Scaling Your Team From 5 to 250 Engineers: A Complete Guide

CarmoBCosta
Posted on October 6, 2022
Picture a map of a city. If it’s zoomed in enough, you’ll have fine-grained visibility of street names, shops, traffic, and restaurants.
But as you zoom out, the more challenging it becomes to find helpful information.
As an engineering leader, the same thing happens when your organization grows.
When your engineering team is small, you have visibility into all the nitty-gritty details of your software delivery pipeline. You know which tickets are moving, you know the CI runs, and you probably even know which PRs are pending.
But, as your business and team grow, the challenges you face evolve. And you’re pulled further and further away from those valuable details.
The more you zoom out on the map, the less visibility you have. Fortunately, you can always zoom in when needed.
The trick is to know where to zoom in.
Today we will delve into the challenges you will face as your organization scales from 5 to 250 engineers by focusing on three dimensions of your software development pipeline:
🏎 Velocity
⭐️ Quality
🎯 Outcome
We will also cover:
👉 The engineering metrics you should look at within these three dimensions
👉 Important considerations before adopting engineering metrics tools
👉 Tips for making engineering metrics a success
Click here to download the printable one-pager of this guide!
Why Do We Look At Velocity, Quality, and Outcome?
Visibility is essential for organizations of all sizes.
But how do you go from that high-level visibility of a larger team, back to the details you had when your org. was smaller?
If there’s a challenge or a bottleneck, would you know where to zoom in to find the information you need?
Maybe it’s the CI system that’s slowing you down. Or maybe it’s the bug backlog that you’re struggling to work through. It could even be that your code base is slowing you down, and you need to pay down some tech debt.
You need to know where your challenges are, so you know what you have to do to fix them.
As engineering leaders, we have to zoom in and zoom out all the time.
If you have access to the right data, you’ll know exactly where to zoom in.
There are three dimensions that every engineering organization should focus on:
🏎 Velocity: How fast are we moving? Where are the bottlenecks in the team and process?
⭐️ Quality: What’s the quality of the software you deliver? How do you respond to quality issues? When we’re talking about “quality”, we’re referring specifically to quality that impacts the end user – think of bugs, incidents, downtime, etc.
🎯 Outcome: What are we shipping? Where are we investing our efforts when it comes to building new features, paying down tech debt, fixing bugs, maintenance, and R&D? How are we actually dividing our efforts? Most importantly, how is the impacting our customers?
Let’s look at some of the patterns organizations face as they scale from 5 to 250 engineers from the lens of velocity, quality, and outcome.
🏎 Velocity
Many engineering leaders believe that when you double your team, you will double the output. But the truth is that velocity - or the speed of shipping code - doesn’t increase linearly as a team scales.
If you’re growing fast, you’ll have a constant onboarding challenge, which takes a toll on speed. At the same time, your newly promoted leaders might lack the needed experience to support your organization's growth.
Here’s what actually happens to your velocity as you scale:

🌱 From 5 to 20 Engineers
At this stage, companies are trying to get to Product-market fit (PMF), which puts a lot of pressure on delivery. This “move/scale fast, break things” mentality can lead to companies keeping a steady speed but accumulating a lot of tech debt.
When the team is small, we must build a proper foundation.
💡 Recommendations:
- Avoid tech debt on everything that doesn’t allow you to scale in the future.
- Create some core processes to fix the developer experience continuously, but focus on market fit.
- Bring in a Head of Engineering who talks with their team leaders and understands blockers. They also needs to start thinking about the product and organization architecture to support the next growth level.
🪴 From 20 to 100 Engineers
When you start zooming out on the map, you lose visibility of the details.
Managers start having managers, and the new people you bring in will slow you down because it takes time to grasp the context of your product and organization.
If you didn’t set the right foundation you can lose 25-50% of effectiveness when your team gets this big.
You'll also begin to have misalignments, especially as your lines of communication increase:

💡 Recommendations:
- Bring expertise from the outside and promote internal people simultaneously so you can pair them.
