
bradenrichardson
Posted on December 20, 2021

I wrote some BAD code and redesigned on the fly...
In the last post we had written the code to process a webhook event and set up the API infrastructure to support that.
This part was supposed to cover writing to a CSV file in an S3 bucket - well that has definitely changed. I have redesigned to support DynamoDB and honestly, it was what I should have done from the start.
Here's what the new system looks like:
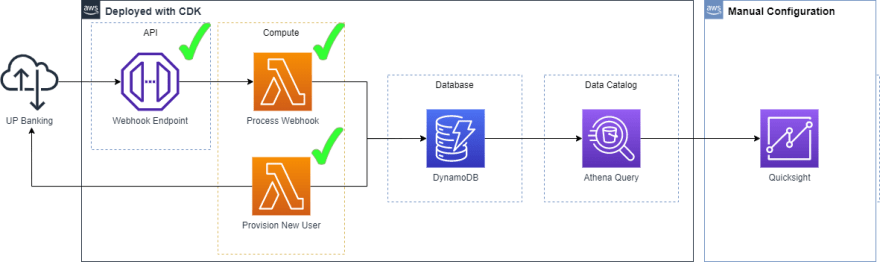
Why not CSV in S3?
- It's very hard to append to CSV files in S3, the functionality with Boto3 just isn't there
- The solution would have required more engineering and maintenance
- Not as cool
Why DynamoDB?
- Fully managed by AWS
- Fantastic Boto3 support
- Will scale with the system, CSV in S3 would have only been practical for so long
Setting up DynamoDB
This was my first time using DynamoDB and it was really easy to set up, let's go through it:
Create a table in DynamoDB - this is all very self explanatory, I'll be using the TransactionID as the partition key.

... That's it - almost seems too easy right? There's no tricks here, this is what a fully managed NoSQL database looks like. It's just very easy.
Writing to DynamoDB
This is where things get a little more interesting, although still quite simple. The objective is to modify both of our lambdas to write their respective payloads directly do DynamoDB.
Before we can attempt to write to DynamoDB, we need to make sure we have the correct permissions, now someone will probably say "this is your bad code right here" and they would be correct. Blanket "allow all" policies are bad, and I should feel bad. There is a security review staged for the end of v0.1 where I'll go through and ensure all policies are least privileged compliant - right now I'm purely focused on making things work.
"Effect": "Allow",
"Action": [
"dynamodb:*"
Now that we have granted our lambdas supreme DynamoDB control we can write some code. The boto3 support for DynamoDB is great, it's really easy to use and super intuitive. One of my favourite things about DynamoDB is that you don't have to define a schema before hand, at the minimum you need a partition key, and then you can just add any other key value pair that you want. 'S' and 'N' denote string or number values.
This is the function that the process webhook lambda uses:
def write_to_dynamo(dictionary):
dynamodb = boto3.client('dynamodb')
dynamodb.put_item(TableName='quicksightTest', Item={'TransactionID':{'S': dictionary['ID']},'Category':{'S': dictionary['Category']},
'ParentCategory' : {'S' : dictionary['ParentCategory']}, 'Value' : {'N' : dictionary['Value']}, 'Description' : {'S' : dictionary['Description']},
'CreatedAt' : {'S' : dictionary['CreatedAt']}})
The Bad Code
Is code bad if it works? Probably yes.
Why was it bad? A lack of concurrency and an overall inefficient design.
I replicated the process webhook code for the provision new user lambda. Makes sense right? It does basically the same thing just on a larger scale
Here's the code block as it stands:
def write_to_dynamo(dictionary):
dynamodb = boto3.client('dynamodb')
a = 0
for transaction in dictionary['id']:
dynamodb.put_item(TableName='quicksightTest', Item={'TransactionID':{'S': dictionary['id'][a]},'Category':{'S': dictionary['category'][a]},
'ParentCategory' : {'S' : dictionary['parentCategory'][a]}, 'Value' : {'N' : dictionary['value'][a]}, 'Description' : {'S' : dictionary['description'][a]},
'CreatedAt' : {'S' : dictionary['createdAt'][a]}})
a += 1
def lambda_handler(event, context):
dictionary = create_Dictionary()
write_to_dynamo(dictionary)
When I first tried running this, it timed out. Nothing to worry about, the lambda limit was only set to a minute, a large transaction history will take longer than that to download.

In the end I had to increase the lambda timeout to it's max of 15 minutes, and my lambda resource ran for ~13 minutes. This is clearly not ideal as my transaction history will only grow in size, meaning there will come a time when this code just does not work.
So what did I do?
Nothing.
If this was on the process webhook side I would have been forced to refactor and create a more efficient solution, but this function is only run once to provision a new user, it can afford to be inefficient for now.

Even though it's ugly, it worked, I now have 4,418 records in DynamoDB and more being added with every webhook event. Although it got me thinking about how I'm handling the compute, there are many ways I can improve the whole package. Stay tuned for those updates.
Today's Progress

- Created a table in DynamoDB
- Wrote a function that writes to DynamoDB
- Imported my entire transaction history to DynamoDB!!!
Next Post
Next up we will go through querying dynamoDB with Athena, and bringing our financial records into Quicksight - this is the fun stuff!
Posted on December 20, 2021
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related