Explicit Design, Part 1. Domain Modelling

Alex Bespoyasov
Posted on July 18, 2023

Let's continue the series of posts and experiments about explicit software design.
In the previous post, we defined the principles that we will adhere to when developing the application, and the code problems we want to avoid. In this post, we will talk about what a domain model is, why it is useful, and how we can use functional programming, static typing, and DDD to simplify modeling.
We will consider how to incorporate domain constraints directly into the code and simplify its testing. We will design the data flows and transformations that are involved in application use cases, and discuss how to speak with product owners, designers, and other business people in the same language.
But first, disclaimer
This is not a recommendation on how to write or not write code. I am not aiming to “show the correct way of coding” because everything depends on the specific project and its goals.
My goal in this series is to try to apply the principles from various books in a (fairly over-engineered) frontend application to understand where the scope of their applicability ends, how useful they are, and whether they pay off. You can read more about my motivation in the introduction.
Take the code examples in this series sceptically, not as a direct development guide, but as a source of ideas that may be useful to you.
By the way, all the source code for this series is available on GitHub. Give these repo a star if you like the series!
Domain Model
To write an application, the first thing we need to do is to understand what it will do—that is, describe a set of use cases and tasks that the application will solve, as well as various rules and constraints of its domain. In the Domain-Driven Design methodology, such a set of knowledge is called a domain model or domain.
Next, we will try to design a converter and describe its model in terms of types and functions. You can find the final result and source code for all examples in this post on GitHub.
Benefits of Modelling
The main goal of a domain model is to help us deal with the complexity and chaos of the real world. The model is such a scoped “snapshot of reality” that we can put in our heads and express in code.
Because the model is always simpler than reality, it includes not all the details of the domain, but only those that we consider important. And the first step in designing is to understand what details we want to include in the model.
Researching the Domain
Scott Wlaschin, in the book “Domain Modeling Made Functional,” suggests thoroughly researching the domain as the first step in modeling. The book suggests interviewing people who are not involved in the code but understand the domain we want to describe. These people could be, for example, product owners, UX designers, or business clients.
The goal of the surveys is to discover and formalize as many rules and constraints as possible that govern the world we are modeling. For example, before developing a converter, we can ask:
- Between which currencies will we perform the conversion?
- What level of accuracy do we want to see in the calculation?
- Where do we get quotes from? How often do they change?
- Can the user change the calculation currencies?
- How do we want to work with “negative values”?
- ...And so on.
Sometimes, in the surveys, we may come across “contradictions” or “inconsistencies.” This is a sign that we have not fully understood the details of the domain, and we should ask many clarifying questions. We should not be afraid to ask “stupid” questions because our view of the world may differ greatly from the product owner's or client's.
The more edge cases and “contradictions” we find through surveys, the more correct our understanding of the domain will be. And the more precise the understanding, the fewer mistakes we will make in modeling, and the fewer problems we will have in developing the application.
Details and Limitations
On the other hand, it's also not worth over-saturating the model with unnecessary or insignificant details. The simpler and the more compact the model, the easier it is to detect errors and inconsistencies with reality.
Our task is to extract as much information as necessary to start describing the domain rules. Over time, we will supplement and refine the model by working on its various parts.
Moreover, some details of the domain we will not include in the model at all. For example, in the converter, we will not include details on how currency quotes are set. It's important for us only where we get them from and in what form we will receive them. Such details are useful to know and consider but not necessarily to reflect in the code to avoid cluttering it.
Eric Evans' book “Domain-Driven Design” and Scott Wlaschin's “Domain Modelling Made Functional” are good resources on choosing which details to include in the model and which to omit.
Nuances of Modeling
It is worth noting that not every application necessarily requires a rich domain model. If we are building a simple CRUD app, there may not be complex business logic involved. The functionality of such an application would be limited to server requests and displaying received data on the screen, and it may not be necessary to distinguish a separate model.
Application Core
In many architectural styles, such as ports and adapters or clean architecture, the domain model is at the center of the application—in the so-called core. In addition to the domain, it contains code for use cases and specifications for how to “connect” these use cases with the real world (browser, third-party APIs and libraries).

We will use this metaphor and describe the converter's business logic as such an “application core.”
Assuming that we have already researched the domain and have answers to the questions from the above list, we can begin designing the model once we have an understanding of the domain.
