Evaluating large language model applications with LLM-augmented feedback

Bart
Posted on August 2, 2023
Many large language models (LLMs) today can be evaluated and selected based on benchmarks that span a wide variety of tasks. These benchmarks, for example, on the Open LLM leaderboard maintained by Hugging Face, provide performance metrics across numerous domains to select the optimal model for your use case.
[
Open LLM Leaderboard - a Hugging Face Space by HuggingFaceH4
Discover amazing ML apps made by the community


](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?ref=dataroots.ghost.io)
Unfortunately, these benchmarks often fall short when applied to specific applications or industries. They may not fully capture the intricacies or unique requirements of your application domain. How do you know if your LLM-powered application deployment will perform as intended and if your users will be happy with the performance? Today, there is no industry standard to adapt LLMs to your use case and evaluate their performance, aside from using human feedback.
Additionally, existing benchmarks typically focus on isolated aspects of performance without considering the full process from input to output. To assess the effectiveness of an LLM in a specific application, we need to evaluate the entire process: How the model, its parameters, the prompt, as well as other components such as vector similarity search for prompt augmentation, work together to create a final output (in LangChain, this would be equivalent to an LLM Chain). This comprehensive approach can better capture the real-world performance of LLMs on specific tasks.
At Dataroots, we are building an LLM-powered Q&A application with knowledge base retrieval that reduces the workload for HR-related questions. Rather than evaluating each answer by hand, we try to automate evaluation without human intervention to some extent. Therefore, in this blog post, we will explore the approach we adopted to evaluate our application at Dataroots. We will delve into the selection of the evaluation method, the available metrics, the importance of dashboarding, and the valuable insights gathered along the way.
Reference-based evaluation as automated alternative for human feedback
Since conventional benchmarking methods are not suitable, we propose two viable alternatives:
- The first option involves seeking human feedback. It remains the gold standard because, unlike automated metrics, humans possess contextual understanding, subjectivity, and domain expertise. However, this approach requires making the application accessible to users, lacks consistency and reproducibility, and may involve a significant amount of manual effort. This becomes particularly challenging when we aim to evaluate the application before deploying it into production.
- The second alternative is a reference-based evaluation method. It revolves around constructing a golden dataset that consists of carefully crafted questions derived from our own dataset, along with corresponding ground-truth answers. These questions are then processed through our application, allowing us to compare the generated answers against the expected answers from the golden dataset. This comparison serves as a means to evaluate the accuracy and correctness of our application's responses.
While human feedback is indispensable, valuable, and even required at some point, we wish to reduce the extent to which human feedback forms a bottleneck in the development process as well as the early detection of production failures.
Therefore, we explored the reference-based evaluation method. In order to create the golden dataset efficiently, we avoided relying solely on human labour and enlisted the assistance of another LLM. By leveraging its capabilities and providing it with the necessary documentation, we were able to generate question-answer pairs that contribute to the construction of the golden dataset. This automated process significantly reduced the time and effort required, especially when dealing with a large dataset.
Pros and cons of an automated golden dataset over human evaluation
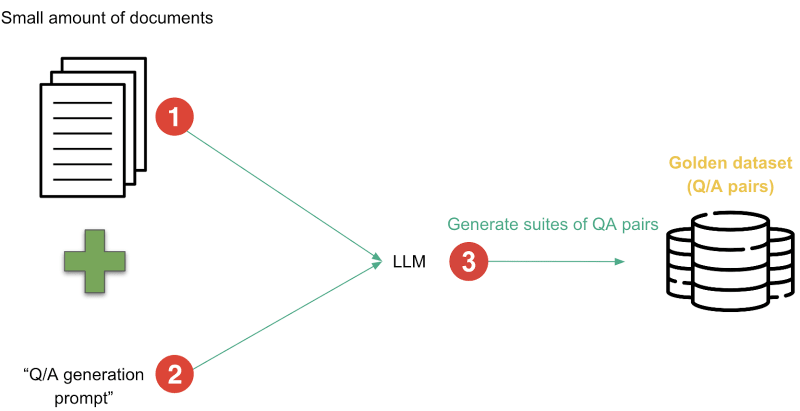
The approach is as follows:
- Due to the limited context capacity of LLMs, we can’t just provide the whole dataset as input. That’s why we provide small document chunks from our vector store, derived from our constrained dataset, for generating the question-answer pairs. You can find out more about this process in this blogpost.
- We craft a prompt that instructs the LLM to generate question-answer pairs based on the provided documents.
- Running the LLM produces the golden dataset, consisting of question-answer pairs derived from the documents.
Example:
- Provided document: “Coaches are your go-to person in case you have questions or want to talk about your career, wellbeing, personal or professional goals, challenges, etc. Your coach is responsible for supporting you with your goal setting and preparation of the yearly and bi-yearly evaluations.”
- Crafted prompt: “Based on the provided document, come up with a question-answer pair where the question can be easily answered just by reading the document.”
- Result:
Question: “What are coaches for?”
Answer: “Coaches support and guide individuals in their career, wellbeing, goals, and challenges.”
Drawbacks:
- An assumption is made that the initial dataset contains accurate information. So if a document contains incorrect information, the LLM will just consider it valid and include it in the golden dataset.
- The reliability of the pairs depends on another LLM's performance. If the golden dataset prompt is badly designed, it will generate incorrect pairs.
- The generated golden answers can vary in form, including different lengths and phrasings, which can be considered a lack of consistency and be problematic if the answers to which they will be compared are less or more verbose.
- Each pair generation necessitates an API call that is not free.
Advantages:
- Leveraging the provided documents ensures that the auxiliary LLM generates question-answer pairs that accurately reflect the dataset's content.
- The technique offers scalability, allowing for the generation of numerous pairs effortlessly.
- Time-efficient and automated, this method enables the generation of golden datasets in real-time.
- It can be easily applied to different use cases by simply switching the initial vector store.
- Requires no human intervention and is really straightforward to implement.
- Eventually, we can enhance it with examples from human feedback or even add human-generated samples.
Evaluating models before deployment with the newly created golden dataset
Evaluation process:

Once we have our golden dataset, the next step involves providing the question part to our application and collecting its corresponding answers. This stage is crucial as we aim to evaluate the application's responses against the answers provided in our golden dataset, which serve as the benchmark for accuracy.
In our pursuit of an automated evaluation process, we eliminate the need for a human evaluator. However, due to the subjective nature of assessing answer quality, there is no universally perfect evaluation metric. Therefore, it becomes essential to consider multiple metrics that encompass various aspects of evaluation while also employing innovative approaches that extend beyond conventional methods.
In our application, we have taken into account several metrics to assess the quality of answers, ensuring a comprehensive evaluation process. Here is an overview of the metrics we used for our application:
- Auto-Evaluator answer grading : Following the methods from this repo, we use another LLM with a specific prompt in order to assess the factual consistency between the LLM answer and the golden answer.
- Auto-Evaluator document retrieval grading : As in the previous method, we use another LLM with a specific prompt in order to assess if the documents retrieved by our model are relevant in order to answer the question.
- Structure score : In our application, we have incorporated a feature where each answer must include at least one valid link to the original source of information. We validate that the link is present and that it corresponds to one of the retrieved documents. This implementation enables us to evaluate whether the LLM consistently provides genuine links and avoids fabricating them. It serves as a means of ensuring the credibility and authenticity of the information provided by the LLM.
- Latency : The average latency measures the time taken by the LLM to process each query or request. It allows us to see how quickly the LLM can perform compared to the others. It can be useful in the situation where two LLMs would have a similar accuracy score, but one of them would be much slower than the other.
- Cosine similarity score : By converting both the LLM answer and the golden answer into their respective vector representations using a suitable embedding technique, we can compute the cosine similarity score between them. This score stands out as the most mathematically grounded and robust in its approach.
- Rouge/ Bleu/ Meteor score : NLP metrics commonly used to evaluate answers in comparison to their references. However, their effectiveness diminishes when the golden answers and LLM answers are expressed in significantly different ways, rendering them less relevant in such cases. Ex: If the golden answer is significantly more explicit in its wording than the generated one, we will obtain a low Rouge score despite the fact that they may be factually consistent.
- Toxicity : The toxicity measurement aims to quantify the toxicity of the answer using a pretrained hate speech classification model. Given that the answers should not contain any hateful content, this metric is particularly valuable as a safety check during production. If a high level of toxicity is detected in an answer, it can trigger a warning for the user. This metric is imported from the Hugging Face library, which offers additional metrics such as honesty or regard. However, the toxicity metric has proven to be the most practical and effective in our evaluation process.
Choosing the most suitable model for your specific requirements through dashboarding
For visualising the evaluation, we opted to utilise the versatile MLflow framework, which can be implemented with ease. By leveraging MLflow, we gain access to a comprehensive overview that allows us to select the specific use case or experiment we wish to analyse. Within the chosen use case, we can differentiate and compare runs. This allows us to compare metrics that we deem most important in the given context.

As we can see, this allows us to effortlessly navigate through multiple runs, providing the convenience of filtering and sorting by various metrics. This feature becomes particularly useful when dealing with a large number of runs, enabling efficient analysis and comparison.
When we select a specific run, we can see all the associated parameters, metrics, tags, and artifacts:

We can inspect the model used for the run, the different metrics, and the prompt, which was saved here in a .txt file. In order to make it simpler to identify when our model is underperforming, we also included a file in which we would retrieve the various scores for each question-answer pair.

We intend to implement the versioning of the vectorstores and the golden dataset as a further development. A final enhancement would be some attractive graphs that would show such performances.
Conclusion
In this blog, we evaluated our specialised LLM application's performance on a constrained dataset and a specific use case. We harnessed reference-based evaluation, leveraging automated golden dataset creation for accurate and automated assessment. We used multiple metrics to evaluate our application's responses, including Auto-Evaluator grading, cosine similarity, and more. We utilised the MLflow framework for efficient visualisation.
Although there is no perfect way to assess the performance of dataset-specific LLMs, we hope that our methodology will help in choosing the best LLM for each specific use case. Our approach offers scalability and efficiency, paving the way for improved LLM applications on constrained datasets. Despite all the advantages it offers, it is important to acknowledge that the reference-based LLM evaluation method lacks some level of guarantee, potentially requiring the evaluation of another LLM, leading to a kind of LLM-inception. It only highlights the ongoing need for human intervention and evaluation in LLM-powered processes.
You might also like
[
From Pandora’s Box to the Genie’s Lamp: Overcoming Challenges in Enterprise Adoption of Large-Language Models - Tim Leers
The race is on to harness the potential of Large Language Models (LLMs) in enterprises. Right now, there is significant risk in adopting LLMs in many usecases, without a clear path to deploying them to deliver business value. In part, that is because, the broad principles that drive value creation i…


[
LLMOps, GenerativeOps or AgentOps? Distinguishing the challenges in contemporary LLMOps - Tim Leers
The term “LLMOps” (Large Language Model Operations) is debated - while it does encapsulate the operational challenges of deploying and managing large language models, it’s the powerful, generative, and interactive nature of contemporary LLMs that present distinct challenges and opportunities. Moreov…

Posted on August 2, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related


November 29, 2024