Programming from Top to Bottom - Parsing

DigitalCrafting
Posted on March 18, 2024

In the previous article we saw that there is quite a gap between what we write and what CPU does and we also saw a simplified flow diagram of interpreted and compiled languages.
We will start with interpreted languages, and then move to VM and natively compiled ones, as they are progressively more complicated.
But before all that, let's ask ourselves more general question:
What is programming language built of?
Well, let's start with spoken language. It is built of words and grammar. Words are used to name/describe things/actions, and grammar defines how it can be done. For example, expression high mountain, consists of two words high and mountain. Grammar tell us, that:
- high is an adjective,
- adjectives describe things,
- mountain is a noun,
- nouns name things,
- adjective must come before noun.
Thanks to those simple rules, we know how to decipher the expression high mountain, and many more like that.
Getting back to programming: programming language is pretty much the same, only the grammar is simpler. Also, when talking about programming languages words are called tokens, and the types of tokens are named differently (although, you could name them adjectives and nouns if you wished).
Much like for spoken language, programming language grammar, aside from naming types of tokens and what they look like, tells us what we can do with them. For example, for this expression: int x;, it tells us that:
- int is a type,
- when the expression starts with type, it's also a declaration,
- x is an identifier,
- type must always come before identifier,
- ; marks end of expression,
If you compare the high mountain with int x; side by side, they are not that different in how they are described.
With more words comes the complexity, so in order to group them together, we form sentences, and it's no different in programming - it is called an expression or a statement. As in natural languages, an expression can be simple or complex consisting of 1 or more other expressions or statements, but we will get to that.
To summarize:
-
wordis called atokenin programming language, -
sentenceis called anexpressionor astatement, - other elements differ from language to language.
That's all well and good, but in order for CPU to actually do something, we have to parse programming language and transform it into machine code. So, the next natural questions is:
What is parsing?
Simply put: it's translating text into a data structure, based on some specification.
That's it. In case of programming languages, the specification is called grammar, which we explained in previous section. If you are interested in more detailed explanation, you can check this article.
Parser itself is made out of 2 components: tokenizer (also called lexer) and AST generator (actually it's called parser in other sources, don't ask me why parser contains parser, we probably run out of names).
Tokenizer
Tokenizer is responsible for taking in file containing some text, and dividing it into tokens (words).
Token is much simpler than a spoken word. Unlike in the spoken language, there can be no confusion about the meaning of a token. Let's look at a bit more complicated example, a code like this:
int x = a + b;
Can be divided into following tokens:
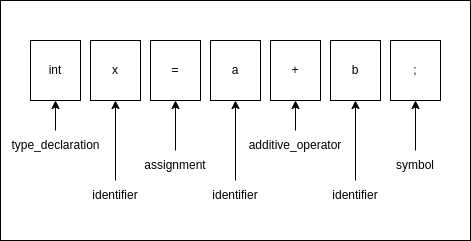
You can never mistake type_declaration with an identifier, otherwise the program will not work. Aside from that constraint, you are free to name them whatever you like, there is no one standard, and each parser has it own naming conventions, unless you are planning to use something like LLVM. If you are interested, you can see examples of naming in different language parsers in the AST Explorer.
Actually, there is one more token type that's not presented on the diagram: white_spaces. Unless it's Python or YAML, we will simply ignore the whitespace characters, their only purpose is to divide other tokens that would otherwise be indistinguishable, like int value from intvalue.
So, a tokenizer goes through a file, and reads all the tokens one by one, returning them to parser. How does it know which token it read? By using regex. Each token definition has regex expression associated with it, and we check if the beginning of our string matches one of the token types, otherwise we return null or throw an error. You could write it simply checking each and every character in order to avoid nested looping, but for this article we are not be doing that.
Notice that we didn't yet touched on the grammar defining the order of tokens, that's the AST generator's task.
AST generator - actual parser
But wait, what is an AST? It's an acronym for Abstract Syntax Tree, and it's a intermediate representation of our code in a form of... well... a tree (finally those data structure courses can be of some use).
Why do we even need that? For type and grammar checking, optimizations, and it's easier to traverse than an array of tokens.