Processes as Types
The domain model of the converter is not very large, and based on the answers to the questions above, we can roughly imagine how it will work.
We can imagine that when entering the value of one currency, it calculates the value of the second relative to known exchange rates. Ultimately, we will express these transformations as functions, but now it is too early to write functions. First, we will write a draft model in types and signatures.
The benefit of initial type-driven design is that types are easier and cheaper to modify than ready-made function code. At the same time, such a model still helps to understand the behavior of the system and even identify errors or missing data, to ask more clarifying questions. Each clarification will change the types of the model and capture more knowledge about the domain.
Then, when we see that the model in types is sufficiently elaborated, we will start implementing it in functions.
We will use such an approach with a separation into a “design level” and an “implementation level” quite often. For example, we will use it when composing features and the application as a whole, when designing use cases, and even when writing tests.
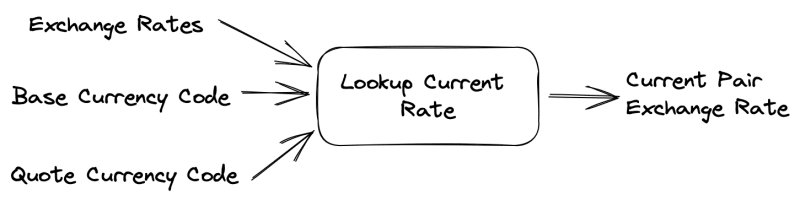
Let's try to model the processes through which data passes in the converter. The first such process is determining the exchange rate for the selected currency pair. We will need to obtain quotes for all currencies, as well as the codes for the base and quote currencies, and then retrieve their exchange rate from the quotes:
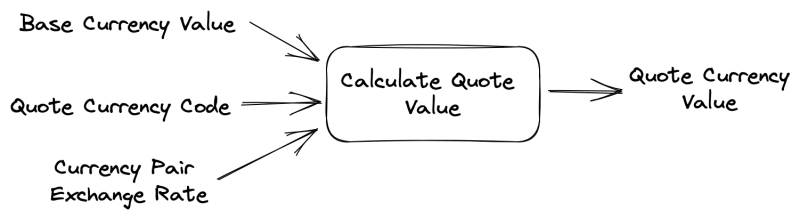
The second process is calculating the value of the quote currency based on the value of the base currency. For this, we need the exchange rate of the selected currency pair and the value of the base currency:
The third process is normalizing the values that we receive from the user. Our model will work not with any values, but only with a certain set. Values from such sets may have some constraints, for example, we can prohibit working with negative values of the base currency. We can also express such constraints in the model:

Data as Types
If we carefully examine the transformations we've made, we'll see that they are very similar to “function signatures.” And we can actually turn them into real functional types. For example, the definition of a currency pair exchange rate will become this type:
// domain/types.ts
type LookupRate = (rate: ExchangeRates, base: CurrencyCode, quote: CurrencyCode) => ExchangeRate;
Note that we have chosen domain-specific terms for the names of the function's arguments and result type, which we used on the diagrams.
The reason for that is we heard these terms from the product owner during our exploration of the domain. This way, we understood that these were the terms used by “business people” to describe the system. The language that contains these terms in DDD is called ubiquitous language, and we will use it in the code.
The purpose of ubiquitous language is to reduce losses when translating from the language of the business to the language of development. By using it, we “summarize” what we learned during our exploration directly as function signatures. This way, we reduce the probability of errors due to incorrect terms.
Since we do not yet have the types ExchangeRates, ExchangeRate, and CurrencyCode, TypeScript will complain. We will fix this by declaring type aliases for these types:
// domain/types.ts
type CurrencyCode = unknown;
type ExchangeRate = unknown;
type ExchangeRates = unknown;
For a first step, this is quite sufficient. Since our goal in the early stages is to validate the domain representation, aliases help express thoughts more formally, but still in a relatively free form that can be easily changed. (We can change the type name, add or remove an argument from the function signature, and we won't need to update a lot of code.)
We should note that at this stage we are not making any abstractions, but on the contrary, we are describing types as fully and explicitly as possible. The decision to generalize any data or functions will be made later, when we have enough information about how the project actually works—when the model becomes more accurate.
