Why a Serverless Data API Might Be Your Next Database

Pieter Humphrey
Posted on June 11, 2021

````App development stacks have been improving so rapidly and effectively that today there are a number of easy, straightforward paths to push code to production, on the cloud platform of your choice. But what use are applications without the data that users interact with? Persistent data is such an indispensable piece of the IT puzzle that it’s perhaps the reason the other pieces even exist.
Enter cloud and internet scale requirements, essentially mandating that back-end services must be independently scalable / modular subsystems to succeed. Traditionally, this requirement has been difficult in the extreme for stateful systems. No doubt, database as-a-service (DBaaS) has made provisioning, operations, and security easier. But as anyone who has tried to run databases on Kubernetes will tell you: auto scaling databases, especially ones that are easy for developers to use, remain out of reach for mere mortals.
Serverless data offers enticing benefits, but market offerings are limited. What serverless data can, should, or could do for us isn’t always well understood. And yet, database simplicity for application developers today is increasingly taking a new form: autoscaling database services that are delivered as fluent, industry standard APIs -- APIs that are secure, well documented, easy to use, and always on. While it’s true that schemaless document databases and web APIs like REST and GraphQL are not new concepts, data API gateways have emerged as a helpful pattern when providing autoscaling services for these APIs at global scale.
Okay, so there is a lot of unpack there. Let’s take it easy and greet these concepts one at a time, giving these new guests the time and space they deserve. Besides, it’s been a while since they all got together.
Party in the front - FaaS
Functions as a service (FaaS), are excellent for data access and business logic alike. But like any middleware, functions are in constant conversation with their friends around them. Speaking of friends, let’s be inclusive and recap for a moment on FaaS:
- Runs backend code without managing any infrastructure whatsoever.
- Typically short lived, and must start up FaaSt (in milliseconds), and then timeout.
- FaaS offerings do not require coding to a specific framework or library.
- Usually triggered by events that are defined by the FaaS provider.
This sounds great, but where does the application state go? FaaS has significant limitations on holding state of any kind. Sure, you can run an in-process cache, session store, or use the modest filesystem allocated to the function, but they will be as short-lived as the function: inherently ephemeral / volatile.
Business in the back - BaaS/mBaaS
Backend as a Service (BaaS) / Mobile Backend as a Service was a popular concept at first: being able to independently scale the backend from frontend has clear value. So why don’t we hear as much about it as we used to? Well, once the initial cloud service euphoria passed, it’s probably for the same reason that Model-View-Controller (MVC) frameworks evolved in monolithic applications. Coupling frontend clients directly to backend service APIs is fast, easy, and has a valid time and place. However, the separation of the presentation logic, business logic, and model (data access layer) is important. Otherwise, it’s easy to end up with a brittle application that’s difficult to add new features to. Cloud services today are more popular than ever, so clearly something changed to avoid the BaaS/mBaaS concerns described here. What is it?
Bringing business to the party
API gateways and service meshes are useful, but can be dangerous. When they play host to too much custom code, they can become monoliths in and of themselves. When used properly, for the core features they provide, they are an elegant way to solve tough problems, service discovery, load balancing, (m)TLS termination/origination, auth token validation, request routing, rate limiting and much more.
Data API gateways are emerging as a solution to the direct coupling of frontend logic directly to a BaaS or DBaaS with nothing in the middle. One such open source effort (with contributors like DataStax and Yelp) is called stargate.io. It provides a stateless proxy layer for data, but does so in a manner that also separates storage and query coordination. This is interesting as it simultaneously:
- Splits a monolithic database server process allowing independent scalability of compute and storage
- Introduces the possibility of exposing DBaaS data services in whatever API you wish
- Allows for horizontal scalability of coordination layer
What's intriguing about the data API gateway pattern is that requests are routed to the storage engine without the consumer knowing or caring what the underlying engine is. They agree to an API contract for say, GraphQL, and they can do all of their development with the GraphQL they know and love while operators can make changes underneath with no one the wiser.
