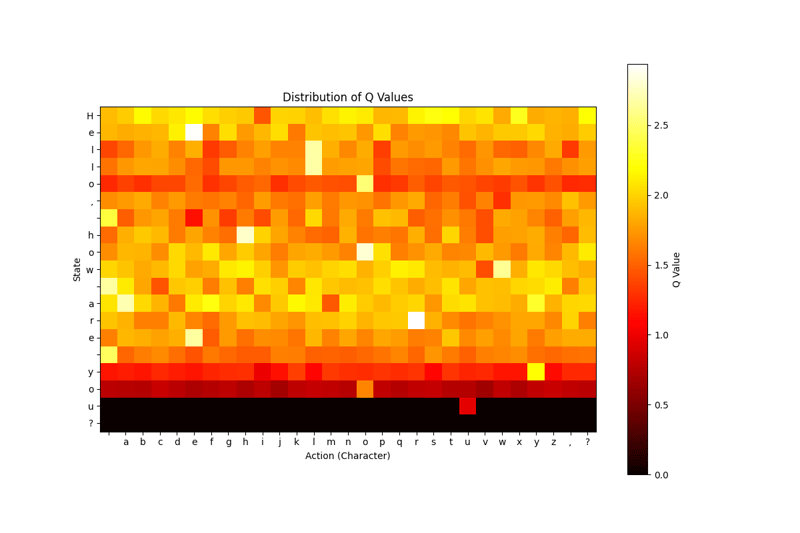
5. Comparing results
- Trained with 100 Repetitions:
![]()
- Trained with 500 Repetitions:
![]()
- Trained with 1000 Repetitions:
![]()
As a result, we have models trained with 3 different number of repetitions (100-500-1000). None of our models knew '?'. The output of the model trained with a hundred repetitions is meaningless, while the output of the model trained with a thousand repetitions is somewhat more understandable.
We also see that; our model trained with a thousand repetitions has learned very well where to use the letter 'E', if we had continued to train a little more or if we had changed our parameters with more accurate parameters, maybe it could have learned the question mark ?
Try this for yourself...
6. Summary and Bibliography
To Summarize:
In this article, we touched on the Q-Learning algorithm with a sentence prediction project. If you want to try it yourself, you can download the code from Github or access the Photos.
Github:
English Resources for further learning:
- https://www.youtube.com/watch?v=qhRNvCVVJaA
- https://www.techtarget.com/searchenterpriseai/definition/Q-learning#:~:text=Q-learning%20is%20a%20machine,way%20animals%20or%20children%20learn.
Turkish Resources for in-depth learning:
- https://www.youtube.com/watch?v=zDKGmJMGoDg
- https://medium.com/deep-learning-turkiye/q-learninge-giriş-6742b3c5ed2b
If you have a "Suggestion-Request-Question", please leave a comment or contact me via e-mail...
💖 💪 🙅 🚩
Ertugrul
Posted on March 21, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.