The Complete Guide to Time Series Models.

Denzel Kanyeki
Posted on November 7, 2023
In this post, I would like to cover in detail what is time series analysis and time series models. Let's first answer the question, What is a time series model?
A time series model is a model used to make predictions on data over a sequence of time intervals. We use these models to understand data such as:
- stock prices by making stock market predictions,
- weather forecasting and making future weather predictions,
- economic indicators among others
Time Series Models are important in Data Science as they allow data scientists and analysts to understand and analyze the patterns and trends of time-dependent data.
There are various types of Time Series Models as stated below:
(a) Statistical Models:
Statistical models are time series models based on statistics are tools that help analyze and predict data arranged in chronological order. These models prove valuable when dealing with regularly collected data over time, such as daily stock prices monthly sales figures or hourly temperature measurements.
Examples of such include:
(i) Auto-Regressive Integrated Moving Average (ARIMA) models- This model combines both Auto-Regressive(AR) and Moving Average(MA) components and also incorporates differencing to make the time series stationary.
(ii) Auto-Regressive (AR) models- These models rely on the concept that the present value of a time series is determined by a combination of its past values. The basic version is the AR(1) model, which only takes into account the immediate past value. However more intricate variations such AR(p) (of order p) model , as models take into consideration multiple past values.
(iii) Moving Average(MA) models - These models assume that the current value depends on a linear combination of past random error terms. The simplest form is the MA(1) model, which considers only the previous error term, but MA(q) (order of q) models consider (q) past error terms
(b) Machine Learning (ML) models:
Machine Learning (ML) models are commonly used in time series analysis for various tasks which include, forecasting, classification, and pattern recognition.
There are different types of ML models which include:
(i) Auto-Regressive Integrated Moving Average (ARIMA) models: While ARIMA is also a statistical model, it is used alongside Machine Learning algorithms to understand and interpret time related data.
(ii) Seasonal Decomposition of Time Series (STL) models- STL is a decomposition method used to extract seasonal, trend, and remainder components from a time series.
(iii) Convolutional Neural Networks (CNNs)- CNN's are used in image analysis but can also be used in analysis of 1 dimensional (1D) data to capture local patterns and trends
(iv) Recurrent Neural Networks (RNNs)- Traditional RNNs can be used for time series forecasting and modeling but newer forms of RNN such as Long Short-Term Memory (LSTM) Networks and Gated Recurrent Unit (GRU) Networks are more popular due their ability to counter the limitations of traditional RNNs.
So as to show how time series models are used in the understanding and analysis of time-series data, I'll illustrate by use of an example.
Let's say we have a dataset which contains gold prices from 1950 to 2020 and we'd like to analyze and predict the gold prices in a few years using Time Series models.
You can access the dataset here:
Let's get started!
1. Data Preparation.
a) Install and import necessary libraries.
If you don't have these libraries installed on your machine. download them using the pip package installer for Python via the Terminal or Command Prompt. For example, let's install the statsmodels package.
pip install statsmodels
After installing your libraries, import them in your code to use them.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from statsmodels.tsa.api import ExponentialSmoothing, Holt, SimpleExpSmoothing
from sklearn.linear_model import LinearRegression
b) Prepare your dataset.
After installing and import the necessary libraries, you can load and prepare your dataset as follows. NOTE: Check the path and location of your dataset before loading it.
df = pd.read_csv(gold_prices.csv) # Check your path before loading
c) Start cleaning and checking your data:
Check for the duration which gold prices have been set in the dataset
print(f"The gold prices date range from {df.loc[:, 'Date'][0]} to {df.loc[:, 'Date'][len(df) - 1]}")")
# Checks for date range of gold prices in dataset
Prices of gold range from 1950-01 to 2020-07
We need also to change the "Date" column to a datetime type.
date = pd.date_range(start='01/01/1950', end='08/01/2020', freq='M')
date
DatetimeIndex(['1950-01-31', '1950-02-28', '1950-03-31', '1950-04-30',
'1950-05-31', '1950-06-30', '1950-07-31', '1950-08-31',
'1950-09-30', '1950-10-31',
...
'2019-10-31', '2019-11-30', '2019-12-31', '2020-01-31',
'2020-02-29', '2020-03-31', '2020-04-30', '2020-05-31',
'2020-06-30', '2020-07-31'],
dtype='datetime64[ns]', length=847, freq='M')
2. Data Exploration.
After data preparation and cleaning, we need to explore our dataset and create visualizations based on the same.
In this dataset, we need to change the 'Date' column to be a 'Month' column for easier and broader analysis. For this, we rename the column to 'Month' and set it to the 'date' variable we created earlier
df['Month'] = date
df.head()

