
Luiz Bernardo
Posted on December 8, 2021
No dia 02 de dezembro fiz uma talk no HashiTalks sobre esse tema e achei legal transformar essa palestra em post, então vamos lá.
Nesse post não irei abordar sobre IAC ou sobre o básico do Terraform, mas será um post introdutório sobre teste em infraestrutura com o Terraform.
O que é teste?
O teste de software é uma maneira de avaliar a qualidade do software
e reduzir o risco de falha do software em operação.
Para qualquer projeto, os objetivos do teste podem incluir informações para:
• Evitar defeitos, avaliar os produtos de trabalho, como requisitos, histórias de usuários,
modelagem e código;
• Verificar se todos os requisitos especificados foram cumpridos;
• Verificar se o objeto de teste está completo e validar se funciona como os usuários e
stakeholders esperam;
• Criar confiança no nível de qualidade do objeto de teste;
• Encontrar defeitos e falhas reduz o nível de risco de qualidade inadequada do software;
• Fornecer informações suficientes aos stakeholders para que tomem decisões especialmente
em relação ao nível de qualidade do objeto de teste;
• Cumprir os requisitos ou normas contratuais, legais ou regulamentares, ou verificar a
conformidade do objeto de teste com esses requisitos ou normas.
Por que o teste é necessário?
Testes rigorosos de componentes e sistemas e sua documentação associada podem ajudar a reduzir o risco de falhas durante a operação. Quando defeitos são detectados e posteriormente corrigidos, há contribuição para a qualidade dos componentes ou sistemas. Além disso, o teste de software também é necessário para atender aos requisitos contratuais ou legais ou aos padrões específicos do setor.
Por que testar a infraestrutura?
De forma simples e direta, testamos infraestrutura para garantir a Idempotência e imutabilidade da mesma.
Beleza, mas o que seria isso?
Idempotência:
É a propriedade que algumas operações têm de poderem ser aplicadas várias vezes sem que o valor do resultado se altere após a aplicação inicial.
Quando você está criando uma infraestrutura nova com um pool de recursos conhecidos, provavelmente você poderá utilizar uma receita de criação e espera que o resultado seja o mesmo de quando você executou anteriormente.
A vários pontos de falha que podem influenciar negativamente a criação de uma infraestrutura cloud como exemplo seus recursos podem ter atingido a cota atual de provisionamento da sua conta ou suas credenciais para aquele tipo de provisionamento possam ser revogadas.
Imutabilidade:
Na programação, usamos variáveis para significar objetos cujo estado pode mudar com o tempo. Um valor imutável é exatamente o oposto, depois de criado, ele nunca pode mudar.
Pensando em um cenário simples onde você possui um servidor e uma rede virtual você espera que essa infraestrutura permaneça a mesma até o fim dos tempos ou houver uma necessidade de mudar certo?
Caso você tenha usado boas práticas e criado essa infraestrutura como código, provavelmente você retornará ao código inicial e fará as mudanças necessárias, mas se você simplesmente aplicar a mudança provavelmente o seu cliente sofrerá o impacto.
Uma prática para contornar esse dilema é criar uma infraestrutura e não alterar a infraestrutura atual.
Você pode utilizar várias estratégias para transferir a carga de trabalho para a nova infraestrutura como blue green deploy, canary deployment ou simplesmente uma troca no DNS.
Ao concluir você pode simplesmente destruir a infraestrutura antiga. É uma boa prática manter a infraestrutura imutável e descartável.
Tipos de teste
Por padrão acabamos agrupando os tipos de testes em testes manuais e testes automatizados.
De forma prática, os testes manuais são aqueles na qual um humano precisa ser o gatilho para execução e os testes automatizados não a necessidade desse humaninho.
