Edge Computing : Aperçu de la fonction clustering dans MicroStack et MicroK8s …

Karim
Posted on November 17, 2019
Edge Computing : Aperçu de la fonction clustering dans MicroStack et MicroK8s …

Canonical a annoncé très récemment avoir amélioré la fiabilité de ses distributions Kubernetes pour les environnements Edge, IoT et multi-cloud :
- Canonical enhances Kubernetes reliability for edge, IoT and multi-cloud | Ubuntu
- Canonical introduces high-availability clustering for MicroK8s - ITOps Times
Cela concerne donc la possibilité de créer un cluster haute disponibilité avec MicroK8s :
et l’intégration de base de données SQL pour sa distribution Charmed Kubernetes :
Canonical Enhances Kubernetes Reliability At The Edge | StorageReview.com - Storage Reviews

De même Canonical offre en Tech Preview la possibilité de créer un cluster multi-noeuds OpenStack à l’aide de MicroStack (principalement dans un contexte d’Edge Computing):

Illustration à l’aide d’un Scale Set dans Azure avec des instances de type Ev3 qui offrent la possibilité de profiter de la virtualisation imbriquée :


J’initie la création d’un cluster à l’aide de MicroStack dans la première instance qui servira de noeud Controller :


et dans la deuxième instance, je lance la fonction Compute qui permettra à ce noeud de rejoindre ce cluster :

Je réalise la même chose pour la dernière instance :

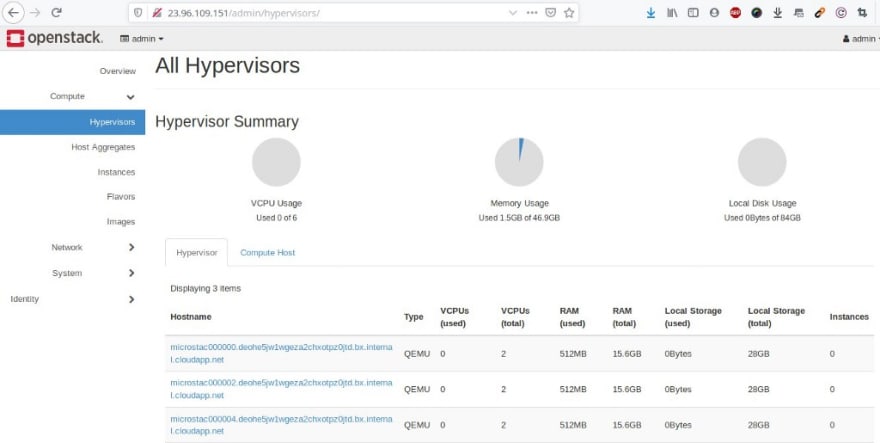
Le mini cluster OpenStack est opérationnel avec les briques de base (Nova, Horizon, Keystone, Glance, Neutron etc …):


Les clients en ligne de commande pour OpenStack sont présents :
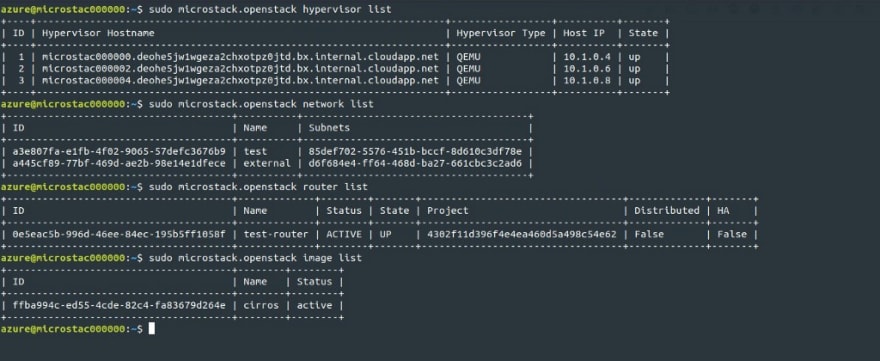
Je peux charger une image Ubuntu 19.10 dans Glance qui va me servir à la constitution d’un cluster avec MicroK8s :

