How to build a web scraper in Ruby — a COVID-19 live data example.

Adebola
Posted on March 31, 2020

Web scrapers are relatively easy to build — the scariest thing about them is the fancy science-fiction-like code-name they have. In this article, I’m going to show you, step-by-step, how I built a web scraper to scrape COVID-19 live data from the WorldOMeters website.
A use case for web scrapers would be building an aggregator platform, where you’re going to different websites(news websites) for example, grabbing information from there and providing that information all in one place. Another use case would be using it within an API — like in Rails, to supply aggregated information to front-end apps. Basically, use it when you need to extract data you cannot generate on your own. Always make sure to read the T & C’s on scraping on whichever website you decide to use!
Let’s get into this web scraping business!
First, create a new directory/folder and cd into it.
mkdir corona-scraper && cd corona-scraperNext, we need to create a Gemfile to help us install some of the gems we’d be using. We’ll be using bundler to do this. Simply run
bundle init-
Add the following gems to your Gemfile.
Create a scraper.rb file using
touch scraper.rbInside the scraper.rb file, we will write our scraper function. First, we need to require the gems that we’ve installed. The byebug gem allows us to put the word “byebug” anywhere in a block of code so that we can interact with it in the command line. The httparty gem is used to access external websites. The nokogiri gem is used to parse and interact with HTML content.
require 'httparty'
require 'nokogiri'
require 'byebug'
require 'json'
6.Now, let’s write an all_countrie*s function that will go to the **worldOmeters website*, scan the HTML on the page and return to us the HTML content within that page. We will then use Nokogiri to format this content so that we can play around with it. Let’s also add byebug to get some practice on using it.
def all_countries
unparsed_page = HTTParty.get('https://www.worldometers.info/coronavirus/')
parsed_page = Nokogiri::HTML(unparsed_page) byebug
end
Now if you run ruby scraper.rb in your terminal, you should see that the code stops executing. We can now access the parsed_page variable by simply typing parsed_page within byebug.

After typing parsed_page and hitting enter, you should get something like below.
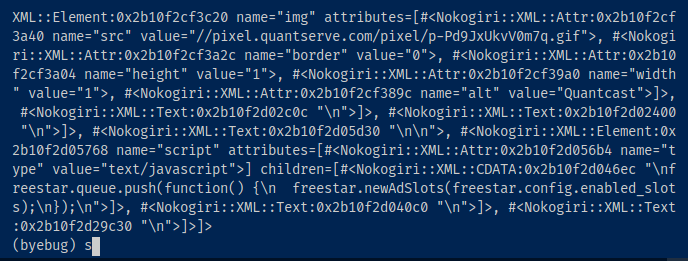
Using this technique, you can stop at any point within a block of code to interact with the data within the terminal.
type exit and hit return to exit byebug.
7.Let’s expand our function. If you head to the website we’re trying to query, you would notice that the data is laid out using a HTML table. You’d also notice that the table has an id of #main_table_countries(by using inspect element to view the HTML on the page). You’d also notice that the data we want — country name and the live stats — is located inside a
After completing this preliminary investigation, we can now write a block of code that directly targets the specific element we want and returns all the data inside it. First, let’s see how many country records are inside the row.
NB: Take special care with indenting your code inside a ruby block. If not properly indented, Ruby will read code that continues on a new line as separate from the previous block.
total_countries = parsed_page.css
('table#main_table_countries_today >
tbody > tr').map(&:text).count
As you can see, we are accessing the parsed_page variable declared initially, then we’re getting the table that has an id of main_table_countries_today. We then access the
within this table and itsSimply add this block of code and move your “byebug” to just before the end keyword within our all_countries function.
Now, if you run ruby scraper.rb again, we should have access to the total_countries variable.

We have 202 records.
8.Next, let’s write a loop to loop through all 200+ records, extract the text within the records and format the data into a ruby hash(ruby hashes are a great way to store key:value pairs).
First, we create a records array to hold our records, then enter the while block.
Your block of code that creates the array and runs the loop should look like below. We’re using i as an index to extract each record.
We then split each record — this converts each
We then format the information we are receiving and assign it to our own keys.
You can use the terminal to see what record returns before we split it and after we split it.

We then increment the counter by 1 each time, till we get to the end of the loop.
Your entire file should now look like below
At the end, we return the records array. We can use all the array methods on this array. For example to access the first country we can use records.first
Then we can access the name of this first_country hash by calling records.first[:name].

You can use the same idea to access the other keys within our hash.
And that’s it, we’re done.
As an added bonus, let’s write a function to find data of a specific country from our records. It would depend on the result returned by the all_countries method. We call a down_country variable to downcase whatever country the user is searching for — so that we can properly match it. we then downcase each country name that is returned by our all_countries method so we can have an exact match to our country_to_find argument.
and that’s all folks!
You’ve built yourself a nice lil’ scraper.
Posted on March 31, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related



November 30, 2024