- Create a team dedicated to developer experience while you keep teams on their toes.
- Double down on processes and goal definition - this is where you want to build the foundations for a 1000 dev team.
- Thoughtfully plan the structure of product teams (value delivery) and platform teams (product foundations and enablement) for what's coming afterward [Team Topologies]
🌳 From 100 to 250+ Engineers
As your company scales, your velocity may stagger due to a lack of visibility on bottlenecks and constant onboarding.
You'll continuously reshape the organization but lack clarity and visibility on where to act.
You are looking at the city 10.000 km in the air, which means you can’t see where bottlenecks are. This will slow you down.
💡 Recommendations:
- Train managers and tech leads to delegate so they can focus on team performance and people management.
- Systematically monitor organizational bottlenecks, gather with your leaders to discuss potential solutions, and define explicit goals for improving velocity.
- Push responsibility to the teams. They are the ones that can solve problems while you focus on minimizing interactions and communication lines between groups.
⭐️ Quality
Most of us fall into “the build trap”.
As we grow, we focus on delivering new features, eventually reaching a point where tech debt is too big for us to tame, which leads to a product rewrite.
If you’re growing fast, you’ll have to constantly deal with tech debt. Granted, most engineers will complain about tech debt, but they will never bring the consequential data to the table. This makes it hard to know where you are.
🌱 From 5 to 20 Engineers
When your organization's just starting out, there are not enough customers that a bug or outage could impact. So you focus on speed instead of quality. This is essential as you race to PMF.
However, as your customer base increases, you need to start digging into the quality of the product.
💡 Recommendations:
- Define a systematic process to capture the issues you’re facing and keep critical problems under control.
- Prioritize for bugs that block any potential growth. Your engineers will deal with a lot of bugs. It comes with the territory. But rather than getting bogged down in fixing them all at once, you should prioritize the bugs that might directly influence your product's growth.
- Promote good traceability and logging standards from the get-go. This way you'll always have a good idea of the sort of problems your engineers are facing, so you'll always know where to make improvements.
🪴 From 20 to 100 Engineers
PMF is evident and the size/value of your customer base increases - which means you’ll rapidly increase your nº of bugs and critical incidents, making the teams feel underwater.
If you lose focus, the product you built might no longer work for this market size.
💡 Recommendations:
- Have a strong bug backlog management, ensuring you fix all critical and high issues quickly.
- Remember that issue priority is based on frequency and severity, so you need to fix issues you know will hit you multiple times early on.
🌳 From 100 to 250 Engineers
All the challenges you faced when scaling from 20 to 100 engineers will continue to grow in line with your organization.
If you didn’t address issues as they came, some of your bugs will now come from the accumulation of tech debt, negatively impacting your MTTR.
In addition, teams will start pushing bugs to one another if you don't put good teams and architectural structures in place (Conway's law).
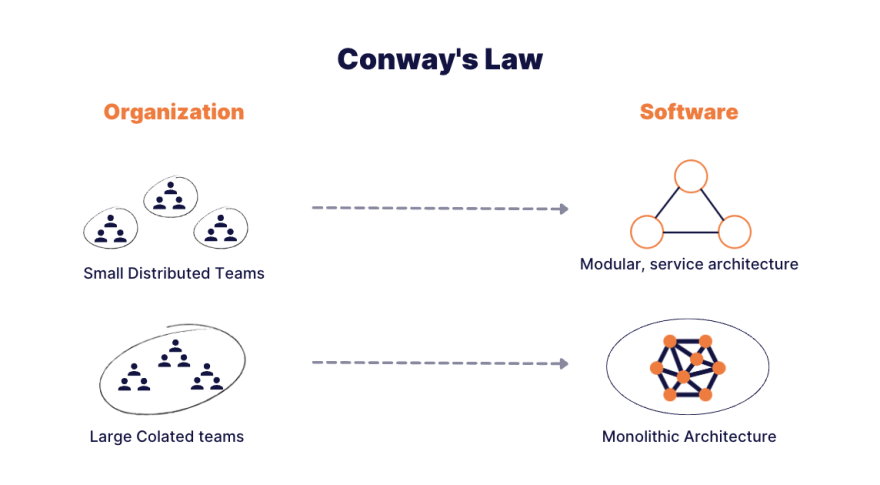
“Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization's communication structure.” — Melvin E. Conway
💡 Recommendations:
- Create solid team structures to avoid teams pushing bugs between each other and slowing things down.