When we have more knowledge about the data structures we will be working with, we can return to aliases and refine the types. For example, when we have learned all the available currencies in the application, we can replace the CurrencyCode type with the actual one instead of unknown.
// domain/types.ts
// For example, we found out that there will be
// 5 currencies available in the application.
// Then we can describe them as a union type of string literals:
type CurrencyCode = 'RPC' | 'IMC' | 'WPU' | 'DRG' | 'ZKL';
As we further explore the domain, we may discover that an exchange rate is a ratio between two numerical values and does not have any units of measurement. Then, we can narrow down the type ExchangeRate by specifying that it is a decimal number:
// domain/types.ts
type ExchangeRate = Fractional;
// The Fractional type can be either a plain number
// or a special type that validates its values on creation.
// For now, we'll just express it as a number and come back later if needed:
type Fractional = number;
Aliases are not the most reliable way to introduce such constraints in TypeScript, but they are the most convenient for the design stage. We will talk about other ways to ensure types, such as branding, later, but for now, aliases will suffice.
Next, we can define the exchange rates themselves. Let's say that for each base currency, rates describe a pair of currencies and their exchange rates. Then we can express quotes as an object, where the keys are quote currency codes and the values are their exchange rates:
// domain/types.ts
// Set of exchange rates between the current base currency
// and all of the quote currency options:
type ExchangeRates = Record<CurrencyCode, ExchangeRate>;
Each type refinement captures more information about the domain in the signatures. This provides several benefits:
- We can already search for errors in the model or places where we lack information about the domain. When we formalize an idea in some way, we have to hold less information in our heads, which improves our attention, and we can more easily notice inconsistencies in the model.
- Code density increases because we express some information about the domain through types, and therefore we can add more details in the implementation.
- Fixing the model at this stage is very cheap because there is still no implementation, and we can “fine-tune” our understanding of the domain by simply changing the names of types and data structures.
Domain Constraints as Types
The purpose of the model is to describe how the domain works, and an important part of such a description is its constraints. Suppose we have learned that in our converter, the base currency will always be the same—Republican Credit (RPC).
The current model does not take into account this constraint, for example, the LookupRate function accepts any currency as the base one:
// domain/types.ts
type LookupRate = (
rate: ExchangeRates,
// Can use any of 5 available currencies:
base: CurrencyCode,
quote: CurrencyCode
) => ExchangeRate;
On one hand, this is a “generalization” for the future if we suddenly allow choosing the base currency for calculation. But on the other hand, we now lose an important difference between the base and quote currencies.
The missing difference expresses constraints on the number of possible values for each of the currencies. According to it, the base currency can only have one value, while the quote currency can be any of 5.
The difference in possible values tells us that we actually have 2 separate types. We can express this difference by dividing the CurrencyCode type into two separate ones:
// domain/types.ts
type BaseCurrencyCode = 'RPC';
type QuoteCurrencyCode = 'RPC' | 'IMC' | 'WPU' | 'DRG' | 'ZKL';
Now, the constraint and difference in the behavior of different currencies are visible directly in the types of their possible values. The potential for misunderstandings and hidden details decreases, and the model itself becomes more precise. This is especially important when other developers study the project in the future, for example, during onboarding.
Ideally, we should also mention the reason why we have only one base currency. If we can express the reason in types or code (for example, using variable names or types), it's better to do it right there. Otherwise, we can specify this reason in the project documentation.
After refining the model, we can see that the LookupRate type can be simplified by removing the base currency code from the arguments, as it never changes:
// domain/types.ts
type LookupRate = (rate: ExchangeRates, quote: QuoteCurrencyCode) => ExchangeRate;
Constraints in types can help “forbid” certain invalid states in the model. It is as if we take away the possibility of writing incorrect (from a domain perspective) code in the future because the type system will not allow it to compile.
Of course, this is more useful and reliable in more mature languages than TypeScript, but for expressiveness, I still recommend using this approach in TS.
Other Processes
Similarly, by exploring the domain and interviewing the product owner and other project participants, we can describe the other processes. For example, calculating the value of a quote currency relative to the base currency at a known rate will look like this:
// domain/types.ts
export type CalculateQuote = (base: BaseValue, rate: ExchangeRate) => QuoteValue;
Similarly, validating user input and converting it to the base currency value can be expressed as follows:
// domain/types.ts
export type ToBaseValue = (raw: ValueCandidate) => BaseValue;
type ValueCandidate = number | string;
...And so on until we have a more or less complete description of the domain.