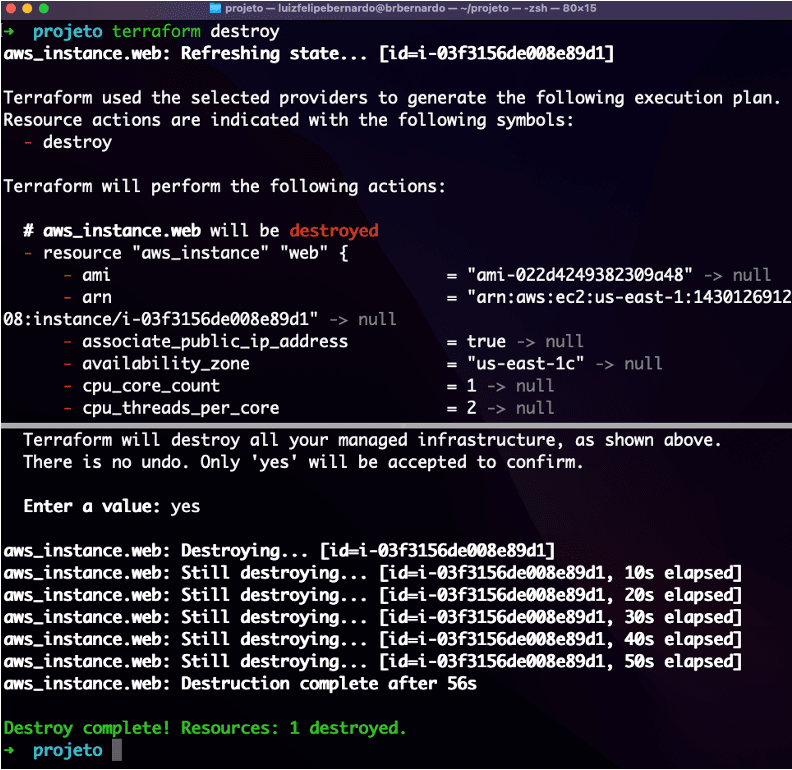
Como exemplo de uma implementação de testes automatizado você pode incluir no seu gitflow uma etapa que chama os comandos de teste do terraform: terraform plan, apply e destroy (vou explicar eles em seguida).
$ terraform plan
O terraform plan cria um plano de execução. Por padrão, a criação de um plano consiste em:
- Ler o estado atual de quaisquer objetos remotos já existentes para se certificar de que o estado do Terraform está atualizado.
- Comparando a configuração atual com o estado anterior e observando quaisquer diferenças.
- Propor um conjunto de ações de mudança que devem, se aplicadas, fazer com que os objetos remotos correspondam à configuração.
O comando plan sozinho não executará realmente as alterações propostas e, portanto, você pode usar este comando para verificar se as alterações propostas correspondem ao que você esperava antes de aplicar as alterações ou compartilhar suas alterações com sua equipe para uma revisão mais ampla.

Se o Terraform detectar que nenhuma mudança é necessária nas instâncias de recursos ou nos valores de saída do módulo raiz, terraform planele relatará que nenhuma ação precisa ser executada.
Caso você esteja utilizando armazenamento de estado remoto ou o terraform plan precisará ter acesso ao repositório ou ocorrerá um erro na execução.
Outro ponto importante sobre isso e que você precisa ter um usuário iam configurado para executar qualquer um dos comandos de provisionamento do Terraform no provider que estiver configurado no resource.
Por fim, é uma boa prática armazenar o plano em um arquivo para executar as mudanças planejadas com o terraform apply, e para alguns outros comandos do Terraform que podem funcionar com arquivos de plano salvos.
Utilize a flag -out=FILENAME para isso.
O Terraform permitirá qualquer nome de arquivo para o arquivo de plano, mas uma convenção típica é nomeá-lo .tfplan. Não nomeie o arquivo com um sufixo que o Terraform reconheça como outro formato de arquivo; se você usar um .tfsufixo, o Terraform tentará interpretar o arquivo como um arquivo de origem de configuração, o que causará erros de sintaxe para os comandos subsequentes.
O arquivo gerado não é em qualquer formato padrão destinados ao consumo por outros softwares, mas o arquivo não contém sua configuração completa, todos os valores associados a mudanças planejadas, e todas as opções de plano, incluindo as variáveis de entrada. Se o seu plano incluir qualquer tipo de dado sensível, mesmo se obscurecido na saída do terminal do Terraform, ele será salvo em texto não criptografado no arquivo do plano. Portanto, você deve tratar todos os arquivos de plano salvos como artefatos potencialmente sensíveis.
$ terraform apply
O terraform apply e o comando que executa as ações propostas em um plano do Terraform.