Let's set the 'Month' column to be the index column of the dataset.
df.set_index('Month', inplace = True)
df

After setting the 'Month' column as the index column, lets now create visualizations based on the dataset using data visualization techniques e.g. matplotlib, seaborn.
If you need a detailed explanation of the techniques, take a look at my previous article:

a) A line chart showing monthly gold prices.
df.plot(figsize=(20, 8))
plt.title('Monthly Gold Prices from 1950 to August 2020')
plt.xlabel('Months')
plt.ylabel('Prices in dollars')
plt.grid()

b) Box plots.
I used boxplots to display the prices of gold per year, and its various movement in prices per year as shown below:
_, ax = plt.subplots(figsize=(25, 8))
sns.boxplots(x = df.index.year, y = df.values[:, 0], ax=ax)
plt.title("Annual Gold Prices from 1950 to August 2020")
plt.xlabel("Years")
plt.ylabel("Prices")
plt.xticks(rotation = 90)
plt.grid()

c) Average Gold Prices per decade and quarterly periods using line charts
For average gold prices per quarterly periods:
quarterly_sum = df.resample('Q').mean()
quarterly_sum.plot()
plt.title(" Average Quarterly Gold Prices from 1950 to August 2020")
plt.xlabel("Quarterly Periods")
plt.ylabel("Prices")
plt.grid()

For average gold prices per decade:
decade_sum = df.resample('10Y').mean()
decade_sum.plot()
plt.title(" Average Gold Prices per decade from 1950 to August 2020")
plt.xlabel("Decade Periods")
plt.ylabel("Prices")
plt.grid()

3. Model training and testing:
For this dataset, I chose to use a linear regression model to make a predictive analysis.
a)Training and testing our model:
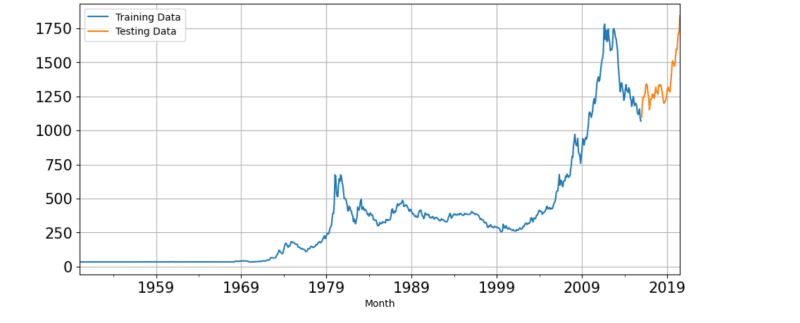
I trained data(historical) before the year 2015 and tested data(future) from 2015 onwards to make an accurate prediction of the future and represented the trained and tested data on a line chart.
train = df[df.index.year <= 2015]
test = df[df.index.year > 2015]
train['Price'].plot(figsize = (11, 5), fontsize=15)
test['Price'].plot(figsize = (11, 5), fontsize=15)
plt.grid()
plt.legend('Training Data', 'Testing Data')
plt.show()
train_time = [i + 1 for i in range(len(train))]
test_time = [i + len(train) + 1 for i in range(len(test))]
LR_train = train.copy()
LR_test = test.copy()
LR_train['time'] = train_time
LR_test['time'] = test_time
lr = LinearRegression()
lr.fit(LR_train[['time']], LR_train['Price'].values)
test_prediction_model_1 = lr.predict(LR_test[['time']])
LR_test['forecast'] = test_prediction_model_1
plt.figure(figsize=(20, 8))
plt.plot(train['Price'], label = "Train")
plt.plot(test["Price"], label = "Test")
plt.plot(LR_test["forecast"], label = "Linear Regression on time_test data")
plt.legend(loc = "best")
plt.grid()