Model Verification
Let's say we've gathered some number of data structures and their transformations and expressed them in types. Next, we'd like to evaluate how complete the model is and identify what further refinements may be necessary.
At this stage, it's important to identify unknown unknowns to assess whether we've included enough details in the model.
One way to validate the completeness is to compose various use cases using the types and data structures we have. For example, to convert one currency to another, we need to:
- Get currency codes and base value from the real world.
- Determine the current rate of the selected pair.
- Calculate the value of the quote currency based on the current rate.
If we express this algorithm in signatures and types, we will get something like:
// 1. Get data from the real world:
type GetInputData = () => ExchangeRates & QuoteCurrencyCode & BaseValue;
// 2. Determine the rate:
type LookupRate = (r: ExchangeRates, q: QuoteCurrencyCode) => ExchangeRate;
// 3. Calculate the value:
type CalculateQuote = (b: BaseValue, r: ExchangeRate) => QuoteValue;
For now, we don't have any functions to communicate with the real world, so we can't model the first step, but we have successfully expressed the remaining steps of the process in types.
Currently, we assume that the input data is provided to us by some function
GetInputData, which communicates with the outside world. In general, we could describe its type more precisely to take into account the data source, but for brevity, I decided to leave it out of the series. However, if you are interested in how this can be done, I recommend reading Scott Wlaschin's “Domain Modeling Made Functional.”
In the same way, we can verify other use cases. If we have enough created types and no additional questions arose during the process, we can start implementing the model in functions.
Functional Implementation of the Model
When we have expressed part of the domain in types and checked the model for consistency, we can proceed with the implementation. Note that implementation is not the “next step” but part of the design. This means that if we have questions about how the domain works during the implementation, we should stop and ask the product owner questions to clarify the model.
Design and development is an iterative process. It's okay to go back a step or two sometimes to improve the model and add newly discovered information. In the future, we'll stop paying attention to this, but let's stipulate that it's normal to make model refinements now and then even during later steps.
We will take advantage of the fact that TypeScript is multi-paradigm and write a model implementation in near-functional style. The code will not be purely functional, but we will try to gain the most out of the basic concepts of FP: pure functions, partial application, functional composition, and closures.
This approach on the one hand will not be overly complicated (we won't even mention monads 🙃), and on the other hand we will get high testability, debuggability, make the model explicit and composable.
Pure Functions
One of the basic concepts of the functional approach is pure functions. Pure functions are functions that do not produce side-effects and always return the same result given the same arguments.
One useful property of such functions is that they force us to keep the data and its transformations separate. The data and the code change with different rate and mixing them makes the system non-resilient to changes. When they are separated, however, it becomes easier to update the code; the transformations themselves become explicit, and the stages that the data goes through become visible.
By the way, the separation of data and actions is one of the basic concepts not only in FP, but in DDD, too.
To understand the power of pure functions, let's look at an example. Below, the result of the createBaseValue function depends only on its argument, and we can be sure that if we pass the same value we will get the same result:
export const createBaseValue: ToBaseValue = (raw) => {
const candidate = Number(raw);
return Number.isNaN(candidate) ? 0 : Math.abs(candidate);
};
// Strictly speaking, the result is also affected
// by the `isNaN` and `abs` functions,
// but for simplicity, we assume that they are also pure.
Being sure we get a certain result helps abstract away the less important details and focus on higher-level processes. In our case, the createBaseValue function sort of encapsulates the details of how to convert a raw value to a domain type.
This gives us the ability to build more complex processes using these functions as components of such processes:
const rawValue = '42';
const baseValue = createBaseValue(rawValue);
const quoteValue = calculateQuoteValue(currentRate, baseValue);
// Data goes through several stages:
// RawValue -> BaseValue -> QuoteValue
// "42" -> 42 -> 1.46
// We can think of this sequence
// as a single stand-alone process.
And since we are sure that with the same arguments we will get the same result, we can replace the part of the process by the result of the function calls that make up the process:
// Replace first 2 steps with a value:
const baseValue = 42;
const quoteValue = calculateQuoteValue(currentRate, baseValue);
// We get the same result, because the `createBaseValue` function is pure
// and we can replace its call with the result.
