The Ruby Unbundled Series: Services vs. Objects - The Battle for Decomposition and Reuse

DevGraph
Posted on May 17, 2021

Before finding a home with Ruby, I was a longtime Java developer almost from the very beginning of the language. So it certainly caught my attention when I read the opening line of this article by Ilya Suzdalnitski: “C++ and Java probably are some of the worst mistakes of computer science.” Part clickbait, part theme of picking on any language to entertain readers (none are perfect), and part truth.
Despite these mixed signals, the article’s primary thesis did resonate with me to a degree. After many years in software development, I reached a conclusion that services are a better overall mechanism for backend decomposition and reuse than objects/classes. Put aside the fact that common object-oriented languages encourage loose encapsulation and side effects, just reasoning about a system’s design and organizing business logic is easier with services from my experience.
Ok, let the battle begin.
Service is an overused term, what do we really mean here?
Don’t think about ‘microservices’ here. We could be talking about how we organize our logic within the majestic monolith. Focus on the core concept of a service, a construct essentially analogous to a function. Given a set of inputs, it does one thing consistently and returns the result. Services in an ecommerce application might include “Add item to cart” or “Checkout”. You can reliably call a service to perform the given functionality it describes.
Not exactly earth-shattering stuff, right? Stay with me for a moment to see how this trip back in time is relevant.
Consider now a vanilla Ruby implementation using a PORO (Plain Old Ruby Object). Wait, haven’t we already conflated the two concepts? A service implemented as an object? Well, everything in Ruby is an object, so we don’t have much of a choice except to start there.
The difference is that through convention, frameworks, or some other mechanism of choice, we decide to implement services as POROs that perform a single (often business-related) action. Our services do not inherently maintain state like an object and their behavior is consistent.
Taking the object point of view
Contrast this with a class or object which inherently maintains state. Method invocation responses are typically dependent on the object’s internal state. From a computer science point of view, subsequent invocations are nondeterministic because I can invoke them multiple times with the same parameters but get different results. Simply put, they are unpredictable.
Consider the use of a calculator class as shown below.
calc = Calculator.new
puts calc.total # total will be 0 (zero)
calc.add(15)
puts calc.total # total will be 15
# different than the first invocation
But wait, that is what the total should be at that point! Our program is correct, non-determinism wins! You would be correct in this context.
The challenge arises in large codebases where a change in one place results in unexpected changes elsewhere. Although harmless here, the add method has the side-effect of changing future results of the total method. In this case, it makes perfect sense. In more complex systems, it's not always so straightforward.
Let’s consider a payment system where we pass our calculator object across methods to maintain a running total of charges. This approach seems to make sense, certainly some engineer on the team will try it. Our calculator is passed to a late fee operation that adds the charges, however it sets the decimal precision to zero because the business decided that all fees are even dollar amount. Now, if we pass the same calculator object into the tax calculation class, the precision has been modified. What we want and need here is two digits of precision (standard dollars and cents).
We have created a side-effect. A side-effect occurs when we call a method to do one thing but it impacts something else. If our tax logic doesn’t always (re)set the decimal precision, we have introduced a bug. What seemed reasonable in isolation was not good in the larger use case when the object was reused across business operations.
Side effects are made possible due to the fact that most object-oriented languages (including Ruby) pass objects by reference. Thus, our calculator object can be modified (through method invocations or publicly accessible setters) when sent as a parameter to another piece of code.
Objects were originally intended to communicate via loosely coupled messages rather than direct state manipulation through constructs like public setters (think attr_accessor). Encapsulation is often poorly understood or implemented. Popular OO languages certainly don’t enforce it. In fact, the opposite is true with Java beans and Ruby attr_accessors.
Organizing Business Logic So Developers Can Actually Find It
We also have the challenge of deciding where business logic resides in a Rails application. As opinionated as Rails is about web development, it doesn’t really specify where the core logic goes. Our monolith can easily turn into spaghetti code as a result.
Extending our payment system example, consider that we want to add a rewards feature. Customers can earn rewards for purchase amounts as well as early payments. Our object model has Account, Order, and Invoice classes, but where do we put logic for rewards and concerns like late fees?
This is where services really shine. They can cleanly sit on top of our object model and implement these concerns. We still use ActiveRecord and its Object-Relational Mapping (ORM) capabilities. We just limit logic in the model classes to anything that we know applies to all use cases, typically validations and other limited derivations or calculations.
A common option for organizing services is to create an app/services directory. Too often, we arbitrarily feel constrained by the directory structure that we get from “rails new”. Just pick a standard for your team and stick with it.
Don’t throw out objects just yet
If this all seems somewhat academic still, or I haven’t yet convinced you yet, hang in there a bit longer. Objects are still extremely valuable, and there is still something magical about the fact that everything in Ruby is an object. Any string object in Ruby has a plethora of amazing helper functions built-in. No more silly StringHelper classes that you see in other languages.
Beyond this though, there is a true place for stateful objects: user interfaces. In a user interface, I most certainly want the non-deterministic behavior because I want to react to whatever the user just clicked on or typed in. I want the state at that point in time of the text box or widget. Users are certainly non-deterministic, and thus the OOP model fits perfectly.
Let’s consider the backend though. In Rails, this begins with the controller action, the loose equivalent of an HTTP-centric service. As we noted, Rails does not give any guidance or structure as to how to implement the “business logic”. You’ll find a thousand posts warning you not to dump too much logic in your controller action.
Personally, I think the general guidance of keeping most methods restricted to a decent length (a visible page or so) is sufficient, but the more important bit is how you structure the really important stuff, your application logic. This is where our service objects come into play.
Enough theory, let’s put this into practice
Now that we have covered the theoretical foundation, let’s see this idea in action. We have been calling them services, but the approach is also analogous to the Command Pattern and includes core concepts of Railway Oriented Programming.
You can implement the service pattern as a PORO, but it helps to use one of the gems available to aid in code structure, orchestration, and error handling. The LightService gem provides a nice implementation without adding hardly any overhead. It’s design is very simple, as shown in the diagram below. An organizer is used to define the sequential workflow, which is made up of one or more actions. An error in any of the actions will short-circuit the entire workflow.

