Hybrid Machine Learning | AWS Whitepaper Summary

Marwa Talaat
Posted on November 13, 2021

This article aims to discuss the outline, known considerations, design patterns, and solutions that customers should know when considering integrations between local compute and the AWS cloud across the machine learning lifecycle.
AWS purpose hybrid ML patterns as an intermediate step in their cloud and ML journey. The patterns involve a minimum of two compute environments, typically local compute resources such as personal laptops or corporate data centers, and the cloud.
This article is intended for individuals who already have a baseline understanding of machine learning, in addition to Amazon SageMaker.
Stage One: Basics
Developing technology that applies machine learning is challenging since it depends on data. Datasets vary from bytes to petabytes, objects to file systems, text to vision, tables to logs. Software frameworks supporting machine learning models evolve rapidly, undergoing potentially major changes multiple times a year, if not quarter or month. Nowadays, data science projects require different skill levels in team, from business stakeholders, quality and availability of datasets and models, and customer adoption
Companies who adopt a cloud-native approach realize its value of compute capacity with the needs of their business, technical resources to focus on building features, rather than taking on the burden of managing and maintaining their own underlying infrastructure. But for those companies born before the cloud and even for newer companies founded more recently, potentially those that made an informed decision to build on-premises, how can they realize the value of newly launched cloud services when the early requirements that were once infeasible on the cloud are now within reach?
For customers who want to integrate the cloud with existing on-premises ML, AWS propose a series of tenets to guide our discussion: -
- Seamless management experience: Customers need end-to-end ML across multiple compute environments, limiting the burden of administrative while successfully operate complex tasks.
- Tunable latency: The customers enjoy using applications that respond within the timelines of their moment-to-moment expectations, and designers of these applications understand the criticality of time-bound SLA’s. Engineers want to work with ML models that can respond to an app’s request within in milliseconds, regardless of the hosted. While not every customer requires response times at low latency levels, but faster is better.
- Fast time-to-value: Customers expect solutions to be easy to use, with simple interfaces, and not requiring significant amounts of platform-specific engineering to execute a task.
- Flexible: Customers need compute paradigms that provide the flexibility their business demands. ML applications may need to serve real-time responses to billions of users worldwide. Service providers should anticipate for deploying all environments.
