Analysing Dataset Using Naive Bayes Classifier

Omale Happiness Ojone
Posted on April 26, 2021
In this article, we will discuss several things related to Naive Bayes Classifier including:
- Introduction to Naive Bayes.
- Naive Bayes with Scikit-Learn.
1.Introduction to Naive Bayes.
Naive Bayes classifier is a classification algorithm in machine learning and is included in supervised learning. This algorithm is based on the Bayes Theorem created by Thomas Bayes. Therefore, we must first understand the Bayes Theorem before using the Naive Bayes Classifier.
The essence of the Bayes theorem is conditional probability where conditional probability is the probability that something will happen, given that something else has already occurred. By using conditional probability, we can find out the probability of an event will occur given the knowledge of the previous event.
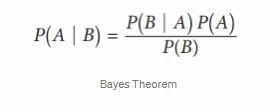
- P(A|B) = Posterior Probability, Probability of A given Value of B.
- P (B|A) = Likelihood of B given A is True.
- P (A) = Prior Probability, Probability of event A.
- P (B) = Marginal Probability, Probability of event B.
By using the basis of the Bayes theorem, the Naive Bayes Classifier formula can be written as follows :
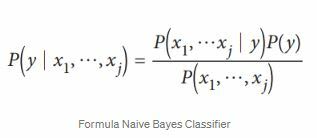
- P (y | x1, … , xj) = Posterior Probability, Probability of data included in class y given their features x1 until xj.
- P (x1, … , xj | y) = Likelihood of features value given that their class is y.
- P (y) = Prior Probability.
- P (x1, … , xj) = Marginal Probability.
Because marginal probability always remains the same in the calculation of naive bayes classifier, then we can ignore the calculation of marginal probability. In the Naive Bayes classifier, we determine the class of data points into based on the value of the greatest posterior probability.
2.Naive Bayes with Scikit-Learn.
Now that we know how to calculate the Naive Bayes Classifier algorithm manually, we can easily use Scikit-learn. Scikit-learn is one of the libraries in Python that is used for the implementation of Machine Learning. I am here using Gaussian Naive Bayes Classifier and the datasets that I use is glass classification which you should be able to download at the end of this article.
The steps in solving the Classification Problem using Naive Bayes Classifier are as follows:
- Load the library
- Load the dataset
- Visualize the data
- Handling missing values
- Exploratory Data Analysis (EDA)
- Modelling
1.Load several libraries of python that will be used to work on this case:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
import warnings
warnings.filterwarnings('ignore')
2.Load the dataset that will be used in working on this case. The dataset used is a glass dataset:
glass=pd.read_csv("glass.csv")
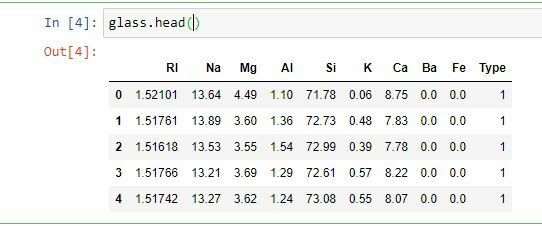
3.Look at some general information from the data to find out the characteristics of the data in general:
#Top five of our data
glass.head()
:
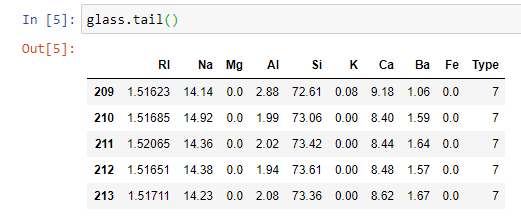
#Last five of our data
glass.tail()
:
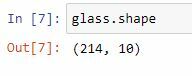
#Viewing the number of rows (214) and number of columns /
features (10)
glass.shape
4.Handling missing values from the data if there is any, if not then it can proceed to the next stage:
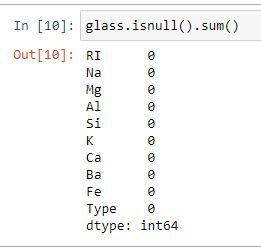
#Data is clean and can continue to the Explorary Data
Analysis stage
glass.isnull().sum()
5.Exploratory Data Analysis to find out more about the characteristics of the data:
#Univariate analysis Type (Target features).
sns.countplot(df['Type'], color='red')

6.Modeling our data with Gaussian Naive Bayes from Scikit-Learn:
#Create a Naive Bayes object
nb = GaussianNB()
#Create variable x and y.
x = glass.drop(columns=['Type'])
y = glass['Type']
#Split data into training and testing data
x_train, x_test, y_train, y_test = train_test_split(x, y,
test_size=0.2, random_state=4)
#Training the model
nb.fit(x_train, y_train)
#Predict testing set
y_pred = nb.predict(x_test)
#Check performance of model
print(accuracy_score(y_test, y_pred))
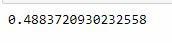
From the accuracy score, it can be seen that the value is 48% which in my opinion still needs to be improved again.
From my analysis, why the accuracy value of the Naive Bayes model is so low is due to imbalanced data. So one of the ways that I will use to improve the accuracy of my model is by data balancing.
Link to the dataset:https://www.kaggle.com/uciml/glass/download
Posted on April 26, 2021
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related
