
Daniel Macák
Posted on March 22, 2024

Running AB tests seems easy at first. After all, you just divide users into 2 groups and compare the results, right? Not quite. Designing, running and evaluating many AB tests, I realized that as many things in life, it's not that simple. Let's have a look then at how to identify some big mistakes you might be making and prevent them.
Concluding tests too early
This happens when people get excited about preliminary results before the AB test reaches statistical significance. In other words, it happens all the time. And it's not like people don't know they should be patient, but it's hard to get there (same with holding stocks and watching the prices fall... yikes).

This is especially true if you are using Frequentist approach, and Evan Miller provides great reasoning for why it's bad in his article. Basically, Frequentist approach requires reaching a predetermined sample size (typically users in both Treat and Control variant), otherwise the results can't be considered trustworthy, and the chance of picking the wrong variant increases from the standard 5% up to 27.5%. Quite a high false positive rate, isn't it?
Bayesian is much better in this regard as there is no predetermined sample size you need to wait for, though you still should respect relevant seasonality, typically weekly.
Ignoring Twyman's Law
This happens to everyone who's starting with AB tests. You run it, are careful not to fall into the trap of concluding it too early, check the results ... and they are amazing. The data shows your feature is a great success!
Unless it isn't. It turns out, most of the time, the results are not significant and there is a bug in play. Time for Twyman's Law citation:
"Any figure that looks interesting or different is usually wrong"
Most likely, either the bug is in your feature, tracking, the way you evaluate the AB test or just the experiment design. Either way, you need to double check before you present your results to the rest of the company, which is something I wish I knew earlier.

No Triggering
Imagine you have a site which both anonymous and registered users can visit, and you introduce a new feature only for the registered users there. The act of making sure you evaluate the experiment only with users who were impacted (or could have been if they weren't in control variant) is called Triggering.
Without it, you'd factor in also anonymous users which would dillute the results, decrease sensitivity and prolong the test runtime, if not make it impossible to evaluate properly.
Incomparable variants
Let's imagine you introduce a new banner saying "20% OFF" in your online shop, but, and this is important, it's meant only for new users on their first purchase.
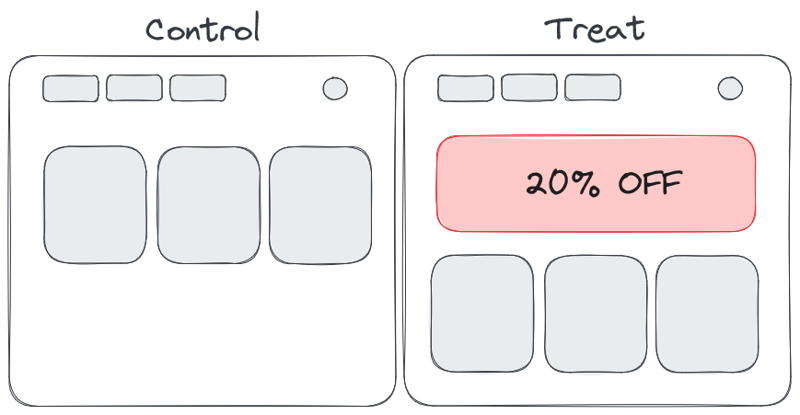
Tracking users in Treatment is easy; if the banner gets displayed, you know they entered the experiment. So far so good.
But when does the Control enter the experiment? After all, there is no banner to track. If you factor in all users, both new and existing, you'll get the No Triggering problem from above, but even worse, only for your Control group now. So you end up comparing apples to oranges, and will get invalid results.
The solution is to take the same Treatment condition, apply it in Control and track as if the new banner was displayed for Control too, but without actually displaying it. This technique is called Counterfactual tracking and is indespensable in such scenarios.
Sample ratio mismatch
SRM describes a situation when you have, let's say, 2 variants - Control and Treat - but there is a big discrepancy in user allocation between them, perhaps 60:40. Same as with AB test results, this discrepancy can be either insignificant, in which case you are fine, or significant and then you have a problem.
Having SRM means there is probably a bias in how you allocate users to the A/B/n variants and it can have a significant impact on your results to the point of invalidating the AB test completely. Finding out its root cause is key.
While writing this piece I discovered there are many more AB testing pitfalls so maybe I'll do a part 2. Let me know in the comments if you made those mistakes yourself and which one tripped you up the most.
Posted on March 22, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related