Streamlining System Monitoring and Alerting with Prometheus

Benny Yang
Posted on March 14, 2024

Prometheus stands as a pivotal player in the monitoring and alerting landscape.
Its core strength lies in its ability to efficiently collect and query time-series data in real-time, making it indispensable for monitoring system health, performance metrics and alerting on anomalies.
Prometheus Alert Rules
Prometheus allows us to define alert rules in a dedicated .yml file based on PromQL expressions and dynamically import them in rule_files section in the configuration file, it supports wildcard directories to implement multiple files simultaneously.
// Prometheus.yml
# my global config
global:
scrape_interval: 60s # Set the scrape interval to every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- '/etc/prometheus/rules/*.yml'
# A scrape configuration containing exactly one endpoint to scrape:
scrape_configs:
With beyond configuration, the rules will be evaluated every 15 seconds, let's move on to the rule files :
groups:
- name: b2ac9e71-589e-494c-af38-81760d4eeab9_..._rules
rules:
- alert: temp_high_warm_laser/101
expr:
device_temperature_celsius{device="laser/101"} >= 30 and
dfost_pu_luminis_device_temperature_celsius{device="laser/101"} < 80
for: 1m
labels:
severity: temp_high_warm
deviceId: test-device
type: temperature
operatingRange: 25-30
value: "{{ $value }}"
annotations:
summary: Device temperature is between 30°C and 80°C
description: "Device temperature is between 30°C and 80°C"
Let's breakdown each field one by one!
-
Groups: A collection of rules. Groups help organize rules by their purpose or by the services they monitor. -
Rules: Defines the individual alerting or recording rules within a group. Each rule specifies conditions under which alerts should be fired or metrics should be recorded. -
Alert: Name of the alert.' -
for: The duration that the expr condition must be true for firing the alert to alert manager. -
Expr: The PromQL expression that defines the condition triggering the alert. -
Labels: Key-Value attached to the alert. Are used to categorize or add metadata with alerts, such as severity levels, alert types and actual metric value at the moment. -
Annotations: Descriptive information attached to alerts that can include additional details or instructions such as summary and description.
Once the rule files are configured, locate them in the directory we've specified in Prometheus.yml, let's initiate the Prometheus server using docker compose
// docker-compose.yml
prometheus:
image: prom/prometheus:latest
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
- ~/prometheus/rules:/etc/prometheus/rules
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--web.enable-remote-write-receiver'
- '--web.enable-lifecycle'
- '--storage.tsdb.retention.size=4GB'
ports:
- 9090:9090
networks:
- prom-net
restart: always
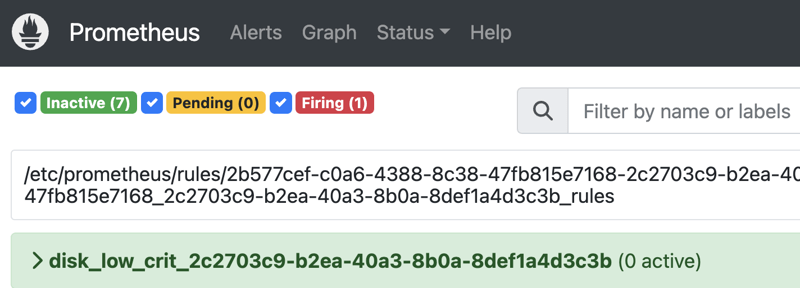
Now visit the prometheus dashboard on port 9090, alert rules should appear under alert tab if they were correctly implemented.
Remember whenever a rule was added or modified, we have to actively reload the prometheus server, the configuration reload is triggered by sending a SIGHUP to the Prometheus process or sending a HTTP POST request to the /-/reload endpoint (that's why the --web.enable-lifecycle flag is enabled).
Alertmanager & Pushgateway
After successfully configured our alert rule, it's time to trigger an actual alert from it, that's when Prometheus Alertmanager and Pushgateway come in.
Alertmanager :
Alertmanager handles the next steps for alerts, deduplicating, grouping, and routing these alerts to the correct receivers like email, Slack, or webhooks.
Pushgateway :
PushGateway offers a solution for supporting Prometheus metrics from batch jobs or ephemeral jobs that cannot be scraped. It acts as an intermediary service allowing these jobs to push their metrics to PushGateway, which can be scraped by Prometheus.
