Query materialized views with Java, Spring, and streaming database

Bobur Umurzokov
Posted on July 23, 2023

Materialized views are a powerful tool in database management systems that allow users to pre-compute and store the results of a query, improving performance and reducing the need for expensive computations. However, in modern, fast-paced business environments, the data in the database may change frequently, requiring frequent updates to materialized views. Streaming databases enable us to continuously ingest and process large amounts of data from different data sources in real-time. In this article, we will explore how to query materialized views with Java, Spring, and a streaming database such as RisingWave.
Learning objectives
You will learn the following throughout the article:
- How to ingest Kafka topics and run real-time queries.
- How to create materialized views with the streaming database.
- Build a Java application that reads and exposes data from materialized views.
Recommended content
Before proceeding with this post, I highly recommend also reading my other posts to understand how a streaming database differs from a traditional database, why we need to use materialized views to query microservices, and how to query real-time data in Kafka using SQL.
Sample scenario: Analyzing order delivery performance
Order delivery performance is a crucial metric for any business that sells products online. It reflects the efficiency and effectiveness of the order fulfillment process and directly impacts customer satisfaction. To analyze order delivery performance, businesses need to track key performance indicators (KPIs) such as delivery time, order accuracy, and delivery cost. In the scope of this article, we will create a sample order-delivery application (You can find the source code on GitHub) built using Java and Spring Boot and learn how to use a streaming database and materialized views to analyze food order delivery performance in real-time.
Below architectural diagram illustrating the overall data flow:
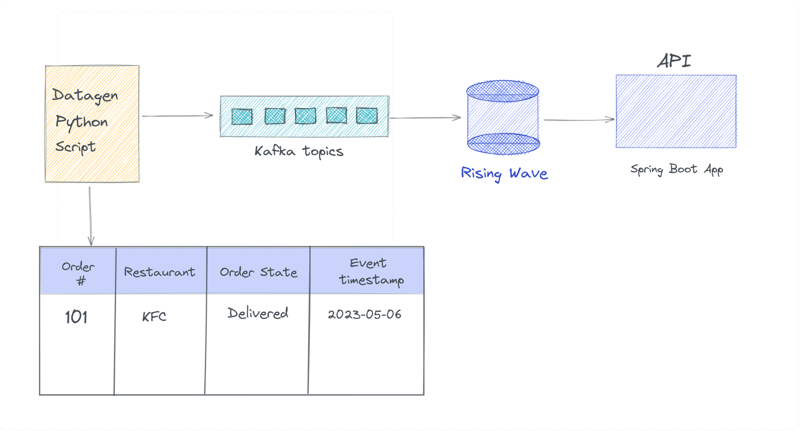
- We have a Kafka topic named
delivery_ordersthat contains events for every order placed on a food delivery website. Each event includes information about the order, such as theorder ID,restaurant ID, anddelivery status. The workload generator (Python script called Datagen) simulates generating of random mock data continuously and streams them into Kafka topics. In reality, this mock data can be replaced with data coming from the app. - RisingWave steaming database connects to a Kafka broker and reads Kafka topics using its Kafka connector. It also persists data from the source into a RisingWave table.
- RisingWave allows us to query streaming data using SQL and we can create materialized views that are optimized for complex queries by reducing the need for expensive joins and calculations. Data stored in the materialized view will be automatically updated as new changes arrive.
- Then, we query the materialized view from our sample Spring boot Web API.
Query materialized views demo
Let's assume we have a materialized view named restaurant_orders_view that calculates the number of total orders created from different restaurants within the last 15 mins in real-time. Now our task is to expose this materialized view result as an API endpoint in an Order service to /orders/count-total-restaurant-orders. In Java, you can query materialized views using JDBC, which is a Java API for connecting to databases. Additionally, you can leverage the Spring Framework to simplify the process of working with JDBC and build a REST API.
As RisingWave is wire-compatible with PostgreSQL, you can use the PostgreSQL JDBC driver to connect to RisingWave and interact with RisingWave from your Java applications. You can also use other clients’ libraries for different programming languages (NodeJS, Python, and Go).
The next sections show you a step-by-step guide to querying a materialized view in Java and Spring.
Before You Begin
This tutorial consists of setting up two projects:
- We will spin up on our local environment the existing RisingWave fully-featured demo cluster on GitHub which is composed of multiple RisingWave components. To simplify this task, it leverages docker-compose.yaml file which includes additional containers for Kafka message broker, and data generation service.
- Spring boot application, a Maven project with the necessary dependencies and we will also run it locally.
To complete this tutorial, you need the following:
- Ensure you have Docker and Docker Compose installed in your environment.
- Ensure that the PostgreSQL interactive terminal, psql, is installed in your environment. For detailed instructions, see Download PostgreSQL.
- Java 11 SDK or above.
- Your favorite editor, in my case I used Intellij Idea.
Step 1: Setting Up the demo cluster
First, clone the RisingWave repository to your local environment.
git clone https://github.com/risingwavelabs/risingwave.git
Then, navigate to the integration_tests/delivery directory and start the demo cluster from the docker compose file.
cd risingwave/integration_tests/delivery
docker compose up -d
Make sure that all containers are up and running!
Step 2: Copy and open the Spring Boot app.
Once the streaming database is set up, we will run our Spring Boot app. Also, fork/clone the project and open it in your Java editor.
git clone https://github.com/Boburmirzo/risingwave-java-spring.git
Step 3: Install the project.
