A beginner's guide to building a Retrieval Augmented Generation (RAG) application from scratch

Bill Chambers
Posted on October 31, 2023

Retrieval Augmented Generation, or RAG, is all the rage these days because it introduces some serious capabilities to large language models like OpenAI's GPT-4 - and that's the ability to use and leverage their own data.
This post will teach you the fundamental intuition behind RAG while providing a simple tutorial to help you get started.
The problem with learning in a fast moving space
There's so much noise in the AI space and in particular about RAG. Vendors are trying to overcomplicate it. They're trying to inject their tools, their ecosystems, their vision.
It's making RAG way more complicated than it needs to be.
This tutorial is designed to help beginners learn how to build RAG applications from scratch.
No fluff, no (ok, minimal) jargon, no libraries, just a simple step by step RAG application.
Jerry from LlamaIndex advocates for building things from scratch to really understand the pieces. Once you do, using a library like LlamaIndex makes more sense.
Build from scratch to learn, then build with libraries to scale.
Let's get started!
Introducing our concept: Retrieval Augmented Generation
You may or may not have heard of Retrieval Augmented Generation or RAG.
Here's the definition from the blog post introducing the concept from Facebook:
Building a model that researches and contextualizes is more challenging, but it's essential for future advancements. We recently made substantial progress in this realm with our Retrieval Augmented Generation (RAG) architecture, an end-to-end differentiable model that combines an information retrieval component (Facebook AI’s dense-passage retrieval system) with a seq2seq generator (our Bidirectional and Auto-Regressive Transformers [BART] model). RAG can be fine-tuned on knowledge-intensive downstream tasks to achieve state-of-the-art results compared with even the largest pretrained seq2seq language models. And unlike these pretrained models, RAG’s internal knowledge can be easily altered or even supplemented on the fly, enabling researchers and engineers to control what RAG knows and doesn’t know without wasting time or compute power retraining the entire model.
Wow, that's a mouthful.
In simplifying the technique for beginners, we can state that the essence of RAG involves adding your own data (via a retrieval tool) to the prompt that you pass into a large language model. As a result, you get an output.
That gives you several benefits:
- You can include facts in the prompt to help the LLM avoid hallucinations
- You can (manually) refer to sources of truth when responding to a user query, helping to double check any potential issues.
- You can leverage data that the LLM might not have been trained on.
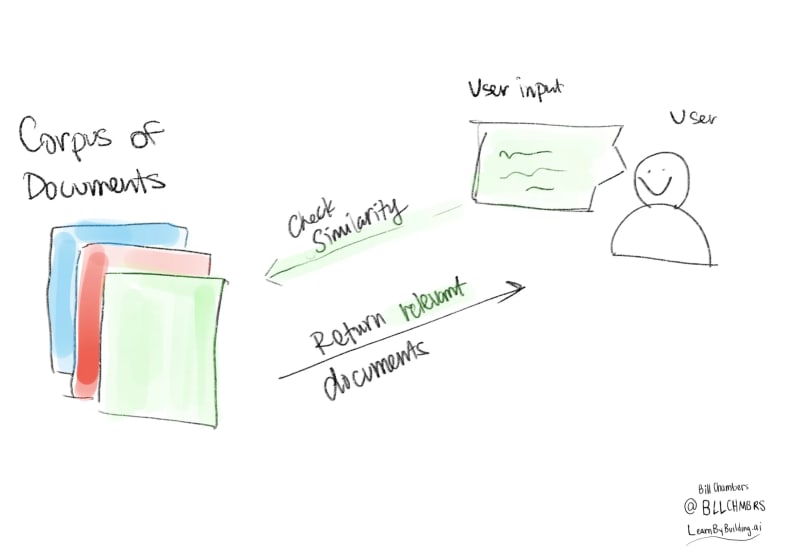
The High Level Components of our RAG System
- a collection of documents (formally called a corpus)
- An input from the user
- a similarity measure between the collection of documents and the user input
Yes, it's that simple.
To start learning and understanding RAG based systems, you don't need a vector store, you don't even need an LLM (at least to learn and understand conceptually).
While it is often portrayed as complicated, it doesn't have to be.
The ordered steps of a querying RAG system
We'll perform the following steps in sequence.
- Receive a user input
- Perform our similarity measure
- Post-process the user input and the fetched document(s).
The post-processing is done with an LLM.
