Discovery | Optimizing Facet Quality: Bloomreach’s Unique Solution to the Facet Selection Problem

Rory Warin
Posted on May 26, 2023
Shopping online can be overwhelming sometimes, especially when the shopping website offers a large variety of products. To provide a better user experience, most e-commerce websites nowadays are using the faceted navigation tool (facets) to help shoppers find the products they want quickly. However, it’s a fairly challenging task for the retailers to decide what would be the best attributes to use as facets. On one hand, it’s borderline erroneous to use the same set of attributes as facets across all search queries. For example, “color” is a good facet attribute for query “dress”, but it’s not as useful for query “phone charger”. On the other hand, it’s impractical to define different facets for millions of search queries.
Bloomreach Discovery is a high performance search engine and its dynamic facet feature is designed to tackle this exact problem. To utilize this feature, all that the retailers need to do is to use BR dashboard to configure the set of attributes they would like to use as facets regardless of the search query, and then the Bloomreach Discovery search engine will take care of the rest! Namely, for each particular query, the Bloomreach Discovery search engine will dynamically select and return the most relevant facets in the response.
The dynamic facet feature is one of many Bloomreach innovations that have helped online retailers greatly improve their digital experience. In this blog post, we will take a closer look at the details of this feature and how Bloomreach engineers overcame some of the technical challenges associated with it. Most of the following discussions will be based on Apache Solr. However, the ideas and principles should be applicable to other search platforms as well.
The Challenge
The dynamic facet essentially solves the facet selection problem: for any query, how to return the most relevant facets. At Bloomreach, multiple signals are used to determine the optimal facets, and one of the most important signals is the search recall data. However, this creates a significant challenge to the search workflow where Solr requires the list of facet attributes to be supplied in the request (before the recall set is generated). To solve this problem, Bloomreach engineers have considered several possible solutions. Here we will mainly discuss the following three:
- Two calls approach
- Request all and discard approach
- The Solr approach (preferred)
1: Two Calls Approach
This approach will make two internal Solr calls. When the customer sends a search request, we can make the first internal Solr call with an empty facet request. Instead of returning the response back to the customer, we can capture it and generate the desired facets by using its recall data. And then we can make the second Solr call with specific facet requests.
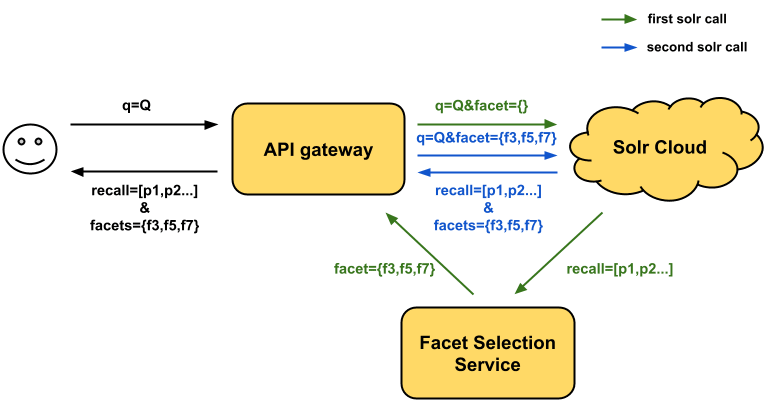
There are a few drawbacks associated with this approach. First, the end-to-end search service will have a higher latency. Since one external search request results in two full internal Solr searches, the internal processing time will be at least doubled considering the additional internal network latency. Second, the Solr servers will bear a higher load. The internal “query per second” (QPS) is doubled compared to the external search requests. Finally, this architecture incurs a high maintenance cost..
2: Request All and Discard Approach
This approach will only need one internal Solr call, but it heavily relies on a powerful response processing module. The idea is to make the Solr call with facet requests for all known attributes so that the response will contain the recall data and all the facet results. And then the response processing module can analyze the recall data and discard any facet that is deemed unuseful.