This property is called referential transparency, and it helps to focus on the parts of the process that interest us by abstracting out the details of the previous parts:

So referential transparency and pure functions make the domain model easy for verifying, testing, and visualizing data flows.
Data Consistency
We can use referential transparency and the convenience of pure functions to formalize invariants of the model—rules and properties of data that must always be met.
For example, the function createBaseValue guarantees that the output value will always be a number greater than or equal to 0. This output value property is an invariant.
The function tells us that values of type BaseValue can only be numbers within a certain range ([0, Infinity)), and all values “from the outside world” have to go through this “filter” before they get into the domain model. Invariants help keep the data inside the model internally consistent.
The desire for consistency, by the way, also forces us to look for errors in the model early in the design process, when it's still relatively cheap to make changes to the code.
Since the value normalization rule is contained entirely inside the createBaseValue function, the rest of the model code doesn't have to worry about the validity of the BaseValue type—that's taken care of by the factory function createBaseValue. Such a contract between modules helps separate the obligations and limit future code changes.
The rest of the code knows that if the value type is BaseValue, then the value came out of the createBaseValue function and is by definition valid. Other functions can use that value, relying on that fact and not checking the value again. As a result, the validation rules are collected in one place and not scattered throughout the model code.
Contracts between modules are the basis of low coupling. We'll talk about coupling and cohesion in detail in the future posts.
Of course in TS, we can bypass such restrictions and assign the
BaseValuetype on any value. Then the contract will be broken and no guarantees can be given to other functions. There are various ways to deal with this, but for the sake of brevity we will consider the case where values of typeBaseValueappear only from the factory.
Encapsulation
Another example of a contract and declaring rules would be the lookupRate function. This function contains a rule for searching a rate between a pair of selected currencies:
export const lookupRate: LookupRate = (rates, against) => rates[against];
This function frees the others from the need to know where the rate value of the selected currency pair comes from. The other functions can rely on a guarantee (contract) that the result of calling lookupRate will always be a correct and valid exchange rate.
The lookupRate function guarantees that the exchange rate will be valid even if the ExchangeRates structure changes. It will take care to correctly get the right data out of ExchangeRates and provide it as a result.
This behavior, when the module guarantees the validity of its data and best knows how to provide it, is called encapsulation. It allows us to limit the propagation of code changes throughout the code base.
For example, if we change the ExchangeRates type, the code updates will stop at the boundaries of the lookupRate function:
type ExchangeRates = Record<CurrencyCode, ExchangeRate>;
type UpdatedExchangeRate = List<[CurrencyCode, ExchangeRate]>;
// Before changes we extracted data this way:
const lookupRate = (rates, against) => rates[against];
// After—slightly differently:
const lookupRate = (rates, against) => rates.find(([code, rate]) => code === against).at(1);
// But all the code that relied on the `lookupRate` call
// is unchanged because the change effect
// is scoped by the `lookupRate` function:
const currentRate = lookupRate(exchangeRates, 'IMC');
This way the rest of the code can be sure that as long as it correctly calls the lookupRate function and passes it all the necessary arguments (it does its part of the contract), as a result it will get a valid exchange rate for the current currency pair (the lookupRate function will do its part of the contract).
Intrinsic Testability
We mentioned earlier that pure functions help make the model easy to test. This comes from the assumption that pure functions are intrinsically testable—they don't require complex test infrastructure, their tests don't take long to set up, and they only need input data and the expected result to run.
For example, to test createBaseValue we can write this test:
describe('when given a number-like value', () => {
const expected = 42;
const cases = [42, -42, '42'];
it.each(cases)('returns the domain base value', (value) => {
const result = createBaseValue(value);
expect(result).toEqual(expected);
});
});
This test is easy to understand, easy to write, and it fits perfectly into the AAA (Arrange, Act, Assert) paradigm:
describe('when given a number-like value', () => {
// Arrange:
const expected = 42;
const cases = [42, -42, '42'];
it.each(cases)('returns the domain base value', (value) => {
// Act:
const result = createBaseValue(value);
// Assert:
expect(result).toEqual(expected);
});
});
All this makes testing pure functions straightforward. We don't need to think about what and how we're going to test, because pure functions have only one place we can test—the returned result.
Simple tests are easy to support and more resistant to changes because a simple test infrastructure has fewer points of failure. It's less likely to need fixing after library updates, we less likely will need to rewrite the tests themselves because it's harder to “break” input data than, for example, mocks.