- Low Cost: Customers want transparency in their cost structure, they need to see a clear economic advantage to computing in the cloud relative to developing locally. Service providers need to anticipate this and compete on cost with respect to local compute options
- End in the cloud: If there was any doubt that cloud computing is the way of the future, the global pandemic of 2020 put that doubt to rest. AWS also call out the final state of that design, helping customers understand which cloud technologies to leverage in the long runleverage in the long run.
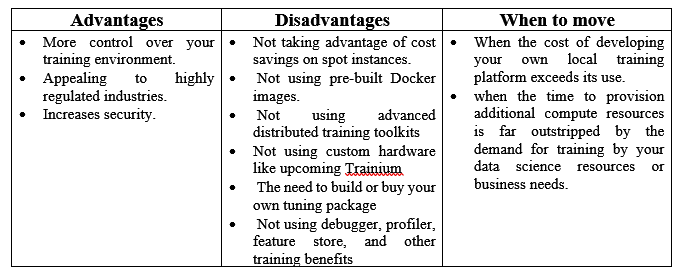
There are two very different approaches to hosting – one type of pattern trains in the cloud with the intention of hosting the model itself on-premises, while another hosts the model in the cloud to applications deployed on-premises. Finally, a key pillar in applying these patterns is security.
What is hybrid?
At AWS, we look at “hybrid” capabilities as those that touch the cloud in some capacity, while also touching local compute resources. Local compute such as laptops hosting Jupyter notebooks and Python scripts, HDFS clusters storing terabytes of data, AWS Outposts stored on-premises, or AWS Outposts stored on-premises.
The hybrid architectures are having a minimum of two compute environments, what we will call “primary” and “secondary” environments. The primary environment as where the workload begins, and secondary environment is where the workload ends.
Depending on your case for instance if you are packaging up a model locally to deploy to the cloud, you might call your local laptop “primary” and your cloud environment “secondary.”. However, if you are training on cloud and want to deploy locally, you might call your cloud environment “primary” and your local environment “secondary.”
What hybrid is not?
There are some container-specific tools that provide a “run anywhere” experience, such as EKS and ECS. In those contexts, we will lean into prescriptive guidance for building, training, and deploying machine learning models with these services.
Stage Two: Hybrid patterns for development
Development refers to the phase in machine learning when customers are iteratively building models. This may or may not include exploratory data analysis, deep learning model development and compilation, software package installation and management, Jupyter kernels, visualization, Docker image building, and Python-driven data manipulation.
There are two major options for hybrid development that customer can apply one or both. Laptop and desktop personal computers. Self-managed local servers utilizing specialized GPUs, colocations, self-managed racks, or corporate data centers.
Develop on personal computers, to train and host in the cloud
Customers can use local development environments, such as PyCharm or Jupyter installations on their laptops or personal computer, and then connect to the cloud via AWS Identity and Access Management (IAM) permissions and interface with AWS service APIs through the AWS CLI or an AWS SDK (ex boto3). Having connected to the cloud, customers can execute training jobs and/or deploy resources.
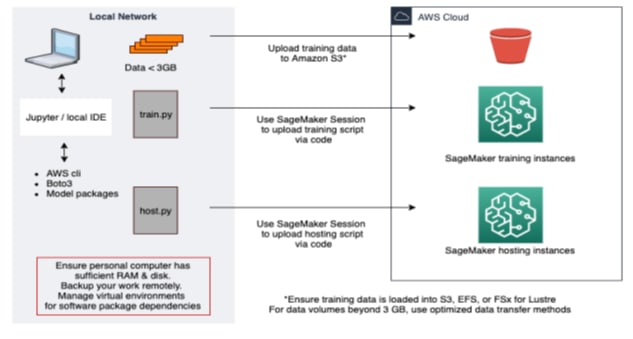

