Getting Started With JanusGraph

Sunny Srinidhi
Posted on February 25, 2021

JanusGraph is a graph processing tool that can process graphs stored on clusters with multiple nodes. JanusGraph is designed for massive clusters and for real-time traversals and analytics queries.
In this post, we’ll look at a few queries that you would want to run the very first time you install JanusGraph and start playing with the Gremlin console. I did this just yesterday, so it’s still fresh in my memory. I saw the need to write this as I didn’t find a few of my questions answered in the official documentation, and I had to hunt down the information on the world wide web, which took some quality time. So, let’s get started.
Installing JanusGraph
Installing JanusGraph is pretty straightforward, almost. I did face one issue and confusion while I was trying to get the servers up on my local machine. But upon research, I found out that many people are facing the same issue, and that it could be a bug. I didn’t have enough time to get into the weeds, so I just did what I had to to get it started.
To begin with, the official documentation is good enough for instructions on how to install and get the servers up. The issue I was talking about is that you need both Cassandra and Elasticsearch running to get the Gremlin server up. You can of course use alternatives to both Cassandra (such as HBase, Google Cloud Bigtable, Berkeley DB, or in-memory) and Elasticserach (such as Lucene, Solr, etc.), but I went the easiest route to get started with it.
The documentation says that you can skip mixed index backends (Elasticsearch, Solr, Lucene, etc.) and use only storage backends, but it doesn’t work. You need a mixed index backend along with a storage backend. So I had to download Elasticsearch as well and run it locally to get the Gremlin server up. This was a bit inconvenient, but no big deal, I guess. Now that we have all the moving parts moving as expected, let’s look at the data we’re going to play with.
The Sample Dataset
Here again I took the easy route of using the sample dataset that ships with JanusGraph. It’s an interesting one, called The Graph of the Gods. This data model, as seen below, is called a Property Graph Model. This particular property graph model shows a few Gods from the Roman pantheon, with their names, age, pets, places of living, and a few other relationships.
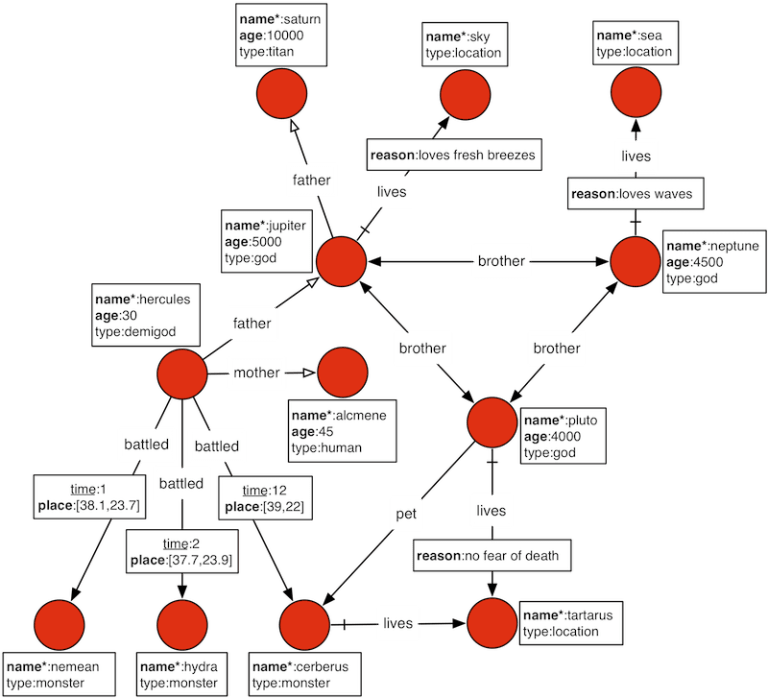
Source: JanusGraph
You can see that there are few special symbols in the graph. They have special meanings, of course.
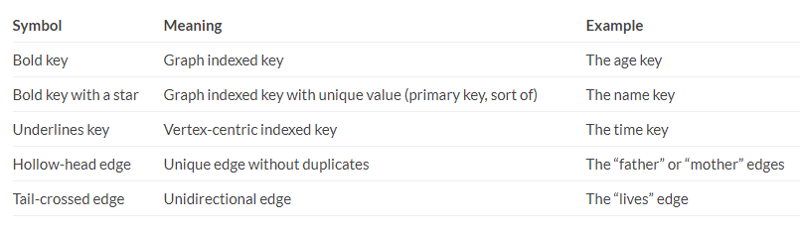
Now that we have the graph and know what the different edges mean, let’s see if we can traverse the graph. To do that, we first need to get a starting point, which is one vertex. We can use the .has("property", "value") method on the graph to find a vertex with a particular value. I’ll again go with the official example here.
We’ll start by getting the reference of the vertex with the “name” being “saturn.” For this, run the following query:
saturn = g.V().has('name', 'saturn').next()
Pretty straightforward. Now that we have the reference to the vertex in the saturn variable, let’s see how we can traverse to Saturn’s grandkid, Hercules. To find the grandson of Saturn, we first need to find the son of Saturn. From the graph, we can see that there’s an incoming edge called “father” from Jupiter to Saturn. We can use this edge to traverse further. Because we have an incoming edge, we’ll use the in() method on the saturn variable. Following is the query for this.
hercules = g.V(saturn).in('father').in('father')
The in() method accepts one parameter, which is the edge that has to be traversed. In this example, it’s the ‘father’ edge. So from Saturn, we go to the next vertex which has a ‘father’ edge coming into Saturn, which in this case is Jupiter. From there, we again have the same traversal – in('father'). This will take us to the son of Jupiter, which is Hercules.
If you want to go the other way, that’s finding the grandfather of Hercules, you can run the following queries:
hercules = g.V().has('name', 'hercules').next()
saturn = g.V(hercules).out('father').out('father')
As you can see, we’ve used the out() method here instead of in(). This is because we are traversing on the edge ‘father’ which is going out of the hercules vertex. It took me a while to understand when to use which method, but it’s very logical once I figured it out.
Loops
You would’ve observed in the last couple of queries, we did use the in('father') and out('father') methods twice in succession. This is a clear example where loops can be used instead of tailing the same method multiple times like this. And with JanusGraph, you can. There’s a simple repeat() method that makes this very easy. Below are the same queries rewritten with the repeat() method.
hercules = g.V(saturn).repeat(__.in('father')).times(2).next()
saturn = g.V(hercules).repeat(__.out('father')).times(2).next()
I don’t think it could be easier than this.
Selecting Multiple Vertices
Sometimes you’d want to query for multiple vertices in a single query. For example, if you want to query for the parents of Hercules, you’ll have to query one parent first, and then the other. You can imagine how this could slow down things when you are working with a distributed graph. To makes things easier and quicker, you can pass in a comma-separated list of edges that you want to traverse using the out() method. So if you want to query the parents of Hercules, you can just do this:
g.V(hercules).out('father', 'mother').values('name')
So elegant.
As I mentioned at the beginning of this post, this is just getting started. There’s a lot more to JanusGraph and Gremlin. I’ll be posting more about these two as and when I learn new things. So watch out for this space if you are interested.
And if you like what you see here, or on my personal or Medium blogs, and would like to see more of such helpful technical posts in the future, consider supporting me on Patreon and Github.
Posted on February 25, 2021
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related