For unit testing, pure functions are also great because simple tests don't require a lot of resources. Since we don't need to create providers, renderers, wrappers, mocks, etc., pure function tests will be on average faster.
Finally, pure functions are convenient to test not only for happy path, but also for failure cases. For example, for createBaseValue we can write such a set of non-happy-path tests:
describe('when given a non-number value', () => {
const cases = ['string', '42n', NaN, [], null, undefined, {}];
it.each(cases)('returns 0 base value', (value) => {
const result = createBaseValue(value);
expect(result).toEqual(0);
});
});
Test-Driven Development
Referential transparency, intrinsic testability, contracts on the behavior, and types for data and processes in the domain allow us to use another tool in modeling—Test-Driven Development, TDD.
TDD is a methodology where we first write tests for the function we are going to implement, and only then the function itself. The idea behind TDD is to take small steps and develop the code in short iterations, developing it from the simplest implementation to the most complex version.
I won't describe the approach in detail in this post, but if you're interested in reading about TDD in detail, I recommend checking out my post about TDD and my Testing React Applications talk. I also recommend reading book by Vladimir Khorikov about unit testing.
I understand that not all developers like to work with TDD, and that's fine; I'm not going to “sell” this methodology to anyone. My goal in this post is to show how to use TDD as a design tool so that you have more information to decide whether to use it.
For this purpose, let's try to write a function that implements the CalculateQuote type by TDD. We can start by describing the boundaries of the functionality we are going to implement with .todo():
// Describe what functionality we need in the end:
describe('when given a base value and the current rate', () => {
it.todo('returns the correct quote value');
it.todo('should have a precision of two decimal places');
});
At this point, we may have additional questions about how the model works. For example, how to handle edge cases or what data we are ready and not ready to accept.
In fact, the new questions are a good thing, because by formalizing through .todo a scope of functionality, we refine the model. Each question about system behavior adds more real-world knowledge to the code, making the model more accurate. At the same time, we don't have the code of the function itself yet, which means it's cheap to make changes to the model.
When we have decided how the calculateQuote function should behave, we can write the first test. Let's describe the behavior of the function with the correct input data:
type TestCase = {
base: BaseValue;
rate: ExchangeRate;
expected: QuoteValue;
};
// ...
it.each<TestCase>([{ base: 10, rate: 1, expected: 10 }])(
'returns the correct quote value',
({ base, rate, expected }) => {
const result = calculateQuote(base, rate);
expect(result).toEqual(expected);
}
);
Next, we need to make sure that the test fails. This is important because only a failing test really checks something, and we want to make sure that our tests are not useless.
Then we have to check the reason why the test is failing. Right now, the test is failing because the calculateQuote function is undefined. That's not what we expect in a test. So let's add a function and make sure the test crashes for the reason we want:
const calculateQuote: CalculateQuote = (base, rate) => 42;
Then we'll get:
19| ])("returns the correct quote value", ({ base, rate, expected }) => {
20| const result = calculateQuote(base, rate);
21| expect(result).toEqual(expected);
| ^
22| });
23|
- Expected "10"
+ Received "42"
Now that we have seen that the reason for the failure matches our expectations, we can proceed with the real implementation. Checking the failure reason is important because we want to make sure that tests validate our expectations of the model (rules, invariants, and data transformations). When we make the test fail for the reason we want, we make sure that the test validates the correct expectation.
Generally speaking, according to TDD the first test and its implementation should be as simple as possible so that the development cycle is short—no more than 5 minutes. In this post I decided to cut corners a bit and skip this aspect for the sake of brevity. But again, I'll leave additional material on this topic at the end.
Next we can write the actual implementation:
const calculateQuote: CalculateQuote = (base, rate) => base * rate;
When the first test passes, we can take time to refactor the code or tests and, for example, add other test cases to capture a little more behavior:
it.each<TestCase>([
{ base: 10, rate: 1, expected: 10 },
{ base: 10, rate: 2, expected: 20 },
{ base: 10, rate: 4.2, expected: 42 }
]); // ...
After that we make sure that all the written tests pass. This is also an advantage of TDD, because each step of development is secured by already written tests. (It's clear that the quality of this “insurance” depends on the quality of written tests, but that's a slightly different question).