Develop on local servers, to train and host in the cloud


Stage Three: Training
Hybrid patterns for training
Hybrid pattern for training comes down to one of two paths. Either you train locally and deploy on the cloud. Or the data sitting on local resources and want to select from that to move into the cloud to train.
Training locally, to deploy in the cloud
During enterprise migrations, training locally may be advantageous as a first step to develop a model. There are two key actions here. First, if you are training locally then you will need to acquire the compute capacity to train a model and think about size of dataset, and models that you want to use. When you are training on-premises, you need to plan for that well in advance and acquire the compute resources ahead of time.
After your model is trained, there are two common approaches for packaging and hosting it in the cloud. One Simple path is Docker, using a Docker file you can build your own custom image that hosts your inference script, model artifact, and packages. Register this image in the Elastic Container Registry (ECR) and point to it from your SageMaker estimator.
Another option is using pre-built containers within the SageMaker Python SDK. Bring your inference script and custom packages, upload your model artifact to Amazon S3, and import an estimator for your framework of choice.
In the following diagram, we outline how to do this from your laptop. The pattern is similar for doing the same from an enterprise data center with servers, as outlined above.

How to monitor your model in the cloud?
A key feature for hosting is model monitor, or the ability to detect data, bias, feature, and model quality drift. It is ability to capture data hitting your real-time endpoint, and programmatically compare this to your training data.
Enabling model monitor is easy in SageMaker. Upload your training data to an Amazon S3 bucket and use our pre-built image to learn the upper and lower bounds on your training data. This job uses Amazon Deequ to perform “unit testing for data,” and you will receive a JSON file with the upper and lower statistically recommended bounds for each feature. You can modify these thresholds. After confirming your thresholds, schedule monitoring jobs in your production environment. The jobs run automatically, comparing your captured inference requests in Amazon S3 with your thresholds.
CloudWatch will alert you when your inference data is outside of your pre-determined thresholds, and you can use those alerts to trigger a re-training pipeline.
How to handle retraining / retuning?
SageMaker makes train and tuning jobs easy to manage, because all you need to bring is your training script and dataset. Ensure your new dataset is loaded into an Amazon S3 bucket, or other supported data source.
Once you have defined a training estimator, it is trivial to extend this to support hyperparameter tuning. Define your tuning job configuration using tuning best practices and execute. Having defined a tuning job, you can automate this in a variety of ways. While AWS Lambda may seem compelling upfront, to use the SageMaker Python SDK (and not boto3) with Lambda, sadly you need to create an executable layer to upload within your function.
You may consider SageMaker Pipelines, an MLOps framework that uses your SageMaker Python SDK job constructs as argument and creates a step-driven framework to execute your entire pipeline.
How to serve thousands of models in the cloud at low cost?
You may consider Multi-model endpoints give you the ability to serve thousands of models from a single endpoint, invoking the name of the model when calling predict.
Create the multi-model endpoint, pointing to Amazon S3, and load your model artifacts into the bucket. Invoke the endpoint from your client application, (eg. with AWS Lambda), and dynamically select the right model in your application. It allows to host up to 5 containers on a single SageMaker endpoint, invoking the endpoint with the name of the model you want to use.
Storing data locally, to train and deploy in the cloud
when and how do I move my data to the cloud?
Schedule data transfer jobs with AWS DataSync
It is a data transfer service that simplifies, automates, and accelerates moving data between on-premises storage systems and AWS storage services, as well as between AWS storage services.
- It can be easily moved petabytes of data from your local on-premises servers up to the AWS cloud.
- It can be deployed can easily move petabytes of data from your local on-premises servers up to the AWS cloud.
- It can be connected to your local NFS resources and deploy directly into Amazon S3 buckets or EFS volumes, or both.
Migrating from Local HDFS
As customers explore migrating data stored in local HDFS clusters, typically they find themselves somewhere between two extremes.
On the other, you might wholly embrace HDFS as your center and move towards hosting it within a managed service, Amazon Elastic Map Reduce (EMR).
Best practices
• Use Amazon S3 intelligent tiering for objects over 128 KB
• Use multiple AWS accounts, and connect them with Organizations
• Set billing alerts
• Enable SSO with your current Active Directory provider
• Turn on Studio!

Develop in the cloud while connecting to data hosted on-premises
Customers who see the value of outsourcing management and upkeep of their enterprise ML development platforms, i.e. through using managed services like Amazon SageMaker, can still connect in to their on-premises data store at the beginning and middle phases of their enterprise migration.

Data Wrangler & Snowflake
Data Wrangler enables customers to browse and access data stores across Amazon S3, Amazon 3rd Athena, Amazon Redshift, and party data warehouses like Snowflake. This hybrid ML patten provides customers the ability to develop in the cloud while accessing data stored on premises, as organizations develop their migration plans.
Train in the cloud, to deploy ML models on-premises
You can download whatever type of model artifact you need, but if you are deploying on-premises, you need to develop and host your own local web server.

This scenario builds on your previous experience developing and training in the cloud, with the key difference of exporting your model artifact to deploy locally. AWS recommends using dev and/or test endpoints in the cloud to give your teams the maximum potential to develop the best models they can.
If you are using a managed deep learning container, also known as “script mode,” for training and tuning, but you still want to deploy that model locally, plan on building your own image with your preferred software version, scanning, maintaining, and patching this over time. If you are using your own image, you will need to own updating that image as the software version, such as TensorFlow. Note that the best practice is to decouple hosting your ML model from hosting your application.
As models grow and shrink in size, hitting potentially billions of parameters and hundreds of gigs in byte size, or shrinking down to hundreds of parameters and staying under a few MB in size, you want the elasticity of the cloud to seamlessly map the state-of-the-art model to an efficient hardware choice.