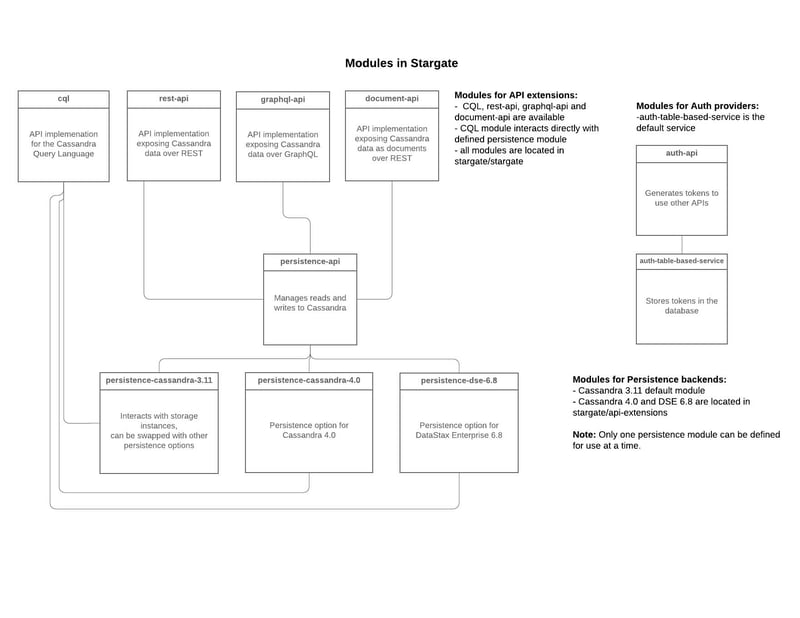
Modules in stargate.io
Providing API access via SDKs, in addition to drivers, can make data more accessible to a wider range of developers, particularly in development phases. When prototyping, it’s helpful to be able to look up a Postman collection, use cURL or httpie, or throw JSON documents at a database without up front schema definition. In production, having your database instance available via automatically created API endpoints like websocket, gRPC or GraphQL can add significant value.
As it turns out, there are other benefits to re-architecting a database engine so that the functions of a database aren’t all performed in a single process. Using specialized hardware for individual database subsystems improves performance and lowers costs since they run more efficiently. Before Stargate, Apache Cassandra nodes had peer-to-peer architecture - no specialized node types. Stargate effectively introduces compute (query coordination) node and data (persistent storage) node types.
There is no free lunch of course—breaking things into separate processes creates new issues. However, the benefits, like with FaaS, may very well outweigh the drawbacks in the long run. Besides, new techniques emerge every day to mitigate those drawbacks.
Bringing everyone together - DBaaS
DBaaS hasn’t historically been considered serverless, but that has been changing. An increasing number of public cloud services are either offering serverless alternatives, or moving to this architecture altogether. As one might expect, stateless services like compute are a bit more straightforward to make serverless, relative to stateful ones. It’s only recently that databases and data services have begun to move in this direction.
As you might expect, a serverless DBaaS scales to meet the immediate needs of the application it is servicing. When more demand is high, it scales up the number of nodes to meet the need, and when demand drops, it scales back down. This is particularly useful in microservice, FaaS and other distributed architectures. Right-sizing your database in concert with the microservice fleet in those scenarios is tedious, often resulting in paging already busy ops people. You are basically only paying by the operation instead of being charged for idle instances of “always on” virtual hardware. Read and write, storage and network out - done. This simplicity can result in tremendous idle time savings and a dramatically more cost-effective profile for everything from dev/test to production. Also, it’s a relatively understood way in which to consider the usage profile of your application for capacity planning. Why is that important? This InfoQ discussion from Phil Calçado during his experience at meetup.com articulates the dollars and sense:
“The Symphonia guys that I was talking about before helped us with this; we literally saved millions of dollars just by actually working out, ‘We actually need this data. Hey, Amazon, can we provision this beforehand as opposed to just asking for it on-demand?’"
Autoscaling removes much of the grunt work in capacity planning. Also, the ability to profile workloads by usage (read, write, storage, network) enables meaningful statistical or machine-learning driven workload analysis.
To even approach becoming a fully serverless DBaaS, the monolithic database server must be broken apart. Let’s examine a database like Apache Cassandra, which enjoys a significant advantage, as it’s partition tolerant to begin with. What are some technical challenges that potentially need to be accounted for?
- Separating database functions like coordination, reads, writes, compaction, and repair into independent processes
- Removing any dependency on locally attached storage
- How to deal with latency incurred by the above separation(s)
- Security at the disk, process, and network level boundaries for these newly separated processes
- Emitting, collecting, monitoring and storing the right telemetry for billing, by the operation
- Re-engineering to leverage K8s - native structures and subsystems (e.g etcd)
- Leveraging other K8s - native structures for workload orchestration, automated remediation and leader delegation
One can imagine a database that wasn’t already inherently partition-tolerant would have significantly bigger challenges, or simply would be unable to affect this architecture change at all. For a cloud-native database these serverless transition challenges are difficult, they are not insurmountable. Early movers like FaunaDB, and later AWS Aurora, Azure Cosmos DB and now DataStax Astra have all crossed this chasm. The benchmark below illustrates what success looks like: you can see the serverless dynamic provisioning and de-provisioning based on load (blue) versus manually scaling up and down an entire monolithic instance (orange) over time.
