AWS open source newsletter, #186

Ricardo Sueiras
Posted on January 29, 2024
Edition #186
Welcome to issue #186 of the AWS open source newsletter, the newsletter where we try and provide you the best open source on AWS content.
As always, this week we start with a round up of some freshly baked new projects for you to practice your four freedoms. This week we have dashboards to help you cut through the noise when reviewing security information, a synthetic data generator that leverages generative AI, a tool to help you mask data from production so you can use it in development and testing, a solution to help you run VSCode on EC2, a tool to help you wipe your S3 Glacier data vaults, and an assortment of generative AI demos for you to try out. This lot should keep you all very busy.
Swiftly following we have a selection of choice open source content from the AWS community, which this week features projects including Kubernetes, git-sync, devpod, LangChain, OpenSearch, Prometheus, Streamlit, AWS Amplify, OpenShift, Apache Iceberg, Apache Hudi, Delta Lake, MySQL, PostgreSQL, Grafana, Powertools for Lambda, Apache Cassandra, AWS CDK, Amazon Corretto, and more!
When I was small I was always told to never skip my vegetables, so heed this excellent advice and do not skip the Events section at the end! I have added a new link to a repo that lists open source events that are coming up in 2024, which is well worth checking out.
Feedback
Please please please take 1 minute to complete this short survey.
Celebrating open source contributors
The articles and projects shared in this newsletter are only possible thanks to the many contributors in open source. I would like to shout out and thank those folks who really do power open source and enable us all to learn and build on top of what they have created.
So thank you to the following open source heroes: Ajay Dhungel, Mike Likes Robots, Adil Ansari, Alex Parra, Abhishek Gupta, Pathik Shah, Raj Devnath, Prateek Shahane, Luis Lopez, Rajneesh Tyagi, Arnav Mediratta, Leah Tucker, Pahud Hsieh, Adam Keller, Adam Bien, Samuel Baruffi, Vivek Singh, Garry Knox, Vikas Gupta, Sai Parthasaradhi, Tejaswi Nemani, Christian Nwamba, Anton Aleksandrov, Kevin Shaw, and Shridhar Pandey
Latest open source projects
The great thing about open source projects is that you can review the source code. If you like the look of these projects, make sure you that take a look at the code, and if it is useful to you, get in touch with the maintainer to provide feedback, suggestions or even submit a contribution. The projects mentioned here do not represent any formal recommendation or endorsement, I am just sharing for greater awareness as I think they look useful and interesting!
Tools
aws-waf-for-event-analysis-dashboard
aws-waf-for-event-analysis-dashboard finding the information you need during security incidents is what this project aims to help with. During major online events like live broadcasts, security teams need a fast and clear understanding of attack patterns and behaviours to distinguish between normal and malicious traffic flows. The solution outlined here allows filtering flow logs by "Client IP", "URI", "Header name", and "Header value" to analyse these fields and pinpoint values specifically associated with attack traffic versus normal traffic. For example, the dashboard can identify the top header values that are atypical for normal usage. The security team can then create an AWS WAF rule to block requests containing these header values, stopping the attack. This project demonstrates using AWS Glue crawlers to categorise and structure WAF flow log data and Amazon Athena for querying. Amazon Quicksight is then employed to visualise query results in a dashboard. Once deployed, the dashboard provides traffic visualisation similar to the example graphs shown in Images folder in under project , empowering security teams with insight into attacks and defence.
amazon-bedrock-synthetic-manufacturing-data-generator
amazon-bedrock-synthetic-manufacturing-data-generator is a industry aligned synthetic data generation solution. Manufacturing processes generate large amounts of sensor data that can be used for analytics and machine learning models. However, this data may contain sensitive or proprietary information that cannot be shared openly. Synthetic data allows the distribution of realistic example datasets that preserve the statistical properties and relationships in the real data, without exposing confidential information. This enables more open research and benchmarking on representative data. Additionally, synthetic data can augment real datasets to provide more training examples for machine learning algorithms to generalize better. Data augmentation with synthetic manufacturing data can help improve model accuracy and robustness. Overall, synthetic data enables sharing, research, and expanded applications of AI in manufacturing while protecting data privacy and security.
vscode-on-ec2-for-prototyping
vscode-on-ec2-for-prototyping This repository introduces how to access and use VSCode hosted on EC2 from a browser. The connection is made via Session Manager, so IAM permissions are used for authentication. The access destination will be localhost. Please note that this repository does not introduce connecting from your local VSCode to an EC2 instance via Remote SSH.
tokenizing-db-data-tool
tokenizing-db-data-tool provides a handy solution to help you address challenges around masking and keeping safe private or sensitive data (PII), as you need to move data from production to non production systems for activities like testing, debugging, load and integration tests, and more.