Next, we can describe the tests for the second case, to make sure that the function rounds fractions to 2 decimal places:
it.each<TestCase>([
{ base: 10, rate: 1.12, expected: 11.2 },
{ base: 10, rate: 0.72, expected: 7.2 }
])('should have a precision of two decimal places', ({ base, rate, expected }) =>
expect(calculateQuote(base, rate)).toEqual(expected)
);
We make sure that the tests fall because of rounding. After that we write the implementation:
const calculateQuote: CalculateQuote = (base, rate) => Number((base * rate).toFixed(2));
...And we check that all the tests pass. In the same way we can describe non-happy-path cases for this function and design other aspects of its behavior.
Function Composition
As we mentioned earlier, a useful property of the functional approach in modeling the domain is that it encourages us to separate data from its transformations.
We can see this difference just by looking at our model types:
// Data:
type BaseCurrencyCode = 'RPC';
type QuoteCurrencyCode = 'RPC' | 'IMC' | 'WPU' | 'DRG' | 'ZKL';
type ExchangeRates = Record<QuoteCurrencyCode, ExchangeRate>;
// Data Transformations:
type LookupRate = (r: ExchangeRates, q: QuoteCurrencyCode) => ExchangeRate;
type CalculateQuote = (b: BaseValue, r: ExchangeRate) => QuoteValue;
This separation helps us to make explicit all the stages through which the data pass. When all actions are visible and their results are predictable, the model contains fewer hidden details that can affect the final state of the data.
Domain processes become sequential sets of actions, and we can visualize their results (or even “play in our heads”) and predict what the data will look like at the end:
const rawValue = '42';
const baseValue = createBaseValue(rawValue);
const quoteValue = calculateQuoteValue(currentRate, baseValue);
// RawValue -> BaseValue -> QuoteValue
It is easy to compose such processes into more complex functions:
function workflow(rawValue, exchangeRates) {
const baseValue = createBaseValue(rawValue);
const currentRate = lookupRate(exchangeRates);
const quoteValue = calculateQuoteValue(currentRate, baseValue);
return quoteValue;
}
...But the whole transformation remains understandable and testable, because all its steps are explicit.
In this approach, we don't change the state around the function, but instead return an updated data, so the final result cannot be influenced from the outside. This way we eliminate the influence of side-effects on the result.
In the future, we will use functional composition to assemble use cases and extract the similar (or generalized) actions into separate functions.
At this stage, however, it's too early to make any generalizations. First we should look at how the data actually behaves: what data changes at the same, how often it happens, and for what reasons. Once we discover behavior patterns, we can conclude if we need to generalize anything.
Next Time
In this post we designed the domain model of the application and laid the groundwork for future use cases.
Next time we'll design and implement these use cases, describe specifications for how the outside world should communicate with the application, and talk about dependencies inside and outside the application.
Sources and References
Links to books, articles, and other materials I mentioned in this post.
Books
- Code That Fits in Your Head by Mark Seemann
- Domain-Driven Design by Eric Evans
- Domain Modelling Made Functional by Scott Wlaschin
- Unit Testing: Principles, Practices, and Patterns by Vladimir Khorikov
Domain Modelling
- Data consistency
- Domain-driven design
- Domain model
- Evans classification
- Invariants in computer science
- Ubiquitous language
Architecture, Contracts, and Patterns
- DDD, Hexagonal, Onion, Clean, CQRS, … How I put it all together
- Design by Contract
- Factory Method
- More functional pits of success
- Ports & adapters architecture
TypeScript & Static Types
- Designing with types: Making illegal states unrepresentable
- Functional types
- Type aliases
- Type branding
- Static typing as a design tool
Functional Programming
- Decoupling decisions from effects
- A fistful of monads
- Function composition
- Pure function
- Referential transparency
Testing
- Arrange / act / assert
- Functional design is intrinsically testable
- Happy path
- TDD: What, how, and why
- Test-induced design damage
- Vitest API reference
Methodologies & Processes
- Copypaste in code
- CRUD
- “Design first, then build”: let’s bury this myth forevermore
- How to refactor documentation and processes
- The knowns and unknowns framework for design thinking
- Signal to noise ratio
P.S. This post was originally published at bespoyasov.me. Subscribe to my blog to read posts like this earlier!
Posted on July 18, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related