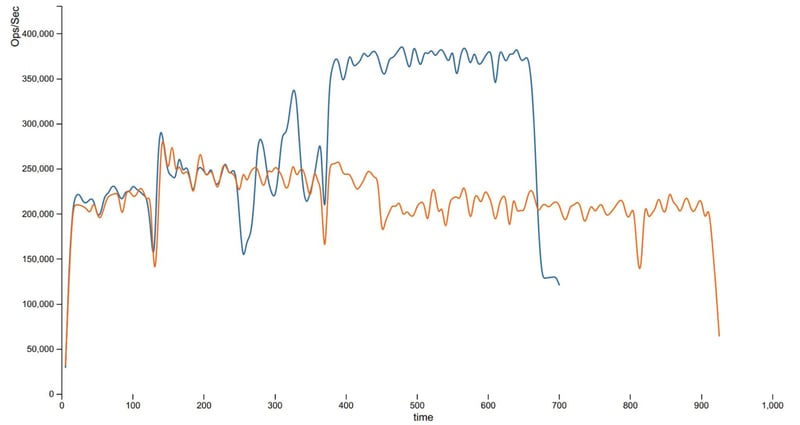
Serverless Autoscaling based on load
But what if you could combine a data API gateway, serverless database and leverage k8s native structures? Functions, microservices, and apps alike can speak to a Kubernetes data backplane with drivers or standard APIs. Developers simply use an SDK for an API they’re already quite likely to know or a driver as needed. When combined with serverless autoscaling, there are significant gains in both ease of development and operations, as well as cost savings. The ability to own your K8s data and not be locked into the cloud service provider’s proprietary data store(s) isn’t a bad side effect, either.
Let’s make the API experience a bit more concrete. While SDKs can simplify this further for language-idiomatic usage, the developer experience is as simple as described in this article:
REST
curl -L -X GET 'http://localhost:8082/v2/keyspaces/blog/vehicle?where=\{"manufacturer":\{"$eq":"Tesla"\}\}' \
-H "X-Cassandra-Token: $AUTH_TOKEN" \
-H 'Content-Type: application/json'
JSON Document
curl --location \
--request GET 'localhost:8082/v2/namespaces/blog/collections/vehicles' \
--header "X-Cassandra-Token: $AUTH_TOKEN" \
--header 'Content-Type: application/json'
GraphQL
query vehicles {
vehicle(value: { manufacturer: "Tesla" }) {
values {
manufacturer
type
color
model
vin
}
}
}
So what business problems can such a system solve? With the storage engines supported today, it plays to Apache Cassandra’s strengths of writing fast, reading fast on primary key and secondary index in “fast data” business use cases like:
- Transaction logging: user behavior, actions
- Bitcoin price tracking, Fraud Detection
- Internet of things status and event history, telematics for cars and trucks
- High velocity time series data (e.g. logging, metrics, APM, tracing data)
- Logistical tracking - order status, packages
- Health tracker data, weather service history
- Email envelopes—not the contents
You can test drive it locally with a download, but it’s much easier with Docker, and easiest as-a-service on astra.datastax.com - a serverless DBaaS API built on Apache Cassandra, K8ssandra, Stargate, Apache Pulsar, Envoy and other modern open source.
Planning the next event
So what happens as we start seeing more major components of our architecture that are event driven, end-to-end? Meaning, FaaS as the container for the business logic, in between the client and backend service, with serverless BaaS and DBaaS options? Returning to CAP theorem for a moment, we know that’s a world where partition tolerance is not negotiable. With the stateful aspects of these systems, the focus of innovation today is therefore about the role of availability and performance in:
- Transactions, data consistency
- Messaging, streaming and batch processing
- Further separation of database subsystems into independent processes
- Kubernetes-native Data API gateways
- Improving the FaaS programming model by offering a wider range of data APIs
Monoliths will always have a place, and not everything needs to be event driven. Yet, as more and more DBaaS follow suit and offer a serverless model (or option), we are likely to see an increase in event driven thinking. The economic benefits of paying strictly for usage are certainly clear.
Learn more
- Jim McCollom’s blog series on the Astra engineering journey to Serverless
- Apollo GraphQL Federation router for Stargate announcement
- Serverless. Stargate, K8ssanda Press Releases
- Astra Developer Hub, DataStax Developer website
- Cassandra Documentation on Apache and DataStax websites
- Get involved in the stargate project
Posted on June 11, 2021
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related