SQL Concepts - Technical Paper

Ankit Kumar
Posted on May 12, 2023
ACID
ACID stands for Atomicity, Consistency, Isolation, and Durability. These properties are fundamental to ensure that transactions in a database system are reliable and maintain data integrity.
1. Atomicity
Atomicity ensures that a transaction is treated as a single unit of work that either succeeds or fails as a whole.
2. Consistency
Consistency ensures that a transaction must preserve the integrity constraints defined in the database schema.
3. Isolation
Isolation ensures that concurrent transactions do not interfere with each other. Each transaction must execute as if it is the only transaction in the system.
4. Durability
Durability ensures that once a transaction is committed, its effects are permanent and can survive system failures, such as power outages or hardware failures.

CAP Theorem
The CAP theorem states that it is impossible for a distributed system to provide Consistency, Availability, and Partition tolerance simultaneously.
1. Consistency
Consistency requires that all nodes in the distributed system see the same data at the same time. For example, if a user updates a record in one node, all other nodes must see the updated record immediately.
2. Availability
Availability requires that the system responds to every read or write request, even in the presence of node failures or network partitions.
3. Partition
Partition tolerance requires that the system continues to operate even when network partitions occur.
JOINS
Joins in SQL are used to combine data from two or more tables based on a common column or set of columns.
- Types of joins:- ### 1.INNER JOIN An INNER JOIN returns only the rows from both tables that have matching values in the join condition.
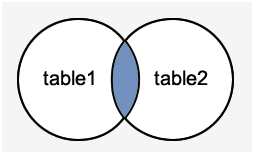
-
Syntax:-
SELECT columns FROM table1 INNER JOIN table2 ON table1.column = table2.column;
2. LEFT JOIN
A LEFT JOIN returns all the rows from the left table and the matching rows from the right table. If there is no matching row in the right table, the result will contain NULL values for the right table columns.
- Syntax:-

```
SELECT columns FROM table1
LEFT JOIN table2
ON table1.column = table2.column;
```
3. RIGHT JOIN
A RIGHT JOIN is similar to a LEFT JOIN, but it returns all the rows from the right table and the matching rows from the left table. If there is no matching row in the left table, the result will contain NULL values for the left table columns.
- Syntax:-

```
SELECT columns FROM table1
RIGHT JOIN table2
ON table1.column = table2.column;
```
4. OUTER JOIN
An OUTER JOIN returns all the rows from both tables, with NULL values for the columns where there is no match.
- Syntax:-

```
SELECT columns FROM table1
OUTER JOIN table2 ON table1.columns = table2.columns;
```
Aggregations, Filters in queries
Aggregations and filters are common operations used in SQL queries to summarize and manipulate data.
- Some common aggregations:-
- sum To calculate total column values.
- AVG
AVG()function returns the average value of a numeric column.- count
COUNT()function returns the number of rows that matches a specified criterion.- MAX
MAX()return max value of column.- MIN
MIN()returns min value of column
- Some filter technique:-
- WHERE
The WHERE clause specifies a condition that must be met for each row to be selected in the result set.
- You can also use comparison operators such as
less than (<),greater than (>),equal to (=),not equal to (!= or <>)and logical operators such asANDandOR,BETWEENto create more complex filter conditions. Here's an example:
SELECT *
FROM sales
WHERE (product = 'product_name' AND price > 100) OR price > 200;
NORMALIZATION
Normalization is the process of organizing data in a database to reduce data redundancy and improve data integrity. In Postgres, normalization is achieved through the use of various normal forms.
- First Normal Form (1NF) To achieve 1NF, a table must have a primary key and all columns in the table must contain atomic values (i.e., values that cannot be further decomposed).