amazon-s3-glacier-archive-data-delete
amazon-s3-glacier-archive-data-delete Amazon S3 Glacier Archive (data) Delete solution provides an automated workflow to delete ALL of your data in an S3 Glacier Vault. This solution only applies to Amazon S3 Glacier Vault Archives. Within S3 Glacier, data is stored as an Archive within a Vault. This solution does not apply to objects in Glacier Deep Archive, Glacier Flexible Retrieval, and Glacier Instant Retrieval stored in an Amazon S3 Bucket. Good README with clear guidance and overview of how this works.

aws-cdk-python-for-amazon-mwaa
aws-cdk-python-for-amazon-mwaa this repo provides python code and uses AWS CDK to help you automate the deployment and configuration of Managed Workflows for Apache Airflow (MWAA). I have shared my own repos to help you do this, but you can never have enough of a good thing, so check out this repo and see if it is useful.
Demos, Samples, Solutions and Workshops
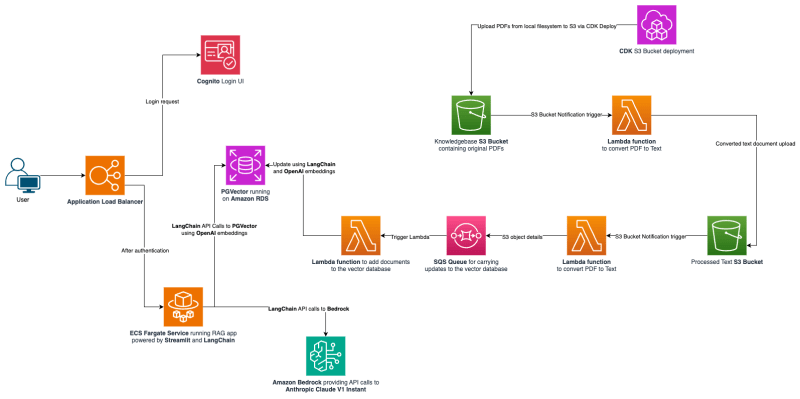
rag-with-amazon-bedrock-and-pgvector
rag-with-amazon-bedrock-and-pgvector is an opinionated sample repo on how to configure and deploy RAG (Retrieval Augmented Retrieval) application. It uses a number of components including Amazon Bedrock for foundational models, Amazon RDS PostgreSQL with pgvector, LangChain, Streamlit, and a number of AWS services to bring it all together.
amazon-sagemaker-pipeline-deploy-manage-100x-models-python-cdk
amazon-sagemaker-pipeline-deploy-manage-100x-models-python-cdk This GitHub repository showcases the implementation of a comprehensive end-to-end MLOps pipeline using Amazon SageMaker pipelines to deploy and manage 100x machine learning models. The pipeline covers data pre-processing, model training/re-training, hyper-parameter tuning, data quality check, model quality check, model registry, and model deployment. Automation of the MLOps pipeline is achieved through Continuous Integration and Continuous Deployment (CI/CD). Machine learning model for this sample code is SageMaker built-in XGBoost algorithm.

bedrock-genai-workshop
bedrock-genai-workshop if you are looking to get hands on with generative AI, then check out this workshop that is aimed at developers and solution builders, introduces how to leverage foundation models (FMs) through Amazon Bedrock. Amazon Bedrock is a fully managed service that provides access to FMs from third-party providers and Amazon; available via an API. With Bedrock, you can choose from a variety of models to find the one that’s best suited for your use case. Within this series of labs, you'll explore some of the most common usage patterns, and Labs include: 1/ Text Generation, 2/ Text Summarization, 3/ Questions Answering, 4/ Chatbot , and 5/ Agent
AWS and Community blog posts
The best from around the Community
We start this week like previous week, by exploring and selecting interesting posts that I found from around the AWS community. (As an aside, if you have content you want me to include, then drop me a DM and share your goodies and I will be sure to check them out). So starting this week we have AWS Community Builder Ajay Dhungel
who shows how you can use git-sync (a very nice open source tool I have been using for years to sync changes in a git repo) to build a really nice automated deployment for CloudFormation templates. Well worth checking out as I did not know you could do this, so if this has intrigued you, go read Git Sync for Seamless Infrastructure Source-to-Live Integration. Next up we have Mike, who likes Robots. He really likes them. In fact, he likes them so much, he now goes by the name Mike Likes Robots (ok, maybe that bit I am not completely sure about!) Mike has put together a post that shows how to deploy applications that use public or private ECR-hosted Docker images, built into AWS IoT Greengrass custom components. AWS IoT Greengrass components are software modules that you deploy to Greengrass core devices that can represent applications, runtime installers, libraries, or any code that you would run on a device. If this is something you are exploring, then go read Deploying Docker Compose with Greengrass!.