- Platform teams should be taming MTTR. A low MTTR is what allows you to keep moving fast.
- Another critical metric you need to pay attention to is the change failure rate. 4. Commit to regular reviews to ensure you don’t just track these metrics - you act on them too.
🎯 Outcome
As engineering leaders, we’re constantly making trade-offs.
Seasoned leaders are masters at deciding where to invest efforts, and, as your organization grows, becoming more opinionated on the trade-offs between velocity, quality, and customer impact, is key.
If you’re growing fast, you’ll have to constantly deal with the features vs. quality tradeoff, which takes a toll on the capacity to deliver on the product. Again, being intentional in making these decisions will play a critical role in your success.

🌱 From 5 to 20 Engineers
Shipping is king at this stage.
Your roadmap is directly impacted by the conversations you’re having with your customers, so you’ll invest most of your efforts in new features.
However, the technical decisions made when you were <5 engineers will start to slow you down.
💡 Recommendations:
- Focus on new features until you achieve PMF, but pay attention to investment in bugs, developer efficiency, and architecture decisions that block the growth of your product.
- As for everything else, let it burn, but keep an eye on it.
🪴 From 20 to 100 Engineers
You now have a live product with a mature client base. It's time to move your efforts from primarily creating new features to honing in on internal processes.
Start being pragmatic about where you invest your time.
Remember that business value is everything that creates value for the business. So you will focus more and more on fixing bugs and cleaning tech debt, and less on new features.
💡 Recommendations:
- Ensure teams define and report their level of investment.
- Standardize processes across teams for you to understand effort investment at a high level.
- Don’t be punitive if teams don’t meet the investment level you were expecting. Understand why and help course-correct.
🌳 From 100 to 250 Engineers
Your visibility will continue to decrease at this stage, so trust is critical.
You might realize one quarter later, that the team wasn’t focused on delivering the features you were expecting. Teams will start to invest more time on bugs, and you'll get frustrated when the push for new features slows down.
Investment is the mastermind behind outcomes. Of course, you'll need to commit to internal processes and work quality, but you need to be decisive on time allocation and push a lot of these decisions to the teams.
💡 Recommendations:
- Think of investment as a strategic component, define quarterly/yearly goals, and adapt based on insights from regular meetings.
- Support and educate the teams on investment decisions. You also need to coordinate investment happening across the org and promote transparency with the other directors.
- Now that we’ve seen the challenges of scaling your engineering org, let’s dive into what engineering leaders can do to prevent these scenarios.
👉 It starts with data!
Velocity, Quality, and Outcome Metrics
We’ve seen what happens to your velocity, quality, and outcome as your team grows. What can you do to keep these things in check?
The key is to understand how different parts of your software delivery pipeline function to identify the levers you can pull for smooth sailing as you scale.
Modern software engineering organizations focus on delivering value through continuous delivery, integration, and improvement.
To make sure that this is happening, you need to keep a close eye on some key metrics.
🏎 Velocity Metrics
Velocity metrics help you access the agility and leanness of your team so you can understand how to improve the speed and direction of developing software across all the stages of the software delivery pipeline (WIP → Review → Merge → Release → Deploy).
Lead Time
Lead Time tells you how long it takes for your team to go from a ticket being in progress to a released PR, allowing you to detect early bottlenecks and resolve them on the spot.
Release Frequency
Release Frequency tells you how often you release value to your customers. Together with Lead Time, Release Frequency measures software delivery performance tempo.
Released PRs
The number of pull requests released during a period is an important metric to consider in combination with your PR Cycle Time. A decreasing Lead Time might be linked to a decrease in the number of released PRs.
