Spin up a new Elasticsearch cluster?

Nishu Goel
Posted on August 8, 2023

This post explains how to setup a new elasticsearch cluster from scratch and make it ready to be used for indexing data into, communicating to/from as a remote cluster, along with setting up monitoring for the new cluster.
Problem 1: Create a new elasticsearch cluster on elastic.co based on the required configuration for your use case.
To create a new cluster from scratch:
Create a main.tf file with following resources:
a. ec_deployment - The main cluster deployment resource
b. aws_secretsmanager_secret- The cluster secrets
c. aws_secretsmanager_secret_version - The cluster secret version needed for the secrets
d. elasticstack_elasticsearch_cluster_settings - To add default settings to the cluster like cluster nodes etc.
Example: ec_deployment
resource "ec_deployment" "<cluster-name>" {
name = "<cluster-name>"
region = "aws-eu-central-1"
version = var.elasticsearch_version
deployment_template_id = standard/arm-based (decide based on the requirement)
elasticsearch {
autoscale = "false"
topology {
id = "hot_content"
size = "15g" // size of the cluster
zone_count = 3 // number of nodes
}
}
kibana {}
// important to include this in the cluster config to ensure to NOT override any existing remote cluster related config
# ignore changes to remote cluster config
lifecycle{
ignore_changes = [
elasticsearch[0].remote_cluster
]
}
}
Few important bits to note in this:
Ensure the region and ES version are consistent for your cluster.
By default, deployment_template_id should be defined as standard aws-storage-optimized-v3 but if your are creating the cluster for memory-intensive work, consider creating it as arm-based aws-general-purpose-arm-v6
The size and number of nodes vary based on the need, so decide it accordingly from the Elastic Cloud UI.

An important bit to always add in your cluster deployment is to ignore changes to the remote cluster config. This ensures the remote communication that is configured among clusters doesn’t get overriden by this update.
ignore_changes = [
elasticsearch[0].remote_cluster
]
Example: Cluster Secrets
# Create the AWS Secret Manager secret
resource "aws_secretsmanager_secret" "<cluster-secret-name>" {
name = "/elasticsearch/<cluster-name>/credentials"
description = "Elasticsearch credentials for <cluster-name> cluster"
}
# Create the AWS Secret Manager secret version with JSON value
resource "aws_secretsmanager_secret_version" "<cluster-secret-name>" {
secret_id = aws_secretsmanager_secret.<cluster-secret-name>.id
secret_string = <<JSON
{
"endpoint": "${ec_deployment.<cluster-name>.elasticsearch.0.https_endpoint}",
"username": "${ec_deployment.<cluster-name>.elasticsearch_username}",
"password": "${ec_deployment.<cluster-name>.elasticsearch_password}"
}
JSON
}
Example: cluster_settings
resource "elasticstack_elasticsearch_cluster_settings" "<cluster-settings>" {
elasticsearch_connection {
username = ec_deployment.<cluster-name>.elasticsearch_username
password = ec_deployment.<cluster-name>.elasticsearch_password
endpoints = [ec_deployment.<cluster-name>.elasticsearch.0.https_endpoint]
}
persistent {
setting {
name = "cluster.max_shards_per_node"
value = "2500"
}
setting {
name = "cluster.routing.allocation.cluster_concurrent_rebalance"
value = "30"
}
setting {
name = "cluster.routing.allocation.node_concurrent_recoveries"
value = "30"
}
}
}
Three important settings that would make sense to add as default 👆
-
max_shards_per_nodethe value would vary based on the cluster size and requirement -
cluster_concurrent_rebalanceTo allow correct rebalancing of shards to all available nodes (20-30 is a good value for this) -
node_concurrent_recoveriesTo allow correct rebalancing of shards to all available nodes (20-30 is a good value for this)
Above steps will create a cluster with the defined config. ✅
Always good to ensure and check what our changes are adding/updating/deleting, to be extra cautious to NOT end up deleting/updating some existing resource. 😨
Problem 2: Add the newly created elastic cluster to the POOL of clusters in the DynamoDB Cluster assignment table
Now that the new cluster is and available to view on elasticsearch as a healthy deployment, we can make the next move to include it in the list of available clusters, to be able to then use it for our ES needs.
example:

To add it to the pool, you can assign it to the table where cluster assignment is defined, in our case: ClusterAssignmentTable
To add your new cluster to this pool, use:
json=$(cat <<EOF
{
"pk": {"S": "POOL"},
"sk": {"S": "CLUSTER#${cluster_name}"},
"cluster": {"S": "${cluster_name}"},
"endpoint": {"S": "${endpoint}"},
"username": {"S": "${username}"},
"password": {"S": "${password}"}
}
EOF
)
echo "===> Storing cluster $cluster_name in table $table_name..."
aws dynamodb put-item \
--table-name $table_name \
--item "${json}"
As a result of this, the new cluster should be found in the cluster assignment table.
Problem 3: Allow it the access to communicate to/from other existing ES clusters.
When dealing with multiple ES clusters, there is the requirement to query data from one cluster to another. In the current implementation, we already have use cases of doing multi-org queries where those orgs could belong to different clusters.
Usage looks like:
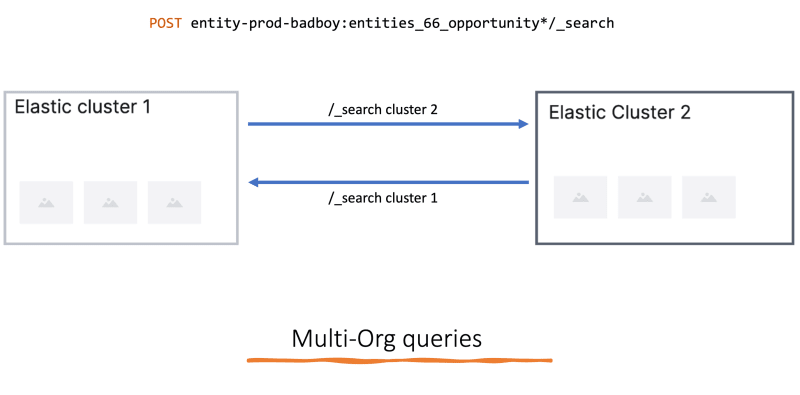
To allow this, we need to ensure, every time a new cluster is created, its also set up for the remote cluster communication.
To do this, you could do something like for all your clusters in the pool:
payload=$(cat <<EOF
{
"persistent": {
"cluster": {
"remote": {
"${remote_cluster}": {
"mode":"proxy",
"server_name": "${remote_server_name}",
"proxy_address": "${remote_proxy_address}",
"skip_unavailable": true
}
}
}
}
}
EOF
)
curl -sS -X PUT "$endpoint/_cluster/settings" \
-u "$username:$password" \
-H 'Content-Type: application/json' \
-d "$payload" | jq
This will ensure all the clusters for that environment are setup for remote communication to one another.
Also, remember we had that extra step to ignore changes to the remote cluster config? This is why! We DO NOT want to override any remote config changes when updating clusters.
At this point, you have your cluster ready on elasticsearch, cluster allocation table, and also able to talk to other clusters 💪
And then there are the Not-so-good times when clusters are not doing that great and healthy.
With these many clusters (even more probably in the future), we want to know the whereabouts of each of them, to be better at managing these.
So a cluster specific monitoring is a good idea. We do that using Datadog. Datadog provides a Elastic Cloud integration that can be used for the same.

Something like above 👆
Hope this helps!
Posted on August 8, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related