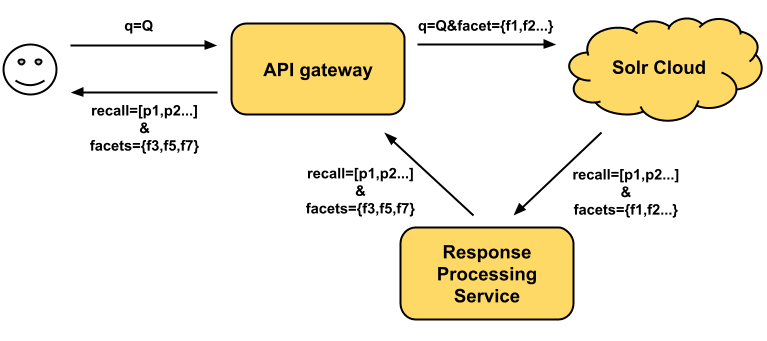
The downside of this approach is that it’s not scalable. In general, faceting is an expensive operation in Solr and the complexity grows linearly with the number of facets requested in the Solr call. If the retailers or business-to-business distributors have thousands of attributes defined for their catalogs, each Solr call will have to conduct thousands of faceting operations. Additionally, the Solr response size can be enormous. Therefore, it may require a lot of resources to transfer and process such large response data.
3: The Solr Approach (Preferred)
This is the architecturally simplest yet most performant approach of all three. In this approach, the facet selection logic is embedded within the Solr server, thus instead of explicitly sending facet requests to Solr, Solr will automatically select and return the optimal facets for each search request.
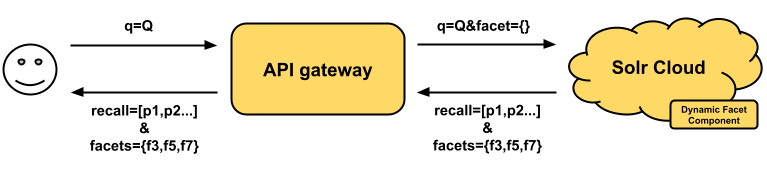
As we can see, the Solr approach does not require any additional full Solr call, expensive response processing, or setting up and maintaining additional services. Before we dive into the technical details, we will first briefly review the Solr architecture along with a few key components so that we can understand this “do it the Solr way” easily.
Apache Solr: Understanding the Blackbox
Apache Solr is a popular open source search platform that the Bloomreach Discovery search engine is built on. In this blog post, we will briefly review the parts of the architecture that are relevant to the implementation of dynamic facet. Please refer to the in-depth Solr architecture review published by my colleagues for more details.
The backbone of the Solr search workflow is a list of SearchComponents. By default, Solr provides a list of stock SearchComponents where each major search functionality such as querying, faceting, or highlighting is encapsulated. Two of the most important SearchComponents are QueryComponent and FacetComponent. They are mainly responsible for executing the query request and generating facets respectively.
Solr Configuration provides a way for developers to define their own SearchComponent. The “first-components” will be executed before the default SearchComponents and the “last-components” will be executed after the default SearchComponents. If there are multiple custom SearchComponents, the order of the definition will also be the order of execution.
The main coordinator of Solr search workflow is the SearchHandler. When the search request reaches the SearchHandler, an internal data structure called ResponseBuilder will be constructed. Then the SearchHandler will use ResponseBuilder as an envoy to supply necessary parameters to and collect intermediate results from each SearchComponent. After running the ResponseBuilder through all the SearchComponents, SearchHandler will simply return the search response. Depending on the search mode, the paradigms that SearchHandler uses ResponseBuilder and SearchComponents to execute the search are slightly different.
Non-Distributed Search
In the non-distributed search mode, SearchHandler simply executes the search logic via in-memory function calls. This is because all the necessary resources such as SearchComponents or Solr index are available on the same physical machine.
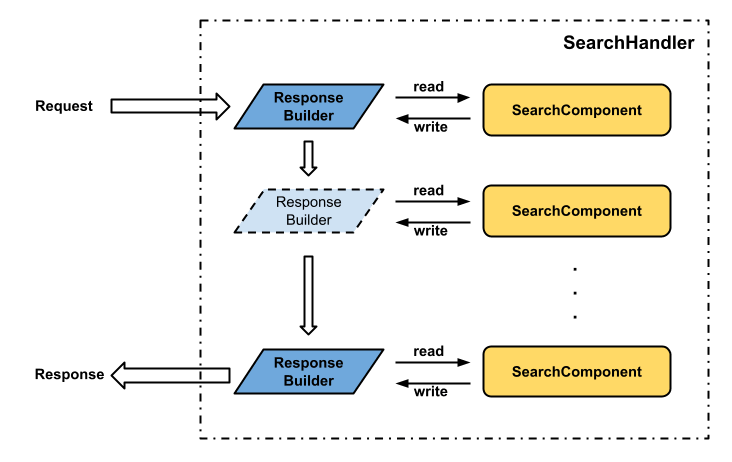
There are two main functions from SearchComponents that SearchHandler uses in this mode:
- public abstract void prepare(ResponseBuilder rb) throws IOException
- public abstract void process(ResponseBuilder rb) throws IOException
The prepare function is mainly used for initializing any dependencies required by later steps, and the process function is where the main logic lives. For example, QueryComponent uses prepare function to parse the raw solr query string and process function to execute the actual search.