Stage Four: Deployment
Monitor ML models deployed on-premises with SageMaker Edge Manager
Customers can train ML models in the cloud, deploy these on-premises, and monitor and update them in the cloud using SageMaker Edge Manager. SageMaker Edge Manage makes it easy for customers to manage ML models deployed on Windows, Linux, or ARM-based compute environments.
While customers do still need to provision, manage, procure, and physically secure the local compute environments in this pattern, Edge Manage simplifies the monitoring and updating of these models by bringing the control plane up to the cloud. However, you can bring your own monitoring algorithm to the service and trigger retraining pipelines as necessary, using the service the redeploy that model back down to the local device. This is particularly common for technology companies developing models for personal computers, such as laptops and desktops.
Hybrid patterns for deployment
Hybrid ML patterns around deployment can be interesting and complex. Choosing the “best” local deployment option has a lot of variety. You want to think about where your customers sit geographically, then you want to get your solution as close to them as you can. You want to balance speed with cost, cutting-edge solutions with ease of deployment and managing.
In this section will discuss the architecture for hosting an ML model via SageMaker in an AWS region, serving responses to requests from applications hosted on-premises. After that we’ll look at additional patterns for hosting ML models via Lambda at the Edge, Outposts, Local Zones, and Wavelength.
Serve models in the cloud to applications hosted on-premises

The most common use case for a hybrid pattern like this is enterprise migrations. You might have a data science team with tens of models, if not more than one hundred, ready to deploy via the cloud, while your application team is still refactoring their code to host on cloud-native services.

Host ML Models with Lambda at Edge to applications on-premises

This pattern takes advantage of a key capability of the AWS global network – the content delivery network known as Amazon CloudFront. Deploying content to CloudFront is easy, customers can package up code via AWS Lambda and set it to trigger from their CloudFront distribution.
What’s elegant about this approach is that CloudFront manages which of the 230+ points of presence will execute your function. Once you’ve set your Lambda function to trigger off CloudFront, you’re telling the service to replicate that function across all available regions and points of presence. This can take up to 8 minutes to replicate and become available.
This is a huge value-add for global companies looking at improving their digital customer experience worldwide.

AWS Local Zones
Local Zones are a way to extend your cloud resources to physical locations that are geographically closer to your customers. You can deploy ML models via ECS or EKS to serve inference with ultra- low latency near your customers, using AWS Local Zones.
AWS Wavelength
Wavelength is ideal when you are solving applications around mobile 5G devices, either anticipating network drop-offs or serving uses real-time model inference results. Wavelength provides ultra-low latency to 5G devices, and you can deploy ML models to this service via ECS or EKS. Wavelength embeds storage and compute inside the telecom providers, which is the actual 5G network.
Training with a 3rd party SaaS provider to host in the cloud
There are a lot of great SaaS providers for ML out there in the market today, like H20, DataRobot, Databricks, SAS, and others. 3rd Hosting a model in Amazon SageMaker that was trained from a party SAAS provider is easy. Ensure your provider allows export of proprietary software frameworks, such as with jars, bundles, images, etc. Follow steps to create a Docker file usingthat software framework, port into the Elastic Container Registry, and host on SageMaker.
Keep in mind that providers will have different ways of handling software, in particular images and image versions.
Control plane patterns for hybrid ML
AWS uses the concept of a “control plane,” or set of features dedicated to operations and management, while keeping this distinct from the “data plane,” or the datasets, containers, software, and compute environments.
Customers’ need it for operationalizing ML workloads are as varied and diverse as the businesses they exist within. Today it is not feasible for a single workflow orchestration tool to solve every problem, so most customers standardize on one workflow paradigm while keeping options open for others that may better solve given use cases. One such common control plane is Kubeflow in conjunction with EKS Anywhere.
SageMaker offers a native approach for workflow orchestration, known as SageMaker Pipelines.. It is ideal for advanced SageMaker users, especially those who are already onboarded to the IDE SageMaker Studio. The Studio also offers a UI to visual workflows built with SageMaker Pipelines. Apache Airflow is also a compelling option for ML workflow orchestration.
Orchestrate Hybrid ML Workloads with Kubeflow and EKS Anywhere
In this example we’re demonstrating training within local on-premises resources and orchestrating it using Kubeflow.