A maneira mais direta de usar terraform apply é executá-lo sem nenhum argumento, caso em que criará automaticamente um plano de execução (como se você tivesse executado terraform plan) e solicitará que você aprove esse plano antes de executar as ações indicadas.
Outra maneira de usar terraform apply é passar para ele o nome de arquivo de um arquivo de plano salvo que você criou anteriormente terraform plan -out=..., caso em que o Terraform aplicará as alterações no plano sem nenhum prompt de confirmação. Este fluxo de trabalho de duas etapas é destinado principalmente para a execução do Terraform na automação.

$ terraform destroy
O terraform destroy comando é uma maneira conveniente de destruir todos os objetos remotos gerenciados por uma configuração particular do Terraform.
Embora normalmente você não queira destruir objetos de longa duração em um ambiente de produção, o Terraform às vezes é usado para gerenciar infraestrutura efêmera para fins de desenvolvimento, caso em que você pode usar terraform destroy para limpar convenientemente todos esses objetos temporários quando terminar de trabalhar.
O terraform destroy utiliza o plano atual para desfazer tudo o que foi proposto nele de forma inversa ao fluxo de criação para não gerar erros de dependência.
Beleza, vamos evoluir um pouco mais os conceitos de teste antes de darmos andamento ao automatização do teste da infraestrutura.
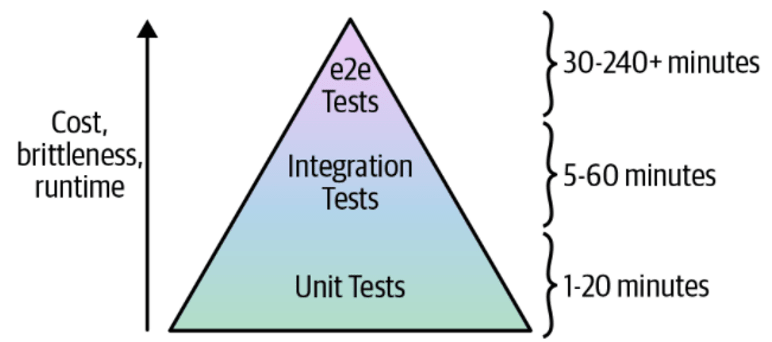
Pirâmide de Teste
Como estrategia de teste podemos agrupar em teste de unidade, teste de integração e teste ponta a ponta (end-to-end), vou explicar eles ao decorrer desse post.
A ideia da pirâmide de teste é que você normalmente deve ter como objetivo um grande número de testes de unidade (a parte inferior da pirâmide), um número menor de testes de integração (o meio da pirâmide) e um número ainda menor de testes completos (o topo da pirâmide). Isso ocorre porque, conforme você sobe na pirâmide, o custo e a complexidade de escrever os testes, a fragilidade dos testes e o tempo de execução dos testes aumentam.
Teste unitário
Testes unitários são aplicados a menor unidade de código.
Por princípios a menor unidade de código e uma classe.
No Terraform o modulo representa uma classe.
Isso significa que a estratégia básica para escrever testes de unidade para o Terraform é:
- Crie um módulo autônomo genérico.
- Crie um exemplo fácil de implementar para esse módulo
- Execute
terraform applypara implantar o exemplo em um ambiente real. - Valide se o que você acabou de implantar funciona conforme o esperado. Esta etapa é específica para o tipo de infraestrutura que você está testando: por exemplo, para um ALB, você o validaria enviando uma solicitação HTTP e verificando se recebeu de volta a resposta esperada.
- Execute
terraform destroyno final do teste para limpar.
No https://registry.terraform.io/ existem vários módulos abertos registrados para utilização e um dos requisitos para você submeter e registrar um módulo e existir um exemplo fácil de implementar o módulo.