Keeping secrets is always challenging, but AWS Community Builder Adil Ansari provides words that will help in the post, Fetch AWS Secrets in Your Kubernetes Realm
. Read it and learn how to effortlessly store secrets in AWS Secret Manager and access them within your Kubernetes resources via external-secrets. More Kubernetes goodness next with Create a devpod K8S custom provider for EKS from Alex Parra. Alex walks you through the deploy process of a devpod in Amazon EKS, covering custom pod manifest setup, devcontainer integration, and other essential configurations you need. Good stuff. Finishing up this weeks community round up we have my good friend Abhishek Gupta who is all over generative AI and LangChain at the moment, and has put together Build a Serverless GenAI solution with Lambda, DynamoDB, LangChain and Amazon Bedrock. Carrying on from a previous post, in this post he shows you how you can use DynamoDB as a chat history backend for your AI chat apps.
OpenSearch and Prometheus
If you are developing AWS native serverless applications using AWS Lambda, but want to use open source observability tools, then Anton Aleksandrov, Kevin Shaw, and Shridhar Pandey have put together the perfect post for you to linger over. In Integrating the AWS Lambda Telemetry API with Prometheus and OpenSearch, they dive into the details of how the AWS Lambda Telemetry API works and how to integrate it with open source observability and telemetry solutions such as Prometheus and OpenSearch. [hands on]

AWS Amplify
My colleague Christian Nwamba has put together this post, The future of web development: AWS Amplify’s Code First Approach that looks at how AWS Amplify is taking a code-first approach, that looks to put the power in the hands of the developers and enable a seamless developer experience whilst leveraging the power of AWS services. This blog post delves into sources of friction developers often encounter when developing, extending, and shipping apps, and how Amplify solves these challenges. [hands on]
Other posts and quick reads
- Diving into Red Hat OpenShift Service on AWS (ROSA) with Hosted Control Planes (HCP) will help you understand more about what Hosted Control Planes are, and why you might want to use them with our OpenShift clusters [hands on]
- Use Amazon Athena with Spark SQL for your open-source transactional table formats shows you how to use Spark SQL in Amazon Athena notebooks and work with Iceberg, Hudi, and Delta Lake table formats [hands on]
- Amazon RDS Multi-AZ with two readable standbys: Under the hood looks at Amazon Relational Database Service (Amazon RDS) Multi-AZ DB cluster configurations for Amazon RDS for MySQL and Amazon RDS for PostgreSQL database instances [hands on]
- PostgreSQL 11 upgrade strategies for Amazon Aurora PostgreSQL and Amazon RDS for PostgreSQL provides essential help and reading for those of you still on PostgreSQL 11 and looking to migrate soon [hands on]
- Migrate rows with unique constraints to Amazon RDS for PostgreSQL or Amazon Aurora PostgreSQL looks at how unique keys are handled in various database engines and how you can mimic or achieve the source database functionality while migrating to PostgreSQL [hands on]
- Building Observability on Amazon Managed Grafana for 5G O-RAN sites built on EKS-Anywhere will educate you on Open Radio Access Network's (O-RAN) and then show you multiple methods that you can use to monitor all layers of your O-RAN edge sites using Amazon Managed Grafana [hands on]

Quick updates
Kubernetes
Kubernetes version 1.29 introduced several new features and bug fixes, and AWS is excited to announce that you can now use Amazon EKS and Amazon EKS Distro to run Kubernetes version 1.29. Starting today, you can create new EKS clusters using v1.29 and upgrade your existing clusters to v1.29 using the Amazon EKS console, the eksctl command line interface, or through an infrastructure-as-code tool.
Some things to note in this release are the removal of v1beta2 flow control API group and the general availability of ReadWriteOncePods access mode for PersistentVolumes. If you create a pod that uses a PresistentVolumeClaim(PVC) using ReadWriteOncePod access mode, only that pod from your whole cluster can read or write to the PVC. Additionally, to reduce the potential attack surface, the release includes the LegacyServiceAccountTokenCleanUp feature that will label legacy auto-generated secret-based tokens as invalid and automatically removes them if not used for one year after being marked as invalid. For detailed information on major changes in Kubernetes v1.29, see the Amazon EKS blog post and the Kubernetes project release notes.
To dive deeper, make sure you check out Arnav Mediratta and Leah Tucker's post, Amazon EKS now supports Kubernetes version 1.29.