Stage Five: Other Services
Auxiliary services for hybrid ML patterns
AWS Outposts
Outposts is a keyway to enable hybrid experiences within your own data center. Order AWS Outposts, and Amazon will ship, install, and manage these resources for you. You can connect into these resources however you prefer and manage them from the cloud.
Outposts helps solve cases where customers want to build applications in countries where there is not currently an AWS Region, or for regulations that have strict data residency requirements, like online gambling and sports betting.
AWS Inferentia
A compelling reason to consider deploying your ML models in the cloud is the ease of accessing custom hardware for ML inferencing, specifically AWS Inferentia. You can use SageMaker’s managed deep learning containers to train your ML models, compile them for Inferentia with Neo, host on the cloud, and develop retrain and tune pipeline as usual. Using AWS Inferentia, Alexa was able to reduce their cost of hosting by 25%.
AWS Direct Connect
Ability to establish a private connection between your on-premises resources and your data center. Remember to establish a redundant link, as wires do go south!
Amazon ECS / EKS Anywhere
Both Amazon ECS and Amazon EKS feature “Anywhere” capabilities. This means that you can use the cloud as your control plane, to define, manage, and monitor your deployed applications, while executing tasks both in the Region and on-premises. The customers can use ECS Anywhere to deploy their models both in the cloud and on-premises at the same point in time!
The Final Stage: Use Cases
*Hybrid ML Use Cases *
Enterprise Migrations
One of the single most common use cases for hybrid patterns is enterprise migrations. For some of the largest and oldest organizations on the planet, without a doubt there is going to be a difference in ability and availability in moving towards the cloud across their teams.
Manufacturing
Applications within agriculture, industrial, and manufacturing are ripe opportunities for hybrid ML. After companies have invested tens, and sometimes hundreds, of thousands of dollars in advanced machinery, it is simply a matter of prudence to develop and monitor ML models to predict the health of that machinery.
Gaming
Customers who build gaming applications may see the value in adopting advanced ML services like Amazon SageMaker to raise the bar on their ML-applications but struggle to realize this if their entire platform was build and is currently hosted on premises. The AWS global delivery network to minimize end-user latency.
Mobile application development
With the introduction of AWS Wavelength, customers can deploy ML models directly inside of the 5G network. To solve applications such as anticipated network drop-off or hosting ML models in the cloud for real-time inferencing with 5G customers, you can use ML models hosted on ECS to deploy and monitor models onto AWS Wavelength. This becomes a hybrid pattern when customers develop and train in a secondary environment, wherever that may be, with the intention to deploy onto AWS Wave.
AI-enhanced media and content creation
Customers can host these billion-plus parameter models via ECS on AWS Local Zones, responding to application requests coming from on-premises data centers, to provide world-class experiences to content creators.
Depending on where customers develop and retrain their models, using Local Zones with SOTA models may or may not be a true hybrid pattern, but used effectively it can enhance content generator’s productivity and ability to create.
Autonomous Vehicles
Customers who develop autonomous machinery, vehicles, or robots in multiple capacity by default require hybrid solutions. This is because while training can happen anywhere, inference must necessarily happen at the edge.
Amazon SageMaker Neo is a compelling option here. Key questions for hybrid ML AV architectures include monitoring at the edge, retraining and retuning pipelines, in addition to efficient and automatic data labelling.
Conclusion
In this document, we explored hybrid ML patterns across the entire ML lifecycle. We looked at developing locally, while training and deploying in the cloud. We discussed patterns for training locally to deploy on the cloud, and even to host ML models in the cloud to serve applications on-premises.
At the end of the day, we want to support customer success in all shapes and forms. We firmly believe that most workloads will end in the cloud in the long run, but because the complexity, magnitude, and length of enterprise migrations may be daunting for some of the oldest organizations in the world, we propose these hybrid ML patterns as an intermediate step on customer’s cloud journey.
References:
- If you are interested in learning how to migrate from local HDFS clusters to Amazon EMR, please see this migration guide: https://d1.awsstatic.com/whitepapers/amazon_emr_migration_guide.pdf
- Original AWS Whitepaper
Posted on November 13, 2021
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related