It allows us to actively push custom metrics by curling endpoint which is useful for testing every kind of threshold scenario before Prometheus could actually scrape the real data.
Configuration & Test Steps
Step 1: Configure alertmanager.yml & prometheus.yml
// alertmanager.yml
global:
resolve_timeout: 5m //After this time passes, declare as resolve
route: // Define the routing logic for each alert
group_by: ['alertname', 'instance']
group_wait: 10s // The time to wait before sending the first notification for a new group of alerts
group_interval: 10s // After the first notification for a group of alerts, this is the wait time before sending a subsequent notification for that group
repeat_interval: 1m // How long Alertmanager waits before sending out repeat notifications for a group of alerts that continues to be active (firing).
receiver: 'webhook-receiver' // Name of receiver, defined in receivers section
routes:
- match: // Defines the condition of triggering webhook
severity: 'disk_low_crit'
receiver: 'webhook-receiver'
receivers:
- name: 'webhook-receiver'
webhook_configs: // Webhook server endpoint
- url: 'http://10.0.0.1:3000'
send_resolved: true
// prometheus.yml add alertmanager config
# my global config
global:
scrape_interval: 60s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 60s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- '/etc/prometheus/rules/*.yml'
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
static_configs:
- targets: ["localhost:9090"]
Step 2: Establish both instances with docker-compose, rebuild prometheus instance with new config as well
// docker-compose.yml
prometheus:
image: prom/prometheus:latest
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
- ~/prometheus/rules:/etc/prometheus/rules
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--web.enable-remote-write-receiver'
- '--web.enable-lifecycle'
- '--storage.tsdb.retention.size=4GB'
ports:
- 9090:9090
networks:
- prom-net
restart: always
alertmanager:
image: prom/alertmanager:latest
volumes:
- ./alertmanager.yml:/etc/alertmanager/alertmanager.yml
command:
- '--config.file=/etc/alertmanager/alertmanager.yml'
- '--storage.path=/alertmanager'
ports:
- '9093:9093'
networks:
- prom-net
pushgateway:
image: prom/pushgateway
ports:
- "9091:9091"
networks:
- prom-net
Step 3: Pushing custom metrics to Pushgateway by running this command, in this case we're passing a temperature metric with value 75
echo "device_temperature_celsius{device=\"laser/101\", SN=\"18400138\", deviceId=\"3764b164-01e7-4940-b9e9-9cf26604534a\", instance=\"localhost:59900\", job=\"sysctl\"} 75" | curl --data-binary @- http://localhost:9091/metrics/job/temperature_monitoring
Step 4: Check Pushgateway dashboard on port 9091 to make sure if the metric was pushed
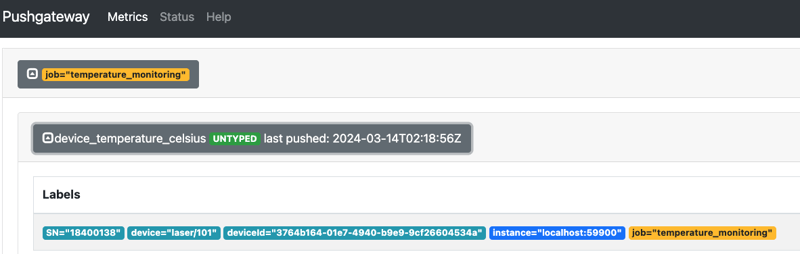
Step 5: Check if the alert status changed to active on Prometheus dashboard (9090), it should meet the threshold of the alert rule we just defined
![]()
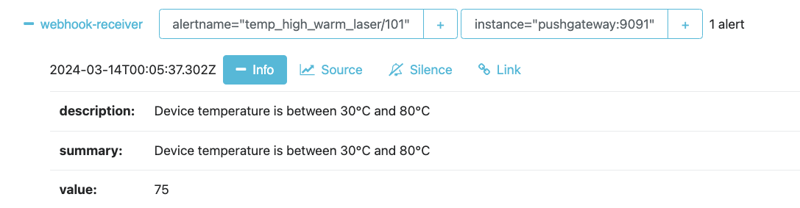
Step 6: Check the alertmanager instance dashboard(9093) to make sure it receive the alert
Reference:
Prometheus Docs
Prometheus git book
Thanks for reading !!!
Posted on March 14, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related