Création de trois instances Ubuntu 19.10 dans MicroStack :



Les trois instances sont actives :
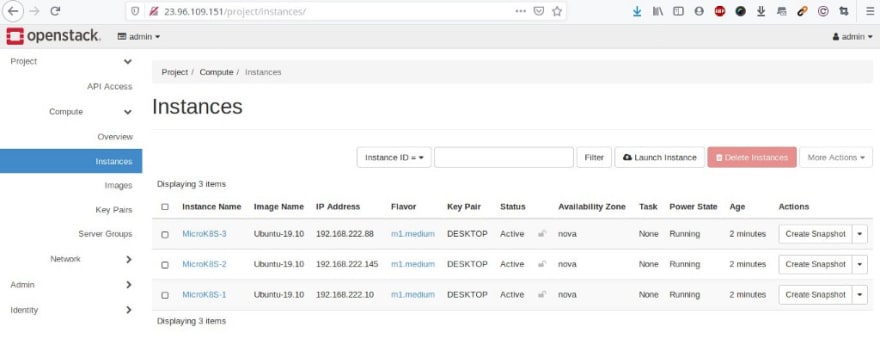
et réparties sur chacun des noeuds du cluster MicroStack :

Avec Cloud-init j’ai chargé un client ZeroTier pour relier ces trois instances Ubuntu 19.10 :


Je vais charger MicroK8s via Snap dans la première instance qui fera office de noeud maître :

Snap étant préinstallé dans l’instance :
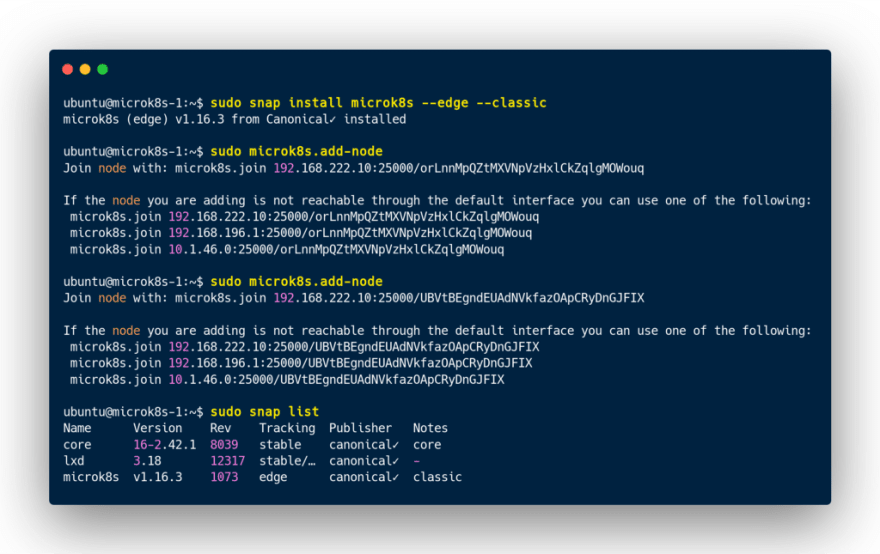
J’ai généré deux tokens pour raccorder les deux autres instances dans ce nouveau cluster …
Je peux donc raccorder ma deuxième instance via le premier token :

Idem pour la dernière instance :

Je peux alors vérifier que mon cluster est actif avec les add-ons disponibles :


Comme indiqué dans cet article, je peux installer MetalLB pour la partie Load Balancing au sein de ce cluster :
Onboarding edge applications on the dev environment | Ubuntu

avec ce segment L2 par le biais de ZeroTier :

Je lance le sempiternel démonstrateur FC en illustration :



Test de l’exposition en Node Port :

avec le port ouvert TCP 30092 assigné à chacun des noeuds :


Je peux également exposer mon déploiement en utilisant MetalLB :