SearchHandler executes these two functions in two different loops of SearchComponents. The prepare functions of all SearchComponents are executed before the process functions. The order of SearchComponents being executed is the same order defined in the solrconfig. This is important because there are interdependencies among these SearchComponents.
Distributed Search
In distributed search mode, one of the shards will be randomly selected as the leader to execute the SearchHandler logic. Because the full Solr index is split and placed onto different shards, the SearchHandler on the leader node will have to make multiple rounds of remote API calls (Solr calls it ShardRequest) to invoke each SearchComponent in order.
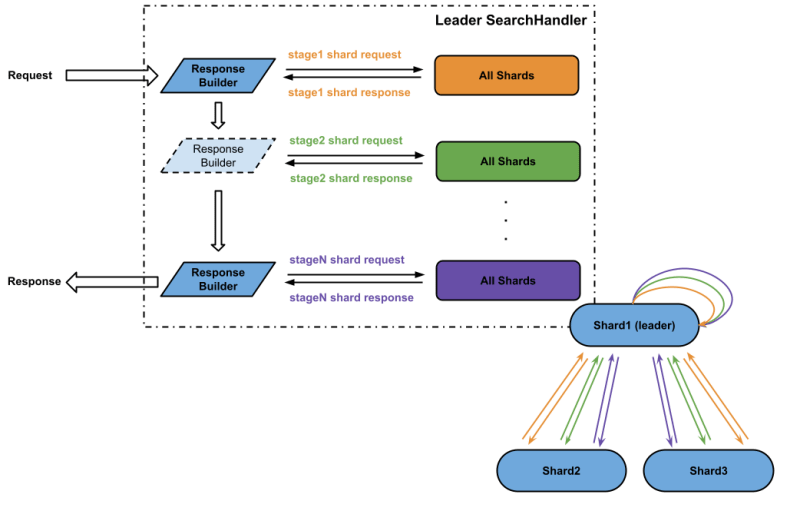
One of the most important concepts in the distributed search mode is the stages. Similar to the non-distributed search mode where SearchHandler executes the SearchComponents in a particular order, distributed search mode uses stages to control the order of SearchComponents being executed on the remote machine.
For a particular stage, the leader’s SearchHandler sends one or more ShardRequests to each shard, and these ShardRequests contain parameters to invoke only a few SearchComponents that are relevant to this stage. When the shard receives the ShardRequest, the SearchHandler on the shard will execute the ShardRequest in non-distributed search mode and return results from the requested SearchComponents as a ShardResponse. When the leader’s SearchHandler receives all the ShardResponses, it will simply aggregate all of them and store it back to ResponseBuilder before moving on to the next stage. This multi-stages execution model ensures that the interdependencies among SearchComponents can be fully honored.
There are four main functions from SearchComponents that SearchHandler uses in this mode:
- public int distributedProcess(ResponseBuilder rb) throws IOException
- public void modifyRequest(ResponseBuilder rb, SearchComponent who, ShardRequest sreq)
- public void handleResponses(ResponseBuilder rb, ShardRequest sreq)
- public void finishStage(ResponseBuilder rb) In the leader’s SearchHandler, these functions are called multiple times in a loop of stages:
ResponseBuilder rb;
List components;
List availableShards;
While (rb.stage != FINISHED) {
nextStage = Math.min(c.distributedProcess(rb) for c in components)
for(shard in availableShards){
shardResponse = send(rb.shardRequset).to(shard);
for(c in components) {
c.handleResponses(rb, shardResponse);
}
}
for(c in components){
c.finishStage(rb);
}
rb.stage = nextStage;
}
Most of the SearchComponents are using distributedProcess to compose the ShardRequest if needed as well as to return the next stage number given the current stage. The modifyRequest function will be called when a new ShardRequest is created and added to the ResponseBuilder. The handleResponses function is mainly used to execute special logic related to the ShardResponses. And the finishStage function is where most of the aggregation logic happens.