Then do mvn clean install from the project root folder. In the maven pom.xml file, we added the postgresql dependency and the spring-boot-starter-jdbc driver dependency to our project. These dependencies will provide the necessary classes and interfaces to work with JDBC in Spring.
Step 4: Run the demo RisingWave application.
Now we can run our main DemoRisingWaveApplication.java from the editor. After you run the application, you access the endpoint on port 8080 or open this URL on your browser. http://localhost:8080/orders/count-total-restaurant-orders. You will get the materialized view response from RisingWave.
[["2023-05-06T05:28:00.000+00:00",1,1],["2023-05-06T05:33:00.000+00:00",1,3...]]
Breakdown the project files
Let’s break down some important files in the project to understand each role.
Connect to RisingWave
To query a materialized view in the Spring Boot app, you first need to establish a connection to the streaming database by configuring a Spring Boot application.yml file. The datasource section sets up a PostgreSQL database connection, with a RisingWave database URL of jdbc:postgresql://localhost:4566/dev (It is pointing to a dev database running on our RisingWave demo cluster), a username of "root", and an empty password.
server:
port: 8080
spring:
profiles:
active: dev
application:
name: materialized-view-api
datasource:
url: jdbc:postgresql://localhost:4566/dev
username: root
password:
...
Create a data source and materialized view
Next, in the Startup.java file, we have three SQL statements that are executed when the Spring Boot application starts up to create a source as Kafka in RisingWave, drop existing materialized views, and create new ones by reading this data from the view.json file in the application's resources directory that contains a list of materialized views to be created. For example, below is an SQL statement that creates a table called delivery_orders_source in the RisingWave streaming database. The table has four columns: order_id, restaurant_id, order_state, and order_timestamp.
public static final String CREATE_RISINGWAVE_SOURCE_TABLE = "CREATE TABLE IF NOT EXISTS delivery_orders_source (\n" +
" order_id BIGINT,\n" +
" restaurant_id BIGINT,\n" +
" order_state VARCHAR,\n" +
" order_timestamp TIMESTAMP\n" +
") WITH (\n" +
" connector = 'kafka',\n" +
" topic = 'delivery_orders',\n" +
" properties.bootstrap.server = 'message_queue:29092',\n" +
" scan.startup.mode = 'earliest'\n" +
") ROW FORMAT JSON;";
The statement also includes a WITH clause that specifies additional options for the table. In this case, the connector option is set to kafka, which indicates that the table will be connected to a Kafka topic. The topic option is set to delivery_orders, which specifies the name of the Kafka topic.
Query a materialized view with JdbcTemplate
Spring provides a number of features to help you work with databases, including the JdbcTemplate class, which simplifies the process of executing SQL statements and processing the results. To query a materialized view in Spring, you can use the JdbcTemplate class to execute a SQL query that selects data from the materialized view and then extract the data from the result set.
String createSql = String
.format(CREATE_MATERIALIZED_VIEW, materializeView.getName(), materializeView.getQuery());
jdbcTemplate.execute(createSql);
Query a materialized view with JPA
Once the materialized view has been created, it can be queried in Java using a Spring Data JPA repository as well. You can create a new entity class called RestaurantOrdersView that maps to the columns in the materialized view table in RisingWave.
@Entity
@Getter
@Setter
@Table(name = "restaurant_orders_view")
public class RestaurantOrdersView implements Serializable {
@Id
@Column(name = "restaurant_id")
private Long restaurantId;
@Column(name = "window_start")
private Timestamp windowStart;
@Column(name = "total_order")
private BigInteger totalOrder;
}
With the entity class in place, we can create a Spring Data JPA repository that allows us to query the materialized view using standard JPA query methods or you can a native SQL query. For example, the following code retrieves the total restaurant orders:
@Component
public class OrderDeliveryRepositoryImpl implements OrderDeliveryRepository {
@PersistenceContext
private EntityManager entityManager;
@Override
public List<RestaurantOrdersView> countTotalRestaurantOrders() {
Query query = entityManager.createNativeQuery("SELECT * FROM restaurant_orders_view WHERE restaurant_id = 1");
return query.getResultList();
}
}
This method countTotalRestaurantOrders can then be called from our OrderDeliveryService we can add extra business logic and pass it to OrderDeliveryController to make this data available through the REST endpoint.
@RestController
@RequiredArgsConstructor
@RequestMapping("/orders")
@CrossOrigin(value = "*", allowedHeaders = "*")
public class OrderDeliveryController {
private final OrderDeliveryService orderDeliveryService;
@GetMapping("/count-total-restaurant-orders")
@CrossOrigin(value = "*", allowedHeaders = "*")
public List<RestaurantOrdersView> getCountTotalRestaurantOrders() {
return orderDeliveryService.countTotalRestaurantOrders();
}
}
Conclusion
In conclusion, using a streaming database we can ingest streaming data from one or multiple data sources in real-time, you can merge multiple streams and create materialized views. Spring Boot provides built-in support for integrating with popular data sources, such as streaming databases. We have seen how businesses can analyze order delivery performance in real-time with the streaming database, Java, and Spring, enabling them to identify bottlenecks and improve the efficiency and effectiveness of their order fulfillment process.
Related resources
- How a streaming database differs from a traditional database.
- Why do we need to use materialized views to query microservices?
- Query Real-Time Data in Kafka Using SQL
Community
🙋 Join the Risingwave Community
About the author
Visit my blog: www.iambobur.com
Posted on July 23, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related