A note from the paper itself
The actual RAG paper is obviously the resource. The problem is that it assumes a LOT of context. It's more complicated than we need it to be.
For instance, here's the overview of the RAG system as proposed in the paper.
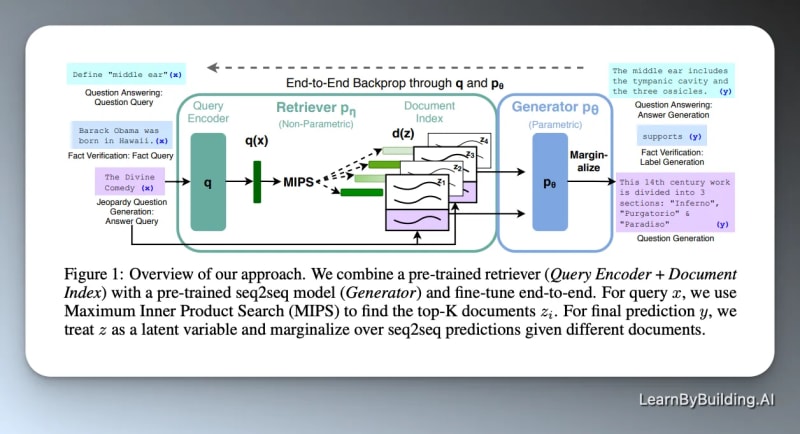
That's dense.
It's great for researchers but for the rest of us, it's going to be a lot easier to learn step by step by building the system ourselves.
Working through an example - the simplest RAG system
Let's get back to building RAG from scratch, step by step. Here's the simplified steps that we'll be working through.
Getting a collection of documents
Below you can see that we've got a simple corpus of 'documents' (please be generous 😉).
corpus_of_documents = [
"Take a leisurely walk in the park and enjoy the fresh air.",
"Visit a local museum and discover something new.",
"Attend a live music concert and feel the rhythm.",
"Go for a hike and admire the natural scenery.",
"Have a picnic with friends and share some laughs.",
"Explore a new cuisine by dining at an ethnic restaurant.",
"Take a yoga class and stretch your body and mind.",
"Join a local sports league and enjoy some friendly competition.",
"Attend a workshop or lecture on a topic you're interested in.",
"Visit an amusement park and ride the roller coasters."
]
Defining and performing the similarity measure
Now we need a way of measuring the similarity between the user input we're going to receive and the collection of documents that we organized. Arguably the simplest similarity measure is jaccard similarity. I've written about that in the past (see this post but the short answer is that the jaccard similarity is the intersection divided by the union of the "sets" of words.
This allows us to compare our user input with the source documents.
Side note: preprocessing
A challenge is that if we have a plain string like "Take a leisurely walk in the park and enjoy the fresh air.",, we're going to have to pre-process that into a set, so that we can perform these comparisons. We're going to do this in the simplest way possible, lower case and split by " ".
def jaccard_similarity(query, document):
query = query.lower().split(" ")
document = document.lower().split(" ")
intersection = set(query).intersection(set(document))
union = set(query).union(set(document))
return len(intersection)/len(union)
Now we need to define a function that takes in the exact query and our corpus and selects the 'best' document to return to the user.
def return_response(query, corpus):
similarities = []
for doc in corpus:
similarity = jaccard_similarity(user_input, doc)
similarities.append(similarity)
return corpus_of_documents[similarities.index(max(similarities))]
Now we can run it, we'll start with a simple prompt.
user_prompt = "What is a leisure activity that you like?"
And a simple user input...
user_input = "I like to hike"
Now we can return our response.
return_response(user_input, corpus_of_documents)
'Go for a hike and admire the natural scenery.'
Congratulations, you've built a basic RAG application.
I got 99 problems and bad similarity is one
Now we've opted for a simple similarity measure for learning. But this is going to be problematic because it's so simple. It has no notion of semantics. It's just looks at what words are in both documents. That means that if we provide a negative example, we're going to get the same "result" because that's the closest document.
