
Sanchit Balchandani
Posted on May 25, 2023

Introduction:
In today's data-driven world 🌐, managing and interpreting substantial amounts of data has become increasingly vital. We often encounter scenarios where JSON files flood our AWS S3 buckets, demanding efficient processing. In this blog, I will share a recent use case where I successfully used AWS Glue, Python, and Terraform(mainly to handle infra) to tackle the challenge of processing a deluge of small JSON files efficiently.
Background:
Data handling at scale can be an arduous task, especially when dealing with a continuous influx of JSON files. I was asked to process approximately 1 million small JSON files per hour which are landing into an s3 bucket! 🕰️ These files needed to be transformed into larger, more manageable XML files for further analysis by another application. To address this demanding task, I leveraged the power of AWS Glue and other technologies to create a robust and scalable data processing pipeline.
Tech Stack:
Terraform for creating AWS Resources 🏗️
Glue, S3, Systems Manager, Cloud Watch services from AWS 🛠️
Python for writing the Glue Scripts 🐍
Overcoming the Small Files Problem with Glue:
The first hurdle I encountered was the infamous "Small Files Problem" within AWS Glue. This challenge arises when the Spark driver in AWS Glue is overwhelmed with list() method calls to S3, leading to memory exhaustion and, unfortunately, job failures. The first iteration of my solution ran for 6 hours and, you guessed it, failed due to a memory error. 😅

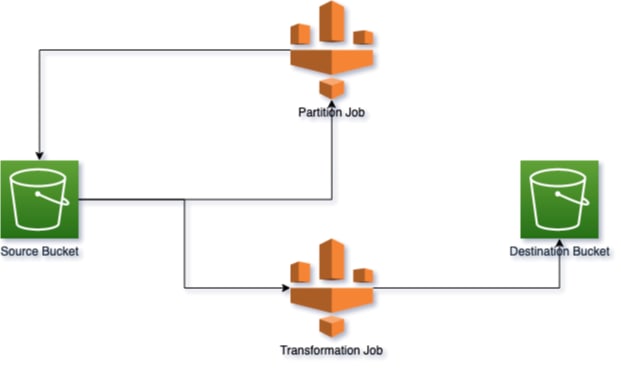
To combat this issue, I devised a primary Glue job written in Python, leveraging PySpark and Boto3. This job merged multiple small JSON files into larger ones based on a configurable parameter, mitigating the Small Files Problem. It also optimized downstream processing by partitioning the merged files into date-based folders within the S3 bucket. I saved the files in the following format:
YYYYMMDD/HHMM
This approach helped me run this partition job multiple times per day, partitioning files based on specific hours. This made the main transformation job, running at midnight, more efficient as it dealt with fewer files.
Transforming and Optimizing Data Processing:
The secondary, or main, Glue job was designed to initialize a Spark session and fetch essential parameters like batch size and date from the AWS Systems Manager (SSM) Parameter Store. This job processed the JSON files in batches using Spark's inherent capabilities. I used the popular Python library xml.etree.ElementTree to convert JSON data into the desired XML format. To optimize storage and write performance, the transformed data was compressed using gzip before being written back to the S3 bucket.
Here is the high-level architecture
The Fruitful Outcome:
The result? A super-efficient pipeline that processed approximately 70k files in less than 2.5 minutes! 🚀 This feat required 10 Data Processing Units (DPUs) in AWS Glue. However, the solution is scalable and can accommodate additional DPUs to meet future requirements. With the current setup, it can easily process 1 million JSON files in around 35 mins which is quite fast and seems scalable as well.
Key Takeaway: The Power of Synergistic Tools and Strategies
The experience of using AWS Glue, Python, and Terraform to handle large amounts of JSON data highlights the significance of using the right combination of tools and strategies to address big data challenges successfully. As data keeps growing rapidly, AWS Glue offers a reliable platform for creating strong data processing pipelines. Python's flexibility allows for intricate data transformations, and Terraform helps optimize infrastructure efficiency. By leveraging these synergistic tools and strategies, you can effectively tackle the complexities of big data processing. 🏗️👏
P.S. - Thanks to generative AI for the edits ;) and making my English look better. The use case is real though :D
Posted on May 25, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related