PR Cycle Time
The elapsed time between the 1st commit of a PR and the code being used in production. Compared to the lead time, the PR cycle time focuses on just the code pipeline section.
⭐️ Quality Metrics
Quality metrics should be as close as possible to the end-user experience of your software.
Quality needs to be proxied by metrics that give an indication of the quality of the software delivered, such as no. of bugs by priority and bug fixing ratio.
Without quality metrics, it’s easy to find yourself going at a faster speed, or increasing volume, for the sake of your end-user experience.
Bugs Fixing Ratio
The Bugs Fixing Ratio is the ratio of bugs fixed to resolved during the time period selected.
Bugs Raised by Priority
Bugs Raised by Priority helps you get more granular information into the bugs raised by severity level. Did the team raise a lot of bugs last month? Were they all critical issues? Correlating this with other metrics, might help you identify the root-cause of the issue.
Mean Time to Restore by Priority
As an engineering leader, you want to make sure that your team is fixing customer-impacting issues the fastest.
🎯 Outcome Metrics
Outcome links engineering work to business goals, and it helps align the whole organization.
When building software, it's easy to lose sight of the business objectives we impact.
For instance, refactoring a major component without changing its behavior - how does that relate to our end user?
Other times we’re delivering a new feature in an application, such as the ability to buy a book online with one click instead of four - which can be mapped to the business objectives.
Throughput by work type
A throughput by work type can be looked at from the number of tickets fixed or the number of PRs released. It helps you understand if you’re truly aligning your engineering org with business goals.
Consider This Before Adopting Engineering Metrics
End-to-end visibility of your software delivery pipeline is key. By linking ticketing (like Jira) and code (Github), you can truly understand the leading indicator of a KPI and the root cause of an issue.
DORA metrics are great, but they are flat. Imagine you see an increase in PR Cycle Time: What do you do? How do you understand the root causes so you can solve the issue? You need to dig deeper.
Context matters: DORA metrics and fancy benchmarks show that high-performing teams should release >X times a day. But in our example above, the PR cycle time issue was linked to engagement, so it might be positive. Here’s a deep dive into why content matters.
Trying to continuously improve by tracking individual metrics will have the opposite effect and hurt your developer culture. If you’re monitoring throughput per developer, you will have a high throughput per developer. But will it have an impact on your business? Probably not. 👉 Instead, focus on getting visibility on your teams and coaching your engineering managers and team leads to build high-performing teams.
You Have Data, Now What?
There are two kinds of engineering leaders: the ones that have continuous improvement processes in place (like OKRs), and the ones that are starting on this journey.
Whether you have these processes in place or not, to continuously improve you have to have clear goals and visibility. You also need to know where you will invest your time.
If you already have a clear Northstar in place, we suggest you:
- Identify one metric to improve (don’t make it the most critical metric, but one that could be easily actionable, for example, review time.
- Add engineering metrics to your current processes, consistently look at data, and discuss how to improve
- Once you’ve made this a habit, look into more meaningful, even if challenging, metrics.
- Create a continuous feedback and improvement loop that cascades down to the teams.
If you don't use OKRs or other goal-setting methods, we recommend a more expansive look into these steps.
--
Engineering Leaders have two responsibilities:
👉 Improve the developer experience
👉 Deliver impact to the end-user
These two are infinitely linked, and, when done successfully, will help you create a culture of continuous improvement. We believe this can be done with the right metrics and data.
If you’re a new engineering leader, ask for help by reaching out to more experienced leaders. You’ll find that the great ones are those who are constantly questioning their own methods and looking for ways to improve.
Finally, don’t be afraid of the challenges ahead. You can feel lost when the map is zoomed out, but with the right tools, the right people, and the right mindset, you can take your product and company to new heights, and have a happy team while doing so.
Athenian can help you scale your engineering organization by giving you end-to-end visibility of your software delivery pipeline. So you’ll know where to zoom in to improve velocity and quality and align teams with company priorities. Find out more!
Posted on October 6, 2022
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.