To use LightService, simply add an entry to your Gemfile.
gem 'light-service'
I recommend you also configure logging which is turned down by default. Add the following line to your application.rb file.
LightService::Configuration.logger = Logger.new(STDOUT)
Consider the following organizer code from my sample news application. It has no comments, but it's pretty clear from the code what is happening.

If the moderation fails or determines that the content cannot be allowed, the subsequent steps will be short circuited as shown in the logging.

The context serves as a bag of attributes that is passed between actions. Each action specifies what attributes it expects as inputs, and what it promises to populate as outputs (if any). The context also includes success indicators and error messages. The code below is used to implement the AnalyzeSentimentAction using the TextMood gem to perform the actual analysis.
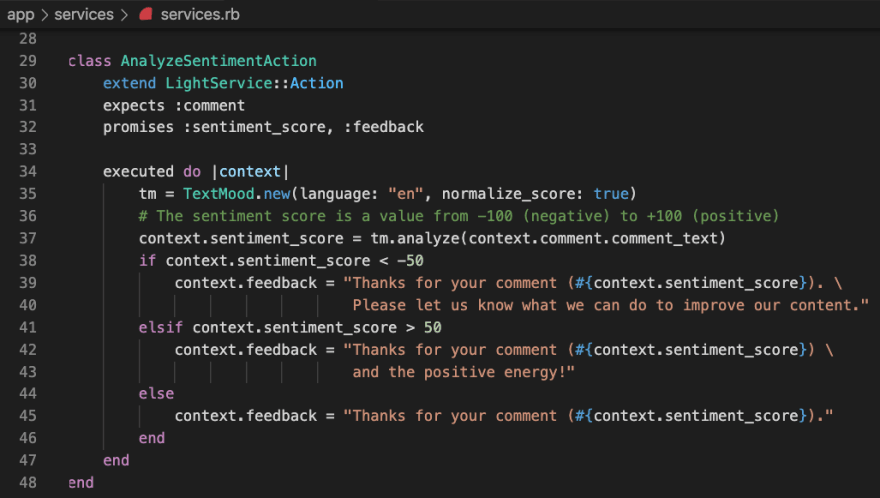
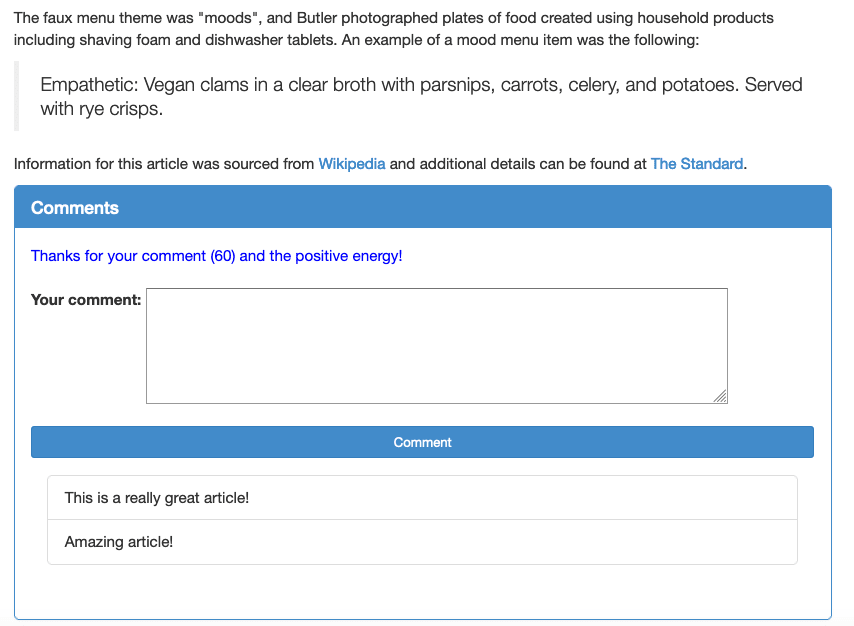
I put some positive comments on my news article, and this was the response.
As you add capability or design new systems, consider services as a mechanism to decompose your system and reuse code. I think you will be pleasantly surprised at the results.
Follow me on Twitter at @DarrenBroemmer so you don’t miss out on any of the Ruby Unbundled series.
Posted on May 17, 2021
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.