Here, we calculate the MAPE of our dataset. Mean Absolute Percentage Error (MAPE) is a used metric, for assessing the precision of forecasts and predictions in the realm of time series forecasting. It measures the percentage deviation, between predicted and actual values. MAPE is expressed as a percentage. Offers a way to gauge the accuracy of a forecasting model. A lower MAPE indicates a good forecast, with 0% being a perfect one and they are non-negative values.
# A function to define MAPE.
def mape(actual, pred):
return round(np.mean(abs(actual - pred) / actual)* 100, 2)
mape_model_1 = mape(test['Price'].values, test_prediction_model_1)
print(f"MAPE is {mape_model_1}%")
MAPE is 29.24%
After calculating MAPE and using the linear regression to do predictive analysis, let's use a second and final model using the ExponentialSmoothing model we imported earlier.
final_model = ExponentialSmoothing(df,
trend = 'additive',
seasonal = 'additive').fit(smoothing_level = 0.4,
smoothing_trend = 0.3,
smoothing_seasonal = 0.6)
mape_final_model = mape(df['Price'].values, final_model.fittedvalues)
print(f"MAPE is {mape_final_model}%")
MAPE is 17.24%
From the output above, MAPE calculated using the ExponentialSmoothing is lower than the one calculated by Linear Regression, hence the ExponentialSmoothing model is more accurate than Linear Regression.
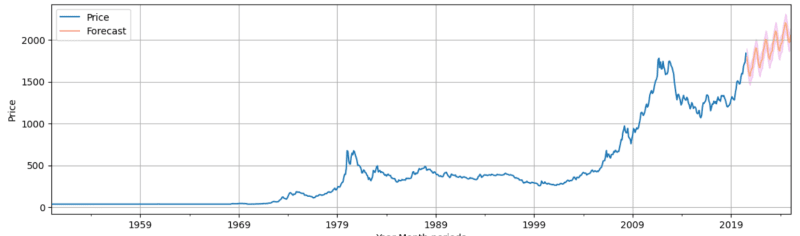
We need to make predictions and determine the upper CI, and lower CI for the data and plot them on a line graph to visualize the future prediction.
new_df = pd.DataFrame({"Lower CI": predictions - 1.96 * np.std(final_model.resid, ddof = 1),
"Predictions": predictions,
"Upper CI": predictions + 1.96 * np.std(final_model.resid, ddof = 1)})
new_df.head(5)

For visualization of the dataframe above:
axis = df.plot(label = "Actuals", figsize = (16, 9))
new_df['Predictions'].plot(ax = axis, label = 'Forecast', alpha = 0.5)
axis.fill_between(new_df.index, new_df['Lower CI'], new_df['Upper CI'], color = 'm', alpha = 0.15)
axis.set_xlabel('Year-Month periods')
axis.set_ylabel('Price')
plt.legend(loc = 'best')
plt.grid()
plt.show()
4. Analysis of the findings above.
From the values and graphs plotted on the results above, we can conclude that:
(i) Gold prices would predictively rise/be in an uptrend to the year 2030.
(ii) The ExponentialSmoothing model is more accurate in predicting the prices in the future than the Linear Regression model by the value of MAPE.
In conclusion, this guide serves as a comprehensive resource for understanding and applying the diverse array of techniques and models in the realm of time series analysis as we have dived into the fundamental concepts, and practical applications of time series models, and shedding light on their critical role in a wide range of fields, from finance to healthcare and beyond.
Posted on November 7, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related
August 2, 2024