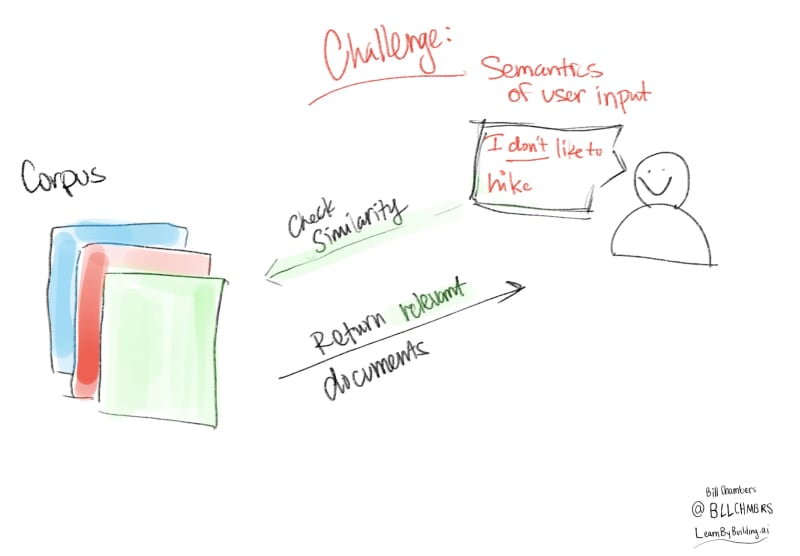
user_input = "I don't like to hike"
return_response(user_input, corpus_of_documents)
'Go for a hike and admire the natural scenery.'
This is a topic that's going to come up a lot with "RAG", but for now, rest assured that we'll address this problem later.
At this point, we have not done any post-processing of the "document" to which we are responding. So far, we've implemented only the "retrieval" part of "Retrieval-Augmented Generation". The next step is to augment generation by incorporating a large language model (LLM).
Adding in a LLM
To do this, we're going to use ollama to get up and running with an open source LLM on our local machine. We could just as easily use OpenAI's gpt-4 or Anthropic's Claude but for now, we'll start with the open source llama2 from Meta AI.
This post is going to assume some basic knowledge of large language models, so let's get right to querying this model.
import requests
import json
First we're going to define the inputs. To work with this model, we're going to take
- user input,
- fetch the most similar document (as measured by our similarity measure),
- pass that into a prompt to the language model,
- then return the result to the user
That introduces a new term, the prompt. In short, it's the instructions that you provide to the LLM.
When you run this code, you'll see the streaming result. Streaming is important for user experience.
user_input = "I like to hike"
relevant_document = return_response(user_input, corpus_of_documents)
full_response = []
# https://github.com/jmorganca/ollama/blob/main/docs/api.md
prompt = """
You are a bot that makes recommendations for activities. You answer in very short sentences and do not include extra information.
This is the recommended activity: {relevant_document}
The user input is: {user_input}
Compile a recommendation to the user based on the recommended activity and the user input.
"""
Having defined that, let's now make the API call to ollama (and llama2).
an important step is to make sure that ollama's running already on your local machine by running ollama serve.
Note: this might be slow on your machine, it's certainly slow on mine. Be patient, young grasshopper.
url = 'http://localhost:11434/api/generate'
data = {
"model": "llama2",
"prompt": prompt.format(user_input=user_input, relevant_document=relevant_document)
}
headers = {'Content-Type': 'application/json'}
response = requests.post(url, data=json.dumps(data), headers=headers, stream=True)
try:
count = 0
for line in response.iter_lines():
# filter out keep-alive new lines
# count += 1
# if count % 5== 0:
# print(decoded_line['response']) # print every fifth token
if line:
decoded_line = json.loads(line.decode('utf-8'))
full_response.append(decoded_line['response'])
finally:
response.close()
print(''.join(full_response))
Great! Based on your interest in hiking, I recommend trying out the nearby trails for a challenging and rewarding experience with breathtaking views Great! Based on your interest in hiking, I recommend checking out the nearby trails for a fun and challenging adventure.
This gives us a complete RAG Application, from scratch, no providers, no services. You know all of the components in a Retrieval-Augmented Generation application. Visually, here's what we've built.