CREATE TABLE orders (
order_id INTEGER PRIMARY KEY,
customer_name TEXT
);
CREATE TABLE order_items (
order_id INTEGER REFERENCES orders(order_id),
item_name TEXT,
PRIMARY KEY (order_id, item_name)
);
- Second Normal Form (2NF) > To achieve 2NF, a table must be in 1NF and all non-key columns must be fully dependent on the primary key. >
CREATE TABLE sales (
sale_id INTEGER PRIMARY KEY,
product_name TEXT REFERENCES
products(product_name),
product_price DECIMAL(10,2)
);
CREATE TABLE products (
product_name TEXT PRIMARY KEY,
product_category TEXT
);
- Third Normal Form(3NF) > To achieve 3NF, a table must be in 2NF and all non-key columns must be dependent only on the primary key (not on other non-key columns).
CREATE TABLE employees (
employee_id INTEGER PRIMARY KEY,
employee_name TEXT,
department_name TEXT REFERENCES departments(department_name)
);
CREATE TABLE departments (
department_name TEXT PRIMARY KEY,
manager_name TEXT
);
- Boyce CoddNormal Form (BCNF) > The first condition for the table to be in Boyce Codd Normal Form is that the table should be in the third normal form. Secondly, every Right-Hand Side (RHS) attribute of the functional dependencies should depend on the super key of that particular table.
INDEXES
Indexing is used to optimize the performance of a database by minimizing the number of disk accesses required when a query is processed.

Syntax:-
CREATE INDEX _index_name_
ON _table_name_ (_column1_, _column2_, ...);
TRANSACTIONS
A transaction is an action or series of actions. It is performed by a single user to perform operations for accessing the contents of the database.
-
States of Transactions
> A transaction in a database can be in one of the following states.

Active − In this state, the transaction is being executed. This is the initial state of every transaction.
Partially Committed − When a transaction executes its final operation, it is said to be in a partially committed state.
Failed − A transaction is said to be in a failed state if any of the checks made by the database recovery system fails. A failed transaction can no longer proceed further.
-
Aborted − If any of the checks fails and the transaction has reached a failed state, then the recovery manager rolls back all its write operations on the database to bring the database back to its original state where it was prior to the execution of the transaction. Transactions in this state are called aborted. The database recovery module can select one of the two operations after a transaction aborts −
- Re-start the transaction
- Kill the transaction
Committed − If a transaction executes all its operations successfully, it is said to be committed. All its effects are now permanently established on the database system.
LOCKING MECHANISM
Locking is a fundamental mechanism in database systems that allows
multiple users to access shared resources without interfering with each other.

- Types of Locking Mechanism
- Shared lock(S) > A shared lock can be imposed by several transactions at the same time over the same page or row and in that way several transactions can share the ability for data reading since the reading process itself will not affect anyhow the actual page or row data. In addition, a shared lock will allow write operations, but no DDL changes will be allowed.
- Exclusive lock > The exclusive lock will be imposed by the transaction when it wants to modify the page or row data, which is in the case of DML statements DELETE, INSERT and UPDATE. An exclusive lock can be imposed to a page or row only if there is no other shared or exclusive lock imposed already on the target.
- Update lock > An update lock is acquired when a transaction intends to modify a resource and wants to prevent other transactions from acquiring an exclusive lock on the same resource.
DATABASE ISOLATION LEVELS
Database isolation levels are a key feature of database management systems that allow multiple transactions to access the same data concurrently while maintaining data consistency and integrity.
- Different database isolation levels
- Read Uncommitted Isolation Level >The read uncommitted isolation level allows a transaction to read uncommitted changes made by other transactions,
- Read Committed Isolation Level > The read committed isolation level allows a transaction to read only committed changes made by other transactions, which eliminates dirty reads but can result in non-repeatable reads.
- Repeatable Read Isolation Level > The repeatable read isolation level guarantees that a transaction can read the same data multiple times without interference from other transactions, which eliminates non-repeatable reads but can result in phantom reads.
- Serializable Isolation Level > The serializable isolation level provides the highest level of consistency by ensuring that concurrent transactions appear to execute serially, which eliminates all types of concurrency anomalies but reduces concurrency to the lowest level.
TRIGGERS
A trigger is a set of actions that are run automatically when a specified change operation (SQL INSERT, UPDATE, DELETE or TRUNCATE statement) is performed on a specified table.
- Create trigger: In PostgreSQL, the CREATE TRIGGER command generates our first trigger step by step.
- Alter trigger: The ALTER TRIGGER command is used to rename a trigger.
- Drop trigger: The DROP TRIGGER command is used to define the steps to remove a trigger from a table
- Enable triggers: In the PostgreSQL trigger, the ENABLE TRIGGER statement allows a trigger or all triggers related to a table.
- Disable trigger: The DISABLE TRIGGER is used to display how we can disable a trigger or all triggers linked with a table.
Posted on May 12, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related




November 30, 2024