J’utilise Cloudflare Argo pour exposer publiquement le démonstrateur (puisque je me trouvais dans un réseau privé ZeroTier) :


Je lance mon tunnel depuis le noeud maître avec Argo :

Le démonstrateur est alors disponible publiquement :

Il est également possible de charger des add-ons supplémentaires dans ce cluster MicroK8s multi-noeuds :
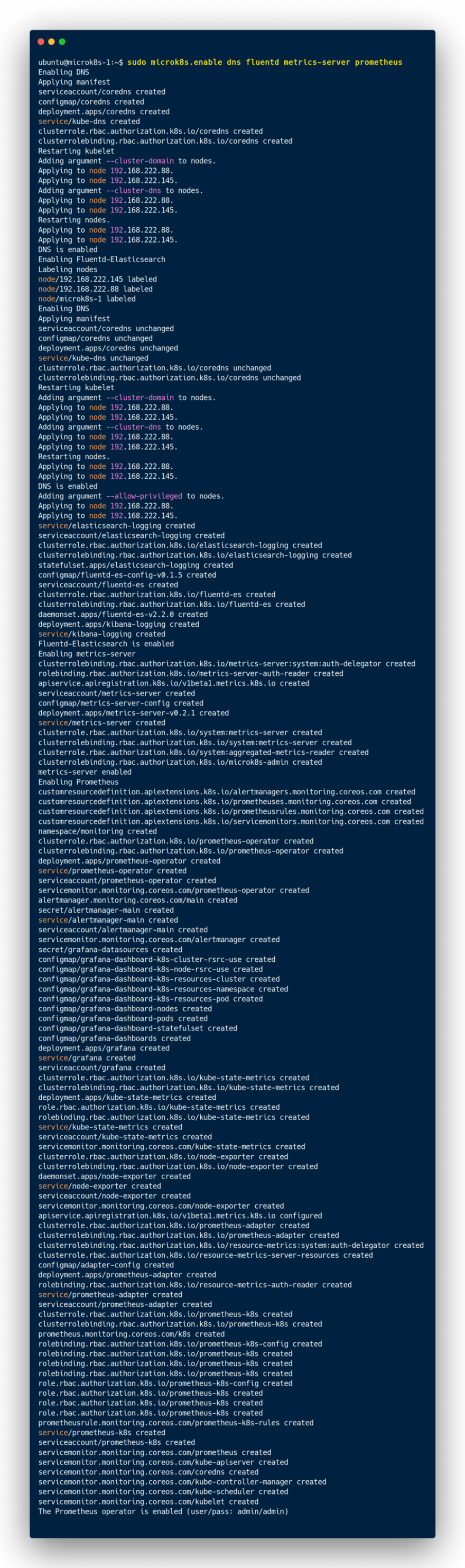
ou d’utiliser Fluxctl pour initer du GitOps :
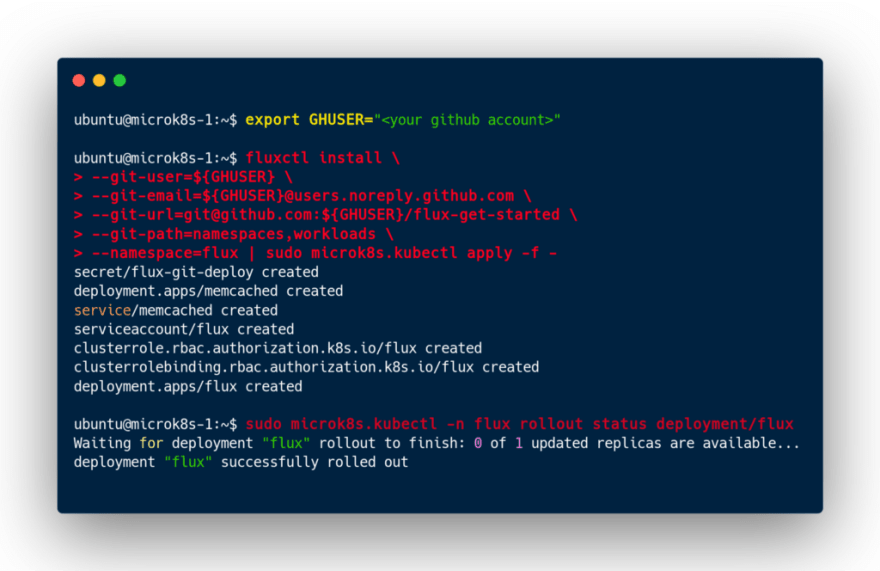
Pour finir test rapide avec ces trois instances (et après suppression de MicroK8s avec Snap), de cette version expérimental de MicroK8s qui utilise Dqlite :
Dqlite (“distributed SQLite”) étend SQLite à un cluster de machines, avec basculement automatique et haute disponibilité pour maintenir une application en fonctionnement. Il utilise C-Raft, une implémentation optimisée de Raft en C, pour obtenir un consensus transactionnel de haute performance et une tolérance aux pannes tout en préservant l’efficacité exceptionnelle de SQlite et son encombrement réduit. Canonical a annoncé que la prochaine étape consisterait à assurer la haute disponibilité des clusters K8S en utilisant le moteur SQL distribué Dqlite. Dqlite supprimerait en effet la surcharge des processus en intégrant la base de données à l’intérieur même de Kubernetes et réduirait l’empreinte mémoire du cluster (un argument important dans un contexte IoT).
Récupération via Snap de cette version de MicroK8s :