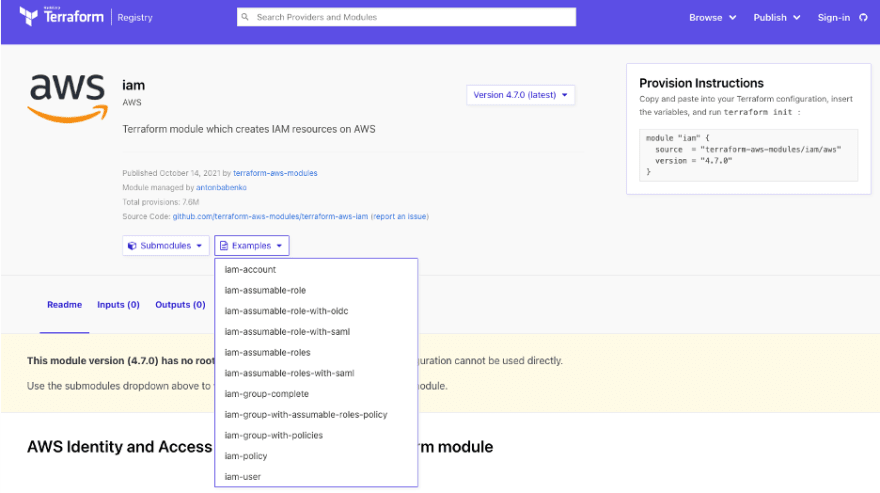
Você pode usar os exemplos que estão no próprio módulo para testar a implementação do seu código de uma forma segura e destruí-lo em seguida.
Essa é a estratégia mais utilizada em testes de infraestrutura, ao menos comigo =D
Teste de integração
Pense no seguinte cenário: Você precisa construir automaticamente pipelines CI/CD e clusters Amazon ECS para microsserviços.
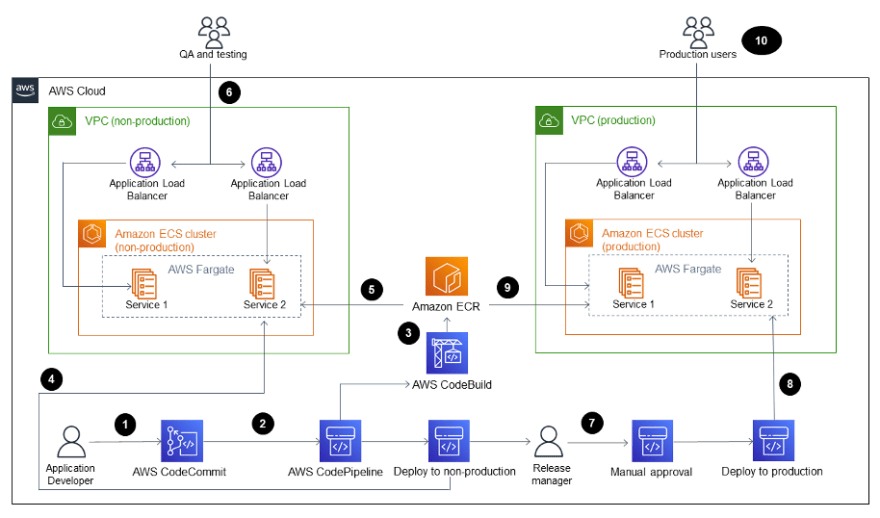
Teste de integração e um fluxo de estágios de testes passo a passo.

Teste end-to-end
Pense no objetivo: Você precisa construir automaticamente pipelines CI/CD e clusters Amazon ECS para microsserviços.
Teste end-to-end e um teste integrado para validar se você alcançou seu objetivo.
Na verdade, quando você chega ao topo da pirâmide de teste, a execução de testes para implantar uma arquitetura complicada do zero torna-se insustentável por dois motivos principais:
Muito devagar
Implementar toda a sua arquitetura do zero e, em seguida, removê-la novamente pode levar muito tempo: na ordem de várias horas. As suítes de teste que demoram tanto fornecem relativamente pouco valor porque o ciclo de feedback é simplesmente muito lento. Você provavelmente executaria esse conjunto de testes apenas durante a noite, o que significa que pela manhã você receberá um relatório sobre uma falha de teste, investigará por um tempo, enviará uma correção e esperará até o dia seguinte para ver se funcionou. Isso limita você a cerca de uma tentativa de correção de bug por dia. Nesses tipos de situações, o que realmente acontece é que os desenvolvedores começam a culpar os outros pelas falhas de teste, convencendo a gerência a implantar apesar das falhas de teste e, eventualmente, ignorando as falhas de teste inteiramente.