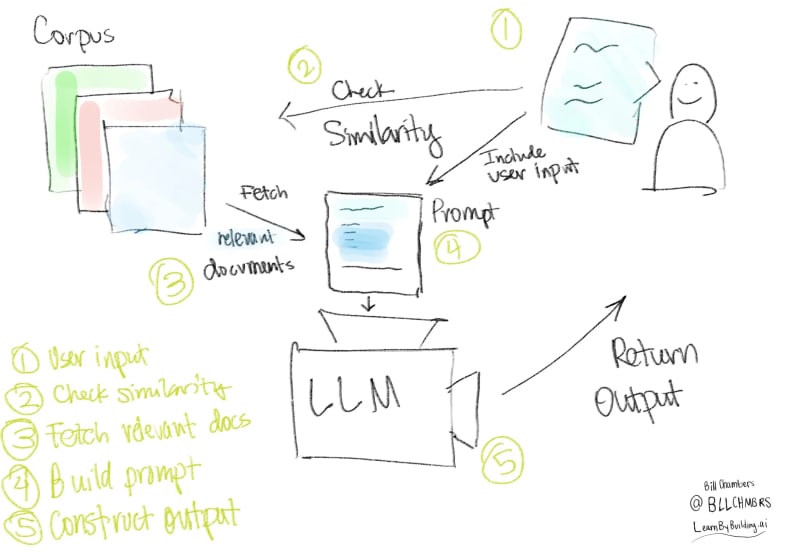
The LLM (if you're lucky) will handle the user input that goes against the recommended document. We can see that below.
user_input = "I don't like to hike"
relevant_document = return_response(user_input, corpus_of_documents)
# https://github.com/jmorganca/ollama/blob/main/docs/api.md
full_response = []
prompt = """
You are a bot that makes recommendations for activities. You answer in very short sentences and do not include extra information.
This is the recommended activity: {relevant_document}
The user input is: {user_input}
Compile a recommendation to the user based on the recommended activity and the user input.
"""
url = 'http://localhost:11434/api/generate'
data = {
"model": "llama2",
"prompt": prompt.format(user_input=user_input, relevant_document=relevant_document)
}
headers = {'Content-Type': 'application/json'}
response = requests.post(url, data=json.dumps(data), headers=headers, stream=True)
try:
for line in response.iter_lines():
# filter out keep-alive new lines
if line:
decoded_line = json.loads(line.decode('utf-8'))
# print(decoded_line['response']) # uncomment to results, token by token
full_response.append(decoded_line['response'])
finally:
response.close()
print(''.join(full_response))
Sure, here is my response:
Try kayaking instead! It's a great way to enjoy nature without having to hike.
Areas for improvement
If we go back to our diagream of the RAG application and think about what we've just built, we'll see various opportunities for improvement. These opportunities are where tools like vector stores, embeddings, and prompt 'engineering' gets involved.
Here are ten potential areas where we could improve the current setup:
- The number of documents 👉 more documents might mean more recommendations.
- The depth/size of documents 👉 higher quality content and longer documents with more information might be better.
- The number of documents we give to the LLM 👉 Right now, we're only giving the LLM one document. We could feed in several as 'context' and allow the model to provide a more personalized recommendation based on the user input.
- The parts of documents that we give to the LLM 👉 If we have bigger or more thorough documents, we might just want to add in parts of those documents, parts of various documents, or some variation there of. In the lexicon, this is called chunking.
- Our document storage tool 👉 We might store our documents in a different way or different database. In particular, if we have a lot of documents, we might explore storing them in a data lake or a vector store.
- The similarity measure 👉 How we measure similarity is of consequence, we might need to trade off performance and thoroughness (e.g., looking at every individual document).
- The pre-processing of the documents & user input 👉 We might perform some extra preprocessing or augmentation of the user input before we pass it into the similarity measure. For instance, we might use an embedding to convert that input to a vector.
- The similarity measure 👉 We can change the similarity measure to fetch better or more relevant documents.
- The model 👉 We can change the final model that we use. We're using llama2 above, but we could just as easily use an Anthropic or Claude Model.
- The prompt 👉 We could use a different prompt into the LLM/Model and tune it according to the output we want to get the output we want.
- If you're worried about harmful or toxic output 👉 We could implement a "circuit breaker" of sorts that runs the user input to see if there's toxic, harmful, or dangerous discussions. For instance, in a healthcare context you could see if the information contained unsafe languages and respond accordingly - outside of the typical flow.
The scope for improvements isn't limited to these points; the possibilities are vast, and we'll delve into them in future tutorials. Until then, don't hesitate to reach out on Twitter if you have any questions. Happy RAGING :).
References
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
- Jerry Liu on Twitter advocating for users to build RAG from scratch
If you like this post, you'll love what we're doing at learn By Building AI.
Posted on October 31, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.