Putting it Together: Dynamic Facet SearchComponent
Now that the Solr blackbox is open and we know that the recall generation and facet generation are just two distinct steps in the solr search flow, we can actually encapsulate the facet selection logic into a SearchComponent (let’s call it DynamicFacetComponent) and inject it into the solr search flow.
It is important to place the DynamicFacetComponent after the QueryComponent so it can utilize the recall data. And the Solr stock FacetComponent can be reused to generate the actual facet data for the selected facet attributes.
The facet selection algorithm embodies the main dynamic facet business logic. Depending on the specific business use cases, we can get creative when we define the concrete facet selection heuristics. For example, for an apparel catalog, we can use the average price of the products in the recall as the signal to select the facet: if the average price is higher than $2,000, then “brand” or “designer” facets are more likely to be used by the luxury-clothes-seeking shoppers; if it’s lower than $50, then “discount” or “free shipping” facets may be more useful. The bottom line is that this “Solr approach” guarantees the facet selection logic’s access to the intermediate result from any SearchComponent such as the recall data from QueryComponent. This is guaranteed as long as the DynamicFacetComponent is placed after the depended SearchComponents. Of course, the facet selection signals are not limited to SearchComponent outputs. Signals such as shopper clickthrough data can also be supplied through Solr request parameters.
Non-Distributed Search
It’s important to invoke the facet selection logic in the process function because the prepare function is called before the search results are generated (the search recall data is generated by the process function in QueryComponent).
public class DynamicFacetComponent extends SearchComponent {
public void prepare(ResponseBuilder rb) throws IOException {
}
public void process(ResponseBuilder rb) throws IOException {
rb.setFacetRequest(selectFacets(rb));
FacetComponent.process(rb);
}
// rb should contain the recall data and other signals we may need
private List<FacetRequest> selectFacets(ResponseBuilder rb);
}
Distributed Search
For the distributed search mode, we can define a new stage that occurs after the stage where the recall data is generated. Therefore, we can select the facet in this later stage and send new ShardRequests with FacetComponent enabled:
public class DynamicFacetComponent extends SearchComponent {
static final int DYNAMIC_FACET_STAGE = RECALL_GENERATION_STAGE + 1;
public int distributedProcess(ResponseBuilder rb) throws IOException {
if(rb.stage < DYNAMIC_FACET_STAGE) return DYNAMIC_FACET_STAGE;
if(rb.stage == DYNAMIC_FACET_STAGE) {
rb.setFacetRequest(selectFacets(rb));
ShardRequest shardRequest = new ShardRequest(rb);
shardRequest.enableFacetComponent();
shardRequest.targetShards(rb.allShards);
// SearchHandler on the leader will send this shard request out
rb.shardRequest.add(shardRequest);
}
return FINISHED
}
public void handleResponses(ResponseBuilder rb, ShardRequest sreq) {
FacetComponent.handleResponses(rb, sreq);
}
public void finishStage(ResponseBuilder rb) {
FacetComponent.finishStage(rb);
}
public void modifyRequest(ResponseBuilder rb, SearchComponent who, ShardRequest sreq) {
}
// rb should contain the recall data and other signals we may need
private List<FacetRequest> selectFacets(ResponseBuilder rb);
}
Conclusion
In a nutshell, the Bloomreach Discovery search engine and its dynamic facet feature offer a point solution to help retailers deliver top-tier digital experiences. The adopted Solr approach leverages the SearchComponent interface to seamlessly integrate the dynamic facet logic into Solr. This innovative approach not only results in the simplest search application architecture, it also delivers the best performance.
At Bloomreach, the facet selection problem is just one of many search-related technical challenges that we’re facing everyday and we’re hoping to share more in the future. Happy searching!
private List selectFacets(ResponseBuilder rb);
}
Conclusion
In a nutshell, the Bloomreach Discovery search engine and its dynamic facet feature offer a point solution to help retailers deliver top-tier digital experiences. The adopted Solr approach leverages the SearchComponent interface to seamlessly integrate the dynamic facet logic into Solr. This innovative approach not only results in the simplest search application architecture, it also delivers the best performance.
At Bloomreach, the facet selection problem is just one of many search-related technical challenges that we’re facing everyday and we’re hoping to share more in the future. Happy searching!
Blog written by: Yue Yu from Bloomreach, 2021
Posted on May 26, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.