
David MM👨🏻💻
Posted on July 4, 2020

Many people use Anaconda to write Python code. But it is so cumbersome for small scripts and hard to manage.
Instead, we can create our own virtual environments (like our own world) where we only have the packages we want to install.
In about 6 minutes we will be creating a Python virtual environment with Pipenv.

Table of contents
1- Creating a virtual environment
2- Installing packages on our Virtual Environment
3- Creating a Scrapy spider on our new Virtual Environment
What we will learn here
In this video you will learn how to:
- What Virtual Environments are
- Why we use them
- How to create our own Virtual Environment
- To install packages on our Virtual Environment
- How to create a small project from our Virtual Environment
1- Creating a virtual environment

What's a Virtual Environment?
Many people use Anaconda, a Free Python distribution. While this helps when dealing with complex things by installing a series of packages (such as Machine Learning, Data Science, etc), sometimes is a bit cumbersome, especially when we want to control our environment by installing/removing packages, updating, etc.
What can we do instead of using Anaconda?
We can create a Virtual Environment and install the packages we need, manually.
But first... What's a Virtual Environment?
Real Python has a good definition here:
At its core, the main purpose of Python virtual environments is to create an isolated environment for Python projects. This means that each project can have its own dependencies, regardless of what dependencies every other project has.
Imagine that you created a Django project in 2019, using Django 2.2. Now, on mid-2020. you want to update to Django 3. After doing it, your older Django project doesn't work because it was for Django 2.2!
By using a Virtual Environment, each project has its own local packages list, with its own version.
We can have an older project using Django 2.2, and a newer one using Django 3. Each time we work on one or other project, we just load their own Virtual Environment. This way we use their local packages.
As everything, the best way to understand it is by practicing, so let's do it!
Creating our Virtual Environment
If you have installed Python (and you should, because you're reading this post!), you have already the virtualenv package installed. But on this tutorial, we are going to use pipenv.
We need to install pipenv on our computer, to have access anywere:
pip install pipenv
After that, move to the folder where you want to create your project, and create a Virtual Environment with 'pipenv shell':

After a few seconds, this will create a Python virtual environment:

You can use the commandos 'pip list' and 'pip freeze' to list the packages you have installed on the current Virtual Environment: 'Pip list' will list every package installed (even the ones installed by default such as setuptools, pip and wheel) while 'pip freeze' ONLY the ones you installed manually:
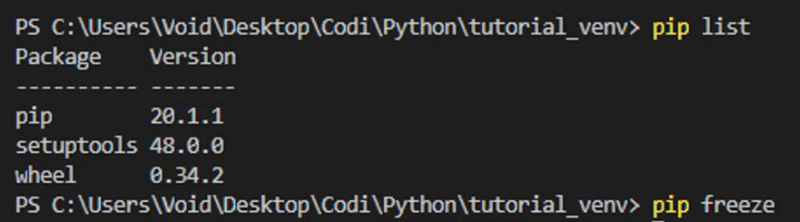
As you can see, we have no packages installed. Let's install them!
2- Installing packages on our Virtual Environment
On this tutorial, we will create a basic Scrapy project.
You don't need to know how to use Scrapy, as this is just an example, but Scrapy is a framework that lets you extract data from websites. I have a few blogpost tutorials on Scrapy if you want to learn it, but as I said, you don't need to know it.
Anyway, we need to install Scrapy. If we go to their website we can see that installing it is quite easy:
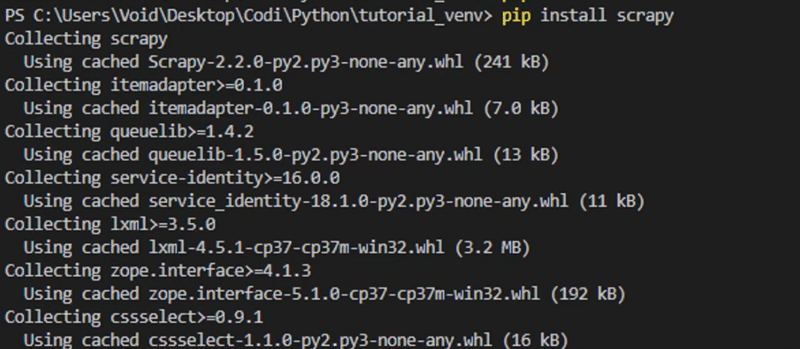
After a little bit, you'll have everything you need installed. Let's see if everything is correct:
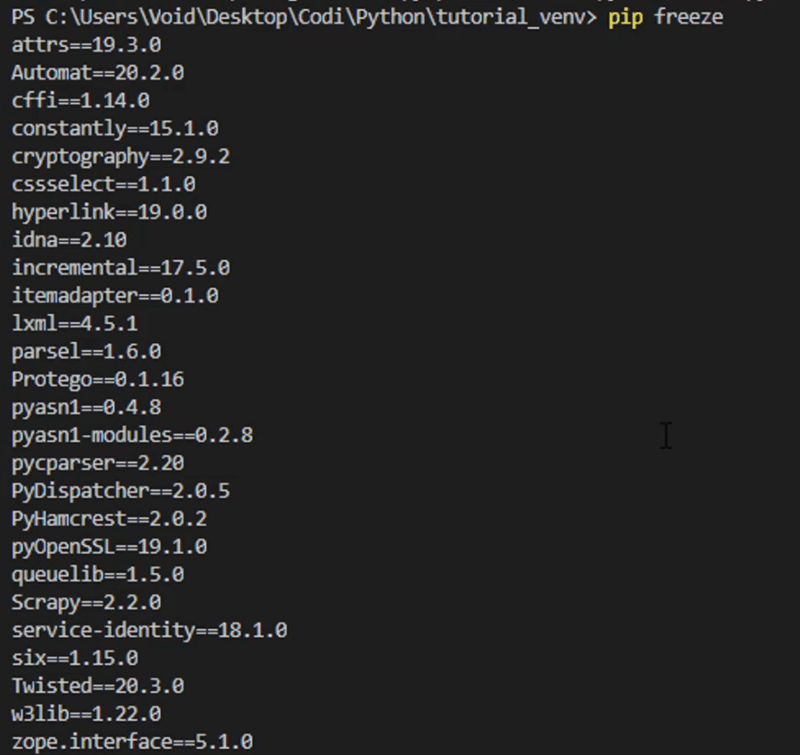
Scrapy, along a bunch of helper packages, has installed.
Let's write a basic Scrapy spider to see if everything is in order.
3- Creating a Scrapy spider on our new Virtual Environment
Let's create a Scrapy spider by following the docs tutorial:
On the folder you are, run:
scrapy startproject tutorial

Under tutorial/spiders folder, create a spider file (for example, quotes_spider.py) and copy the following:
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
def start\_requests(self):
urls = \[
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
\]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
page = response.url.split("/")\[-2\]
filename = 'quotes-%s.html' % page
with open(filename, 'wb') as f:
f.write(response.body)
self.log('Saved file %s' % filename)
Save the file, and run the code. Remember to move inside the project's folder:

If everything is working correctly, you'll have 2 .HTML files on the root folder, proof that everything has worked without a problem:
Final Thoughts
As you saw, creating a Virtual Environment, is not only easy, but useful.
This way we each project with its own packages, and we can use the newest version on future projects without compromising the older ones.
You just need to create a Virtual Environment, install the packages and you are set!
Remember that if you want to learn easily how to use Scrapy to extract data from different websites, you can learn with my Scrapy tutorials: Creating your first spider with Scrapy.
Contact me: DavidMM1707@gmail.com
Posted on July 4, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related




November 13, 2024