Muito quebradiço
Conforme mencionado na seção anterior, o mundo da infraestrutura é confuso. Conforme a quantidade de infraestrutura que você está implantando aumenta, as chances de um problema intermitente e instável também aumentam. Por exemplo, suponha que um único recurso (por exemplo, uma instância EC2) tenha uma chance em mil (0,1%) de falhar devido a um erro intermitente (as taxas de falha reais no mundo DevOps são provavelmente mais altas) . Isso significa que a probabilidade de um teste que implanta um único recurso ser executado sem erros intermitentes é de 99,9%. Então, que tal um teste que implanta dois recursos? Para que o teste seja bem-sucedido, você precisa de ambos os recursos para implantar sem erros intermitentes e, para calcular essas probabilidades, multiplique as probabilidades: 99.9%×99.9%=99.8%. Com três recursos, as chances são99.9%×99.9%×99.9%=99.7%. Com N recursos, a fórmula é 99.9%N.
Portanto, agora vamos considerar diferentes tipos de testes automatizados. Se você tivesse um teste de unidade de um único módulo que implantou, digamos, 20 recursos, as chances de sucesso são 99.9%20=98.0%. Isso significa que 2 execuções de teste em 100 falharão; se você adicionar algumas tentativas, poderá tornar esses testes bastante confiáveis. Agora, suponha que você tenha feito um teste de integração de 3 módulos que implementou 60 recursos. Agora, as chances de sucesso são 99.9%60=94.1%. Novamente, com lógica de repetição suficiente, você normalmente pode tornar esses testes estáveis o suficiente para serem úteis. Então, o que acontece se você quiser escrever um teste de ponta a ponta que implementa toda a sua infraestrutura, que consiste em 30 módulos ou cerca de 600 recursos? As chances de sucesso são99.9%600=54.9%. Isso significa que quase metade das execuções de teste falhará por motivos transitórios!
Você será capaz de lidar com alguns desses erros com novas tentativas, mas rapidamente se transforma em um jogo sem fim de whack-a-mole. Você adicionou uma nova tentativa para um tempo limite de handshake TLS, apenas para ser atingido por um tempo de inatividade do repo APT em seu modelo do Packer; você adiciona novas tentativas à compilação do Packer, apenas para que a compilação falhar devido a um bug de consistência eventual do Terraform; da mesma maneira que você está aplicando o band-aid, a compilação falha devido a uma breve interrupção do GitHub. E como os testes de ponta a ponta demoram tanto, você tem apenas uma tentativa, talvez duas, por dia para corrigir esses problemas.
Na prática, muito poucas empresas com infraestrutura complicada executam testes de ponta a ponta que implantam tudo do zero . Em vez disso, a estratégia de teste mais comum para testes ponta a ponta funciona da seguinte maneira:
- Uma vez, você paga o custo de implantação de um ambiente persistente semelhante à produção, chamado “teste”, e deixa esse ambiente em execução.
- Cada vez que alguém faz uma alteração em sua infraestrutura, o teste de ponta a ponta faz o seguinte:
- Aplica a mudança de infraestrutura ao ambiente de teste.
- Executa validações no ambiente de teste (por exemplo, use Selenium para testar seu código da perspectiva do usuário final) para certificar-se de que tudo está funcionando.
Ao alterar sua estratégia de teste de ponta a ponta para aplicar apenas mudanças incrementais, você está reduzindo o número de recursos que estão sendo implantados no momento do teste de várias centenas para apenas um punhado, de modo que esses testes sejam mais rápidos e menos frágeis.
Além disso, essa abordagem de teste de ponta a ponta imita mais de perto como você implantará essas mudanças na produção. Afinal, não é como se você destruísse e aumentasse seu ambiente de produção do zero para implementar cada alteração. Em vez disso, você aplica cada alteração de forma incremental, portanto, esse estilo de teste de ponta a ponta oferece uma grande vantagem: você pode testar não apenas se sua infraestrutura funciona corretamente, mas se o processo de implantação dessa infraestrutura também funciona corretamente.
E isso galerinha, se quiser assistir a live é só clicar aqui
Vlw Flw!
Posted on December 8, 2021
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.