Je regénère deux nouveaux tokens pour former mon cluster :

et je forme ce cluster avec les deux autres instances :


qui devient disponbile :

Test rapide du démonstrateur FC :


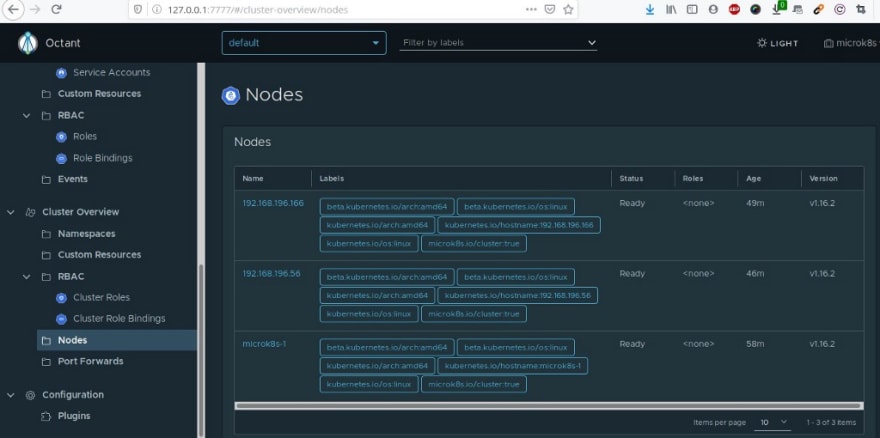
et j’utilise le client Octant pour faire office de tableau de bord pour ce nouveau cluster :

avec une interface web open source centrée développeur qui permet d’inspecter ce cluster Kubernetes avec ses applications :


Il ne restera plus qu’à tester via Dqlite, un cluster MicroK8s en mode HA avec plusieurs noeuds maîtres … L’utilisation de Dqlite avec RAFT comme datastore Kubernetes simplifiera le déploiement d’un cluster K8s résilient. Ceci afin d’atteindre une grande fiabilité à très faible coût sur les appareils de base x86 ou ARM tels que les clusters de cartes Intel NUC ou Raspberry Pi dans un contexte d’Edge Computing.
Deploying Kubernetes at the edge - Part I: building blocks | Ubuntu
De même Canonical a indiqué que l‘on sera en mesure d’utiliser des bases de données SQL familières pour les données du cluster Kubernetes en lieu et place d’Etcd notamment au niveau de sa distribution Charmed Kubernetes …

A suivre !
Posted on November 17, 2019
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related
November 17, 2019