Fake Data with Google Back-Translator API!

Elahe Dorani
Posted on May 6, 2023

Machine learning requires techniques to address the challenges of working with terribly imbalance datasets. Data Augmentation is a class of techniques you can use to generate fake data.
SMOTE
One of the most popular ways to create fake data for multimodal datasets is the SMOTE technique, which can be applied to numerical and categorical features.
SMOTE technique is based on the KNN algorithm. You can read more about this technique here:
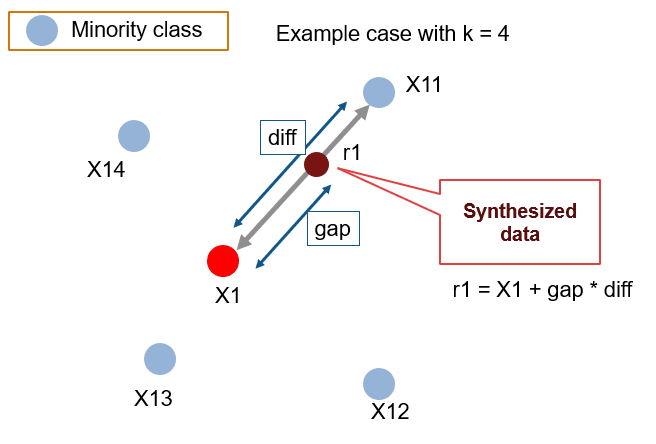
Although SMOTE technique can be a nice data generator for numerical and categorical features, when we apply it to the text data, it can be biased due to duplicate text samples. On the other hand, it can inject noisy samples to the dataset.
In a real project, we were tackling with an imbalance multimodal dataset. The issues we were targeting to handle in this dataset were:
-
Multimodality: there where
numerical,categoricalandtextfeatures in this dataset. - Sever imbalance: there were a terribly unequal proportion between the classes, e.g. 98 of Class1 and 2 percent of Class2.
- Lack of data: there were just about 80 samples of the minority class.
- Non-English text: the text feature was in Persian. It was important to generate a similar text data with an eye on keeping it more alike to the original one.
Back-Translation Technique
As I described before, we were suffering from the lack of data for the minority class. Using the SMOTE technique, injected copied text samples to the dataset and did not improve the model. So, we need a more efficient technique.
Filtered Back-Translator was a great idea to handle this issue.
Google back-translator is a pretrained generative language model, which is in access calling it as an API. This model generates high-quality fake text data by translating text multiple times between the original and another language, thereby creating new text samples that are similar to the original. This picture shows the whole procedure in simple:
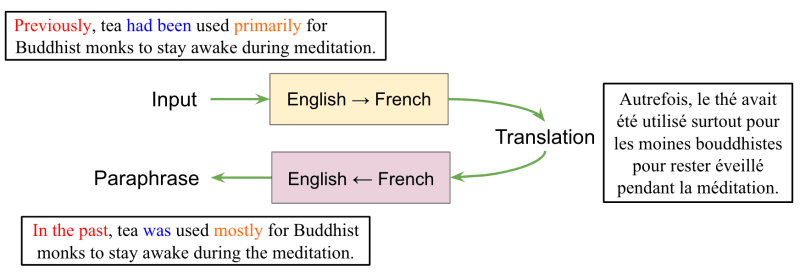
Since the translations are performed by Google's translation engine, the generated text is of high quality and can be used for data augmentation and model testing.
The Google back translator has several advantages:
- First, it requires no training data or model training, making it an easy-to-use API for generating new data.
- Second, the high-quality generated text is due to the popularity of Google's search engine and its expertise in generating this model.
- Finally, the generated text can be used for various applications, such as improving the performance of machine learning models.
To sum up...
Generating fake data is an important technique for addressing severe imbalances in datasets in machine learning. SMOTE is a popular approach, but it cannot be applied directly to text data. The Google back translator is an alternative approach that produces high-quality results and can be used to augment text data. By combining SMOTE and the Google back translator, it is possible to create fake data for multimodal datasets that include text data, resulting in improved machine learning model performance.
We successfully used the Google back translator to generate more text data for a project with an imbalance of 98-2 in the class distribution, resulting in a 20% improvement in the F-score and a more reliable model.
Posted on May 6, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related