Powertools for Lambda
Incase you missed it, v2.32.0 introducedtwo significant new features in the Idempotency utility: Support for Redis as an Idempotency persistent storage layer, and DynamoDB storage layer is now faster and cheaper by leveraging conditional writes. Check out the link for more details of these, as well as the many changes, maintenance updates, and documentation updates. Am I the only one who loves the fact that doc updates are featured in the release notes...
PostgreSQL
Trusted Language Extensions for PostgreSQL (pg_tle) now supports new crates for PL/Rust such as croaring-rs and num-bigint, enabling you to build more of your extensions on RDS for PostgreSQL. PL/Rust, a PostgreSQL trusted procedural language, combines the performance and resource efficiency of compiled languages like C and provides memory safety so that an unprivileged user can run code in the database.
Rust crates extend functionality in PL/Rust to help support more use cases such as for analytics, search, and security applications. croaring-rs adds support for roaring bitmap, a data type that provides better compression and lower memory utilisation compared to conventional bitmaps. Roaring bitamps are used for applications that require high performance lookups with a high compression ratio, such as analytics and big data. The num-bigint crate adds precision handling for arbitrarily large sized integers, which is used for security and scientific applications.
pg_tle is an open source development kit to help you build extensions written in a trusted language, such as PL/Rust, that run safely on PostgreSQL. Support for num-bigint and croaring-rs crates is available on database instances in Amazon RDS running PostgreSQL 16.1-R2 and higher, 15.5-R2 and higher, 14.10-R2 and higher, and 13.13-R2 and higher in all applicable AWS Regions.
Apache Cassandra
Amazon Keyspaces (for Apache Cassandra) is a scalable, serverless, highly available, and fully managed Apache Cassandra-compatible database service that offers 99.999% availability. Amazon Keyspaces now supports provisioned capacity mode for Multi-Region Replication tables. With provisioned mode, you can specify the number of reads and writes per second that you need for your application. You can also use auto scaling with provisioned mode to automatically adjust your table’s capacity based on the specified utilisation rate to ensure application performance while reducing costs. Provisioned mode is most cost-effective for workloads with stable and predictable load.
Videos of the week
Simplifying Cross Account Deployments with the AWS CDK
Recorded live last week, Pahud Hsieh and Adam Keller walk through how users can deploy to multiple accounts with the AWS CDK. Check out the other videos too, as there is a lot of great content on this channel.
Bootstrapping Clusters with EKS Blueprints
Samuel Baruffi provides a look at EKS Blueprints, and how these can help you leverage best practices for deploying your Kubernetes infrastructure. Recorded from Conf42 DevOps 2024, this video has plenty of knowledge and hands on demo to keep you interested.
Dissecting Serverless Java on AWS
Recorded at CodeEurope 2023, Adam Bien takes a deep dive on cloud native Java, including plenty of hands on examples and code that answer many of the questions you might have, and deploy the examples to the cloud in real-time using Infrastructure as (Java) Code (IaC).
Events for your diary
If you are planning any events in 2024, either virtual, in person, or hybrid, get in touch as I would love to share details of your event with readers.
I recently found this GitHub repo, open-source-events that is a curated set of open source events for 2024. Go check it out and see what 2024 is looking like.
FOSDEM
Brussels, Belgium 3rd and 4th February, 2024
FOSDEM is a free event for software developers to meet, share ideas and collaborate. Every year, thousands of developers of free and open source software from all over the world gather at the event in Brussels. There are plenty of folks from AWS that will be there, so drop me a DM if you are going and want to meet up. You don't need to register. Just turn up and join in!
Find out more by heading to the site home page, FOSDEM 24
SOOCon 24
London, UK 7th and 8th February, 2024
The State of Open Conference is back in the new year, and what better opportunity to combine with your trip to Fosdem, than come along to the wonderful Brewery in the City of London and catch up with the hundreds of open source developers, enthusiasts, hackers, and more. Check out the event page, and if you are so inclined, there is still chance to submit a talk as the call for papers (cfp) is open until the 15th of December.
You can view more at the site page, SOOCon24
Cortex
Every other Thursday, next one 16th February
The Cortex community call happens every two weeks on Thursday, alternating at 1200 UTC and 1700 UTC. You can check out the GitHub project for more details, go to the Community Meetings section. The community calls keep a rolling doc of previous meetings, so you can catch up on the previous discussions. Check the Cortex Community Meetings Notes for more info.
OpenSearch
Every other Tuesday, 3pm GMT
This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.
Sign up to the next session, OpenSearch Community Meeting
Stay in touch with open source at AWS
Remember to check out the Open Source homepage for more open source goodness.
One of the pieces of feedback I received in 2023 was to create a repo where all the projects featured in this newsletter are listed. Where I can hear you all ask? Well as you ask so nicely, you can meander over to newsletter-oss-projects.
Made with ♥ from DevRel
Posted on January 29, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related
