Pairing CrateDB with Jupyter Notebook

Carlota Soto
Posted on April 8, 2021

Jupyter Notebook is an open-source web application for creating documents that contain live code. It's a very nice tool for working on your data analysis projects, as it allows you to write lines of code, run them one at a time, make changes, and rerun them again. You can save segments of code, make them go back to a previous state, and share the notebooks with others.
In this post, will tell you how to pair CrateDB (an open-source, distributed SQL database) with a Jupyter Notebook.
Install Jupyter Notebook + the CrateDB SQL Alchemy driver
Jupyter can be easily installed through Anaconda, an open-source data science platform that includes many useful libraries. If you don't have Anaconda, you can install it here.
When you're done with the Anaconda installer, let's setup CrateDB in the Anaconda environment with the SQL Alchemy dialect. This will be useful if you want to use libraries like pandas in your Jupyter Notebook.
With your terminal, navigate to the bin directory inside your Anaconda files folder (it will be called something like "anaconda3"). There, run the command pip install -U "crate[sqlalchemy]".
In my case, the full command looked like this:
/anaconda3/bin/pip install -U "crate[sqlalchemy]"
Launch Jupyter Notebook
We'll launch Jupyter Notebook from the Anaconda Navigator. You can open it with this command:
anaconda-navigator
You may also see a desktop icon that you can double-click.
The Anaconda Navigator looks like this:

Now, launch "Jupyter Notebook".
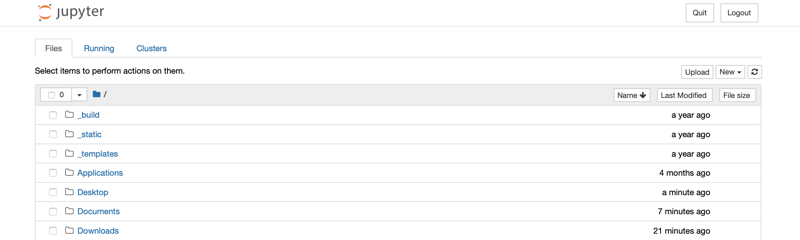
It will open in your browser, at localhost:8888:
Install and launch CrateDB
Docker makes it very easy to get started with CrateDB. If you don't have Docker, you can install it here.
If you already have Docker running, create the directory where your CrateDB data will be stored. Then, navigate there with your terminal, and run:
docker run --rm --name=cratedb --publish=4200:4200 --volume="$(pwd)/var/lib/crate:/data" crate
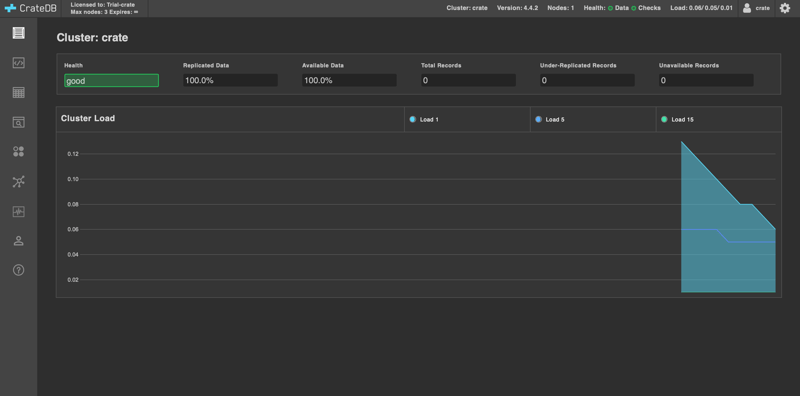
Next, open http://localhost:4200/ in your browser. You will see the CrateDB Admin UI:
Load data into CrateDB
If you have your own dataset ready, you can load it to CrateDB using COPY FROM. However, having a fresh CrateDB install, you may need some sample data.. So I will show you how to download two different sample datasets: one containing data from the NYC cabs, and another with data about the position of the ISS. We will load this last dataset straight from our Jupyter Notebook, using Phython.
- NYC taxi dataset
Open the CrateDB Admin UI. In the Console, paste the following code and click on “Execute query”. (This query creates a table where our data will live).
CREATE TABLE "nyc_taxi_sample" (
"congestion_surcharge" REAL,
"dolocationid" INTEGER,
"extra" REAL,
"fare_amount" REAL,
"improvement_surcharge" REAL,
"mta_tax" REAL,
"passenger_count" INTEGER,
"payment_type" INTEGER,
"pickup_datetime" TIMESTAMP WITH TIME ZONE,
"pulocationid" INTEGER,
"ratecodeid" INTEGER,
"store_and_fwd_flag" TEXT,
"tip_amount" REAL,
"tolls_amount" REAL,
"total_amount" REAL,
"trip_distance" REAL,
"vendorid" INTEGER)
WITH ("column_policy" = 'dynamic', "number_of_replicas" = '0', "refresh_interval" = 10000);`
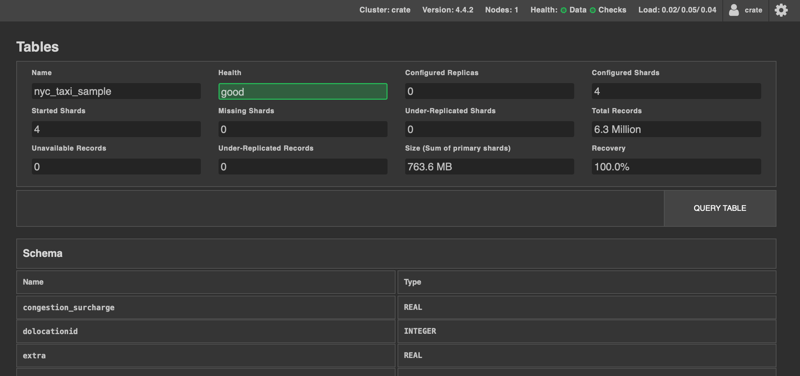
To import the dataset, execute the query below. It can take up to 10 minutes for the data to be fully loaded. This dataset contains about 6 million records.
COPY "nyc_taxi_sample" FROM 'https://s3.amazonaws.com/crate.sampledata/nyc.yellowcab/yc.2019.07.gz'
WITH (compression = 'gzip');
- ISS dataset
Note: we have a tutorial in the CrateDB Docs explaining all the steps below in detail. Check it out if you like.
For importing this dataset, let's use a Jupyter Notebook.
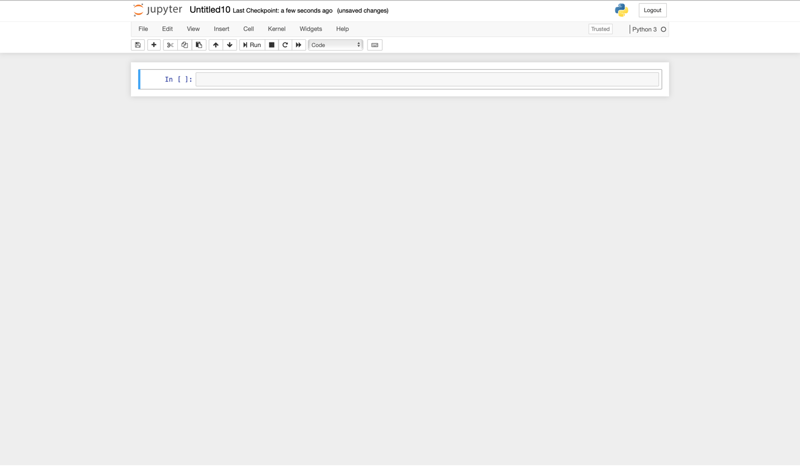
First, start a new notebook. In the Jupyter Notebook UI (localhost:8888), click on "New -> Phyton 3" (in the right upper corner). This will open a tab with a blank notebook.
The first step is to import the requests library. Type the following command in your notebook, and run it by pressing "Run":
import requests

Now, let's read the current position of the ISS. Type this:
>>> response = requests.get("http://api.open-notify.org/iss-now.json")
>>> response.json()
Your return will be the postion of the ISS in latitude/longitude coordinates. Something like this:

Next, let's encapsulate this operation with a function that returns longitude and latitude as a WKT string:
>>> def position():
... response = requests.get("http://api.open-notify.org/iss-now.json")
... position = response.json()["iss_position"]
... return f'POINT ({position["longitude"]} {position["latitude"]})'

When running this function, it will return your point string:
>>> position()

Now, let's import the crate client:
from crate import client
Next, connect to CrateDB:
connection = client.connect("localhost:4200")
And get a database cursor to execute queries:
cursor = connection.cursor()

Now, create a table in CrateDB to host the ISS coordinates:
>>> cursor.execute(
... """CREATE TABLE iss (
... timestamp TIMESTAMP GENERATED ALWAYS AS CURRENT_TIMESTAMP,
... position GEO_POINT)"""
... )

You will see the table in the CrateDB Admin UI.
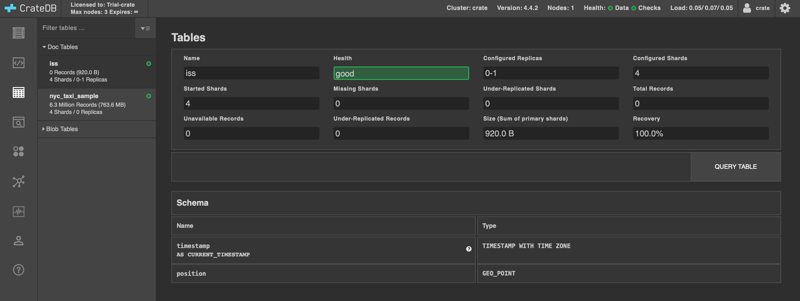
With the table in place, let's record the position of the ISS.
The following command calls the position function we defined earlier, insterting the result into the table we just created. Run it a few times to see several records.
>>> cursor.execute("INSERT INTO iss (position) VALUES (?)", [position()])
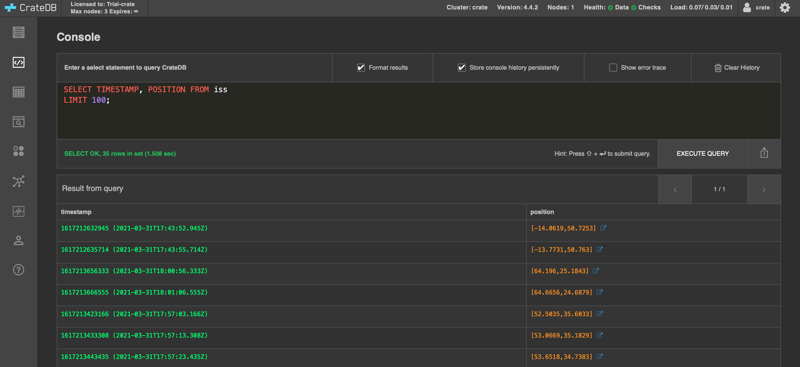
Now, SELECT that data back out of CrateDB:
>>> cursor.execute('SELECT * FROM iss ORDER BY timestamp DESC')
And fetch all the result rows at once:
>>> cursor.fetchall()
Now, automate the whole process. Paste and run the following code in your notebook:
import time
import requests
from crate import client
def position():
response = requests.get("http://api.open-notify.org/iss-now.json")
position = response.json()["iss_position"]
return f'POINT ({position["longitude"]} {position["latitude"]})'
def insert():
# New connection each time
try:
connection = client.connect("localhost:4200")
print("CONNECT OK")
except Exception as err:
print("CONNECT ERROR: %s" % err)
return
cursor = connection.cursor()
try:
cursor.execute(
"INSERT INTO iss (position) VALUES (?)", [position()],
)
print("INSERT OK")
except Exception as err:
print("INSERT ERROR: %s" % err)
return
# Loop indefinitely
while True:
insert()
print("Sleeping for 10 seconds...")
time.sleep(10)
Here, the script sleeps for 10 seconds after each sample. Accordingly, the time series data will have a resolution of 10 seconds. If you want to configure your script differently, feel free to do so!
You will see the script running, and the ISS data filling up into CrateDB.

Posted on April 8, 2021
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related