In our example, the code:
int x = a + b;
Will be represented as:
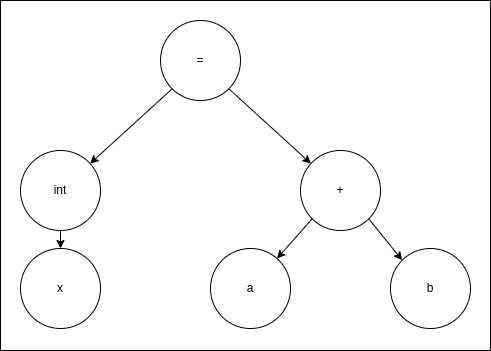
You may notice the missing ; - that's because it's only a delimiter - it marks the end of a single expression and is not relevant for further processing. Also, in this diagram I don't show the metadata for each node, such as type of the token, but it's there.
Going from the top, the expression can be easily interpreted as an assignment expression, where we declare a new variable called x of type int, and assign to it the result of adding value from variable a to value from variable b.
Let's see more complicated example with a function declaration:
int square(int y) {
return y*y;
}
The AST for that piece of code would look something like this:
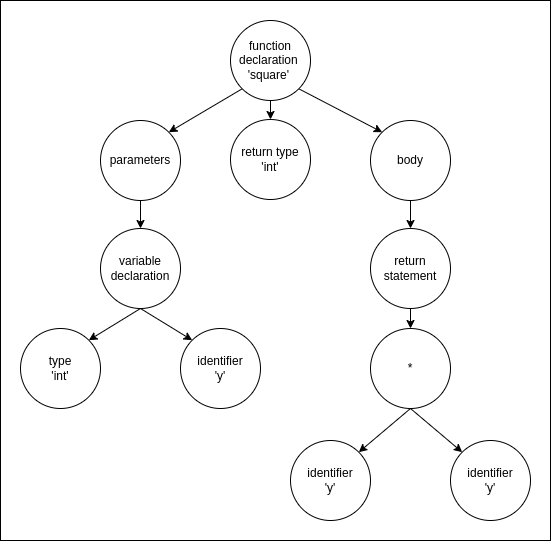
Well, that became quite big really quick, didn't it? If we added a class on top of that, the diagram would be twice as big, so from now on, we will switch to JSON representation of a tree, and only for parts that we actually need.
Thing to note in this example is that a function has 3 children nodes:
-
return type, -
parameters, -
body.
A body node is just a list of expressions in order of appearance, ending with optional return statement.
Given that information, you can probably guess what a class declaration would look like, it would have:
-
identifieras a name, -
access modifier-public,privateorprotected, -
bodywhich would a list ofexpressions.
You can see where this is going. Each structure and expression in a programming language is well defined and has a set of parameters that it consists of. It also has a defined order in which they can appear, for example: a class name identifier must appear after a class keyword.
And that is called programming language grammar.
Grammar
Grammar can be defined using a Backus-Naur Form, which is a meta language that for me became readable only after I actually implemented parser, but nevertheless, let's go through a brief introduction now.
Let's use our original piece of code as an example, which was variable declaration: int x;
This is called a declaration expression, and as name suggests, it's used to declare a variable.
The grammar for this type of expression, can be described as:
"A type identifier, which is a keyword, followed by a name".
In Backus-Naur Form (BNF) it can be written as:
<declaration-expression> ::= <type-identifier> <identifier>
Let's look at another example:
int x = square(x)
In BNF, this type of expression, can be defined as:
<assignment-expression> ::= <declaration-expression> '=' <expression> | <identifier> '=' <expression>
Meaning: "An assignment expression is a declaration followed by a '=', followed by an expression, or, an identifier, followed by '=', followed by an expression".
This can go on and on, and as the expressions become more complex, so does the BNF notation, however, when written right, the BNF can reflect the code quite well, which we will see in the next article.
Summary
Finally, the theory part is over, at least for the parsing that is 😉
In the next article, we will dive into the tokenizer and parser code.
Also note, that what I wrote about is applicable to any resource, not just programming language. You can use this knowledge to parse JSON, XML, HTML, CSV and whatever else you need, it only comes down to defined grammar.
See you in the next one